













Was ist Elasticsearch?
Elasticsearch ist eine verteilte, Open-Source-Such- und Analyse-Engine, die auf der Apache Lucene Bibliothek aufbaut. Elasticsearch bietet auch Vektorsuche und retrieval augmented generation (RAG) und unterstützt moderne KI-Anwendungen nahtlos. Anwendungen können strukturierte und unstrukturierte Daten in Elasticsearch speichern, mit oder ohne ein definiertes Schema, indem sie JSON Payloads an einen Elasticsearch-Cluster senden.
Elasticsearch-Architektur
Von Grund auf sind die Hauptkomponenten eines Elasticsearch-Clusters:
Dokument
Ein Dokument ist der kleinste Informationsdatensatz, der von Elasticsearch gespeichert wird und wird als JSON dargestellt. Ein Dokument besteht aus mehreren Feldern (Schlüssel-Wert-Paaren) unterschiedlicher Typen und kann ein vordefiniertes Schema haben oder schemafrei sein, wobei die Datentypen neuer indizierter Felder abgeleitet werden.
Index
Ein Index ist eine logische Sammlung von Dokumenten mit demselben Schema, identifiziert durch einen Indexnamen.
Shard
Elasticsearch-Indizes werden in handhabbare Einheiten namens Shards aufgeteilt, die eine Sammlung von Dokumenten sind. Shards sind die grundlegende Einheit der Suche und werden über mehrere Knoten hinweg repliziert, um Redundanz und Fehlertoleranz zu gewährleisten.
Knoten
Ein Knoten ist eine unabhängige Instanz von Elasticsearch und verwaltet eine Sammlung von Shards, die zu einem oder mehreren Indizes gehören. Knoten können unterschiedliche Rollen wie Datenknoten, Masterknoten und Ingest-Knoten haben.
Cluster
Ein Elasticsearch-Cluster ist eine Sammlung von miteinander verbundenen Knoten. Alle Knoten in einem Cluster können Anfragen von Clients bearbeiten und kommunizieren miteinander. Jeder Knoten in einem Cluster besitzt eine Teilmenge der Shards, die zu einem Index gehören.
Abfragearchitektur
Das folgende Architekturdiagramm skizziert den Ablauf einer Suchanfrage:

- Der Benutzer oder die Anwendung stellt eine Suchanfrage. Die Anfrage kann von jedem Knoten im Cluster bearbeitet werden. Der Knoten, der die Anfrage bearbeitet, ist der „koordinierende“ Knoten.
- Der koordinierende Knoten sendet die Anfrage an alle beteiligten Shards und deren Replikate.
- Jeder Shard führt die Anfrage lokal aus und gibt eine leichte Ergebnismenge an den koordinierenden Knoten zurück.
- Der koordinierende Knoten fügt die Ergebnisse, die er erhält, zusammen. Dies ist das Ende der „Abfrage“-Phase. Die Abfragephase identifiziert die grundlegendsten Dokumente, die das Suchergebnis bilden, aber das vollständige Dokument muss noch abgerufen werden.
- Der koordinierende Knoten sendet Abrufanfragen an die besitzenden Shards, die die Dokumente im Ergebnissatz anreichern.
- Die angereicherten Dokumente werden an den koordinierenden Knoten zurückgegeben.
- Das vollständige Set an Suchergebnissen, gewichtet und angereichert, wird an den Anrufer zurückgegeben.
Indexierungsarchitektur
Das folgende Architekturdiagramm skizziert den Ablauf einer Indexierungsanfrage:
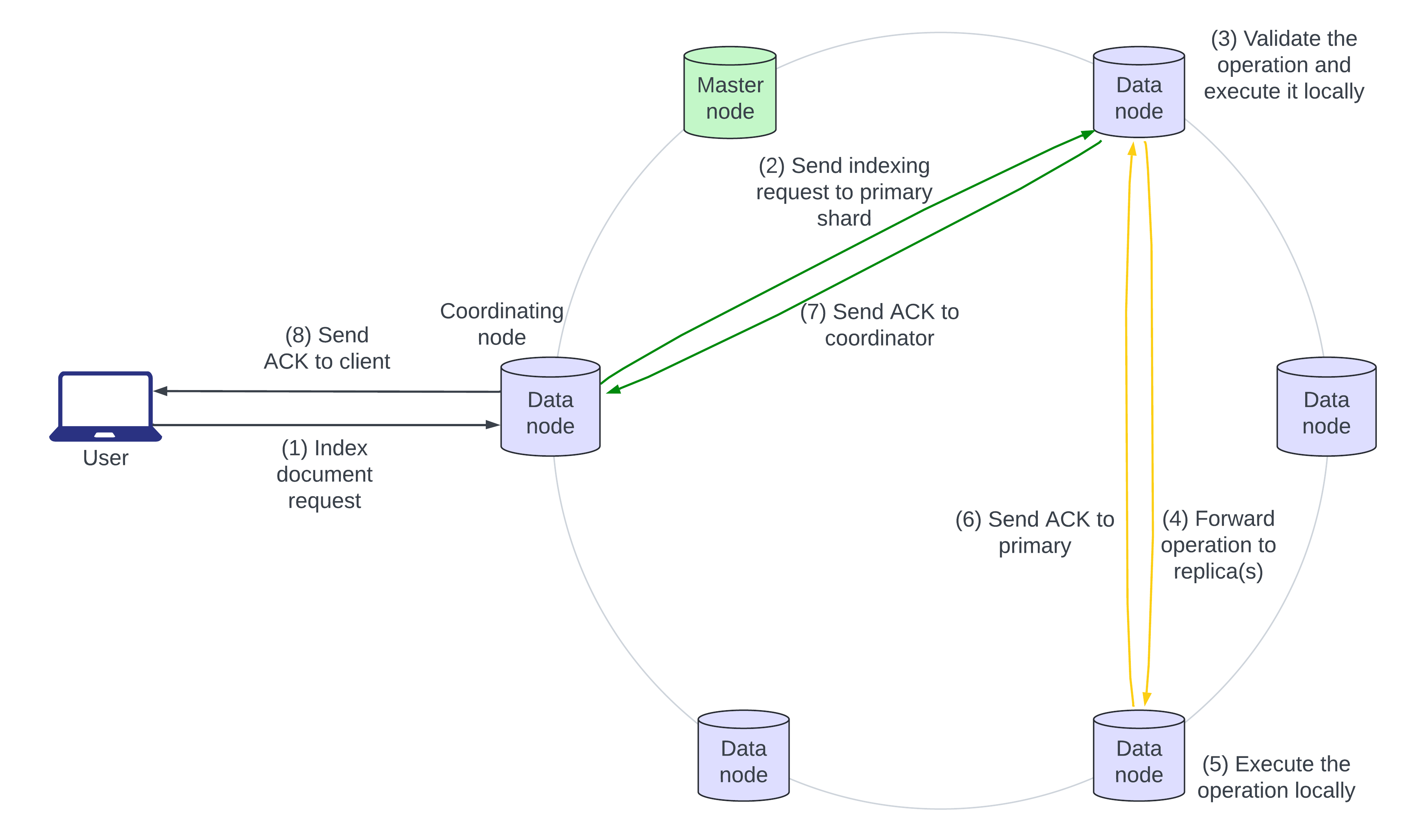
- Der Benutzer sendet ein JSON-Dokument zur Indexierung an Elasticsearch. Wenn das Dokument bereits existiert, werden neue Felder hinzugefügt und vorhandene Felder überschrieben. Der Knoten, der die Anfrage zuerst empfängt, ist der „koordinierende“ Knoten.
- Der Koordinierungsknoten identifiziert den primären Shard des eingehenden Dokuments, normalerweise basierend auf der Dokumenten-ID, und leitet die Anfrage an den Datenspeicherknoten weiter, der den primären Shard besitzt.
- Der primäre Shard validiert die Operation und führt sie lokal aus.
- Der primäre Shard leitet die Operation dann parallel an alle seine Replikate weiter.
- Die Replikatshards wenden die Operation lokal auf ihren Knoten an.
- Schritte 6, 7 und 8 zeigen die Bestätigung des Schreibvorgangs, der vom Replikatshard zum primären Shard, zum koordinierenden Knoten und zum Aufrufer hochgeleitet wird.
Zusammenfassung
Dieser Artikel beschreibt die verschiedenen Komponenten eines Elasticsearch-Clusters: Dokumente, Indizes, Shards und Knoten. Er skizziert auch die Lebensdauer einer Suchanfrage und einer Indexierungsanfrage. Durch seine flexible Architektur ist es einfach, Knoten hinzuzufügen und zu entfernen, während der Cluster wächst. In Kombination mit Funktionen wie schemaloser Indexierung und Unterstützung für KI-Suchfunktionen macht dies Elasticsearch zum Standard für Organisationen, die große Datenmengen in Echtzeit effizient speichern, durchsuchen und analysieren müssen.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture