













Datenbanksharding ist der Prozess der Aufteilung von Daten in kleinere Teile, die als „Shard“ bezeichnet werden. Sharding wird typischerweise eingeführt, wenn es notwendig wird, Schreibvorgänge zu skalieren. Im Laufe des Lebenszyklus einer erfolgreichen Anwendung erreicht der Datenbankserver entweder auf der Verarbeitungs- oder Kapazitätsebene die maximal erreichbare Anzahl von Schreibvorgängen. Das Schneiden der Daten in mehrere Shards – jeweils auf einem eigenen Datenbankserver – reduziert die Belastung jedes einzelnen Knotens und erhöht effektiv die Schreibkapazität des gesamten Datenbanksystems. Das ist der Kern von Datenbanksharding.
Verteilte SQL ist die neue Methode zur Skalierung relationaler Datenbanken mit einer sharding-ähnlichen Strategie, die vollautomatisiert und für Anwendungen transparent ist. Verteilte SQL-Datenbanken sind von Grund auf für nahezu lineare Skalierung entwickelt. In diesem Artikel erfahren Sie die Grundlagen von verteiltem SQL und wie Sie beginnen können.
Nachteile des Datenbanksharding
Sharding bringt eine Reihe von Herausforderungen mit sich:
- Datenpartitionierung: Die Entscheidung, wie Daten über mehrere Shards aufgeteilt werden, kann eine Herausforderung darstellen, da es darum geht, einen Ausgleich zwischen Datennähe und gleichmäßiger Verteilung der Daten zu finden, um Hotspots zu vermeiden.
- Fehlerbehandlung: Wenn ein Schlüsselknoten ausfällt und es nicht genügend Shards gibt, um die Last zu tragen, wie kann man die Daten ohne Ausfallzeit auf einen neuen Knoten bringen?
- Abfragekomplexität: Anwendungscode ist an die Datenaufteilungslogik gekoppelt und Abfragen, die Daten von mehreren Knoten benötigen, müssen neu zusammengeführt werden.
- Datenkonsistenz: Die Sicherstellung der Datenkonsistenz über mehrere Shards hinweg kann eine Herausforderung darstellen, da es erforderlich ist, Updates über die Shards hinweg zu koordinieren. Dies kann besonders schwierig sein, wenn Updates gleichzeitig erfolgen, da möglicherweise Konflikte zwischen verschiedenen Schreibvorgängen aufgelöst werden müssen.
- Elastische Skalierbarkeit: Bei zunehmendem Datenvolumen oder Anzahl der Abfragen kann es notwendig sein, dem Datenbank hinzuzufügen zusätzliche Shards. Dies kann ein komplexer Prozess mit unvermeidlicher Ausfallzeit sein, der manuelle Prozesse erfordert, um Daten gleichmäßig über alle Shards zu verteilen.
Einige dieser Nachteile können durch die Übernahme von Polyglot-Persistence (Verwendung verschiedener Datenbanken für verschiedene Workloads), Datenbank Speicherengines mit nativen Sharding-Fähigkeiten oder Datenbank-Proxys abgemildert werden. Allerdings helfen diese Werkzeuge zwar bei einigen der Herausforderungen bei der Datenbanksharding, haben jedoch Einschränkungen und führen eine Komplexität ein, die ständige Verwaltung erfordert.
Was ist verteiltes SQL?
Distributed SQL bezieht sich auf eine neue Generation von relationalen Datenbanken. Einfach ausgedrückt ist eine Distributed SQL-Datenbank eine relationale Datenbank mit transparentem Sharding, die für Anwendungen wie eine einzelne logische Datenbank aussieht. Distributed SQL-Datenbanken werden als shared-nothing Architektur und ein Speichermotor implementiert, der sowohl Lese- als auch Schreibanforderungen skaliert, während sie wahre ACID-Kompatibilität und hohe Verfügbarkeit beibehalten. Distributed SQL-Datenbanken verfügen über die Skalierungsmerkmale von NoSQL-Datenbanken – die in den 2000er Jahren an Popularität gewannen – ohne Konsistenz zu opfern. Sie behalten die Vorteile relationaler Datenbanken bei und fügen Cloud-Kompatibilität mit multiregionalem Widerstandsfähigkeit hinzu.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
Wie funktioniert Distributed SQL?
Um zu verstehen, wie Distributed SQL funktioniert, betrachten wir den Fall von MariaDB Xpand – einer verteilten SQL-Datenbank, die kompatibel ist mit der quelloffenen MariaDB-Datenbank. Xpand arbeitet, indem es die Daten und Indizes auf Knoten aufteilt und automatisch Aufgaben wie Datenumbalancierung und verteilte Abfrageausführung durchführt. Abfragen werden parallel ausgeführt, um Latenz zu minimieren. Daten werden automatisch repliziert, um sicherzustellen, dass es keinen einzelnen Fehlerpunkt gibt. Wenn ein Knoten ausfällt, balanciert Xpand die Daten unter den überlebenden Knoten neu aus. Das gleiche passiert, wenn ein neuer Knoten hinzugefügt wird. Ein Komponente namens Rebalancer stellt sicher, dass es keine Hotspots gibt – eine Herausforderung bei manueller Datenbankshardierung – die auftritt, wenn ein Knoten ungleichmäßig zu viele Transaktionen im Vergleich zu anderen, manchmal ruhenden Knoten, verarbeiten muss.
Schauen wir uns ein Beispiel an. Angenommen, wir haben eine Datenbankinstanz mit some_table und einer Anzahl von Zeilen:
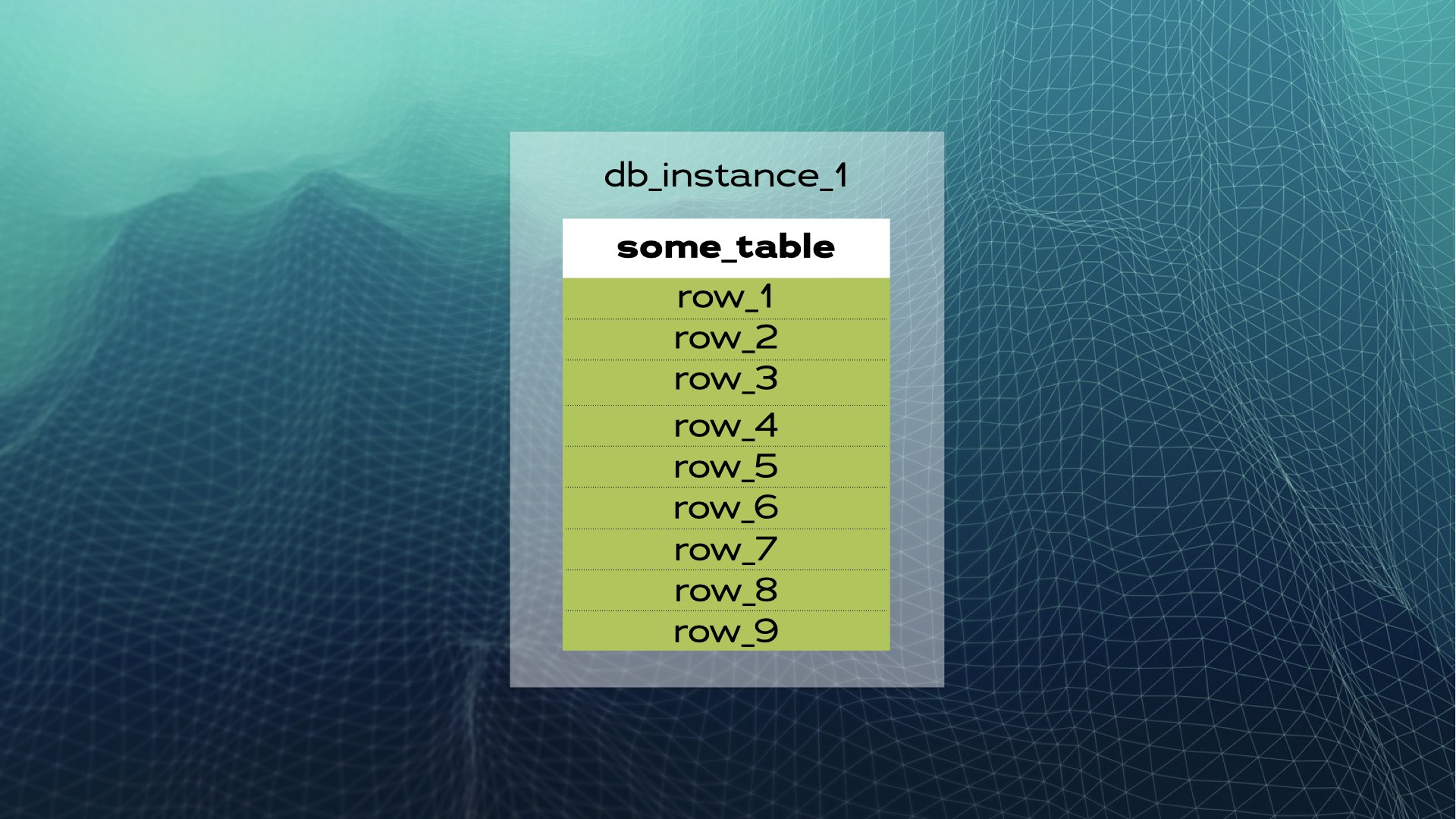
Wir können die Daten in drei Teile (Shard) aufteilen:

Und dann jedes Datenstück in eine separate Datenbankinstanz verschieben:
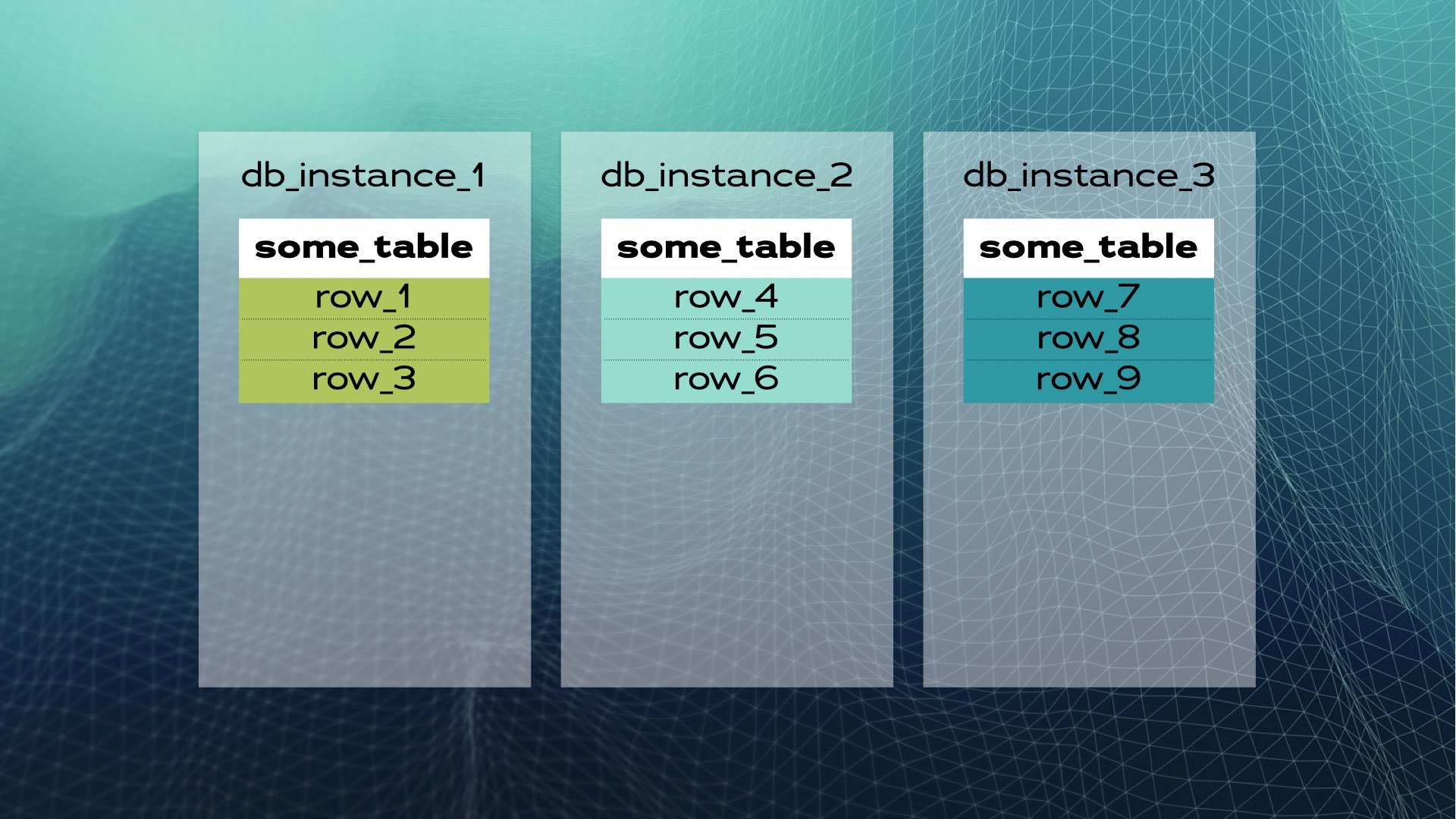
Das ist, wie manuelle Datenbanksicherung aussieht. Verteilte SQL erledigt dies automatisch für Sie. Im Fall von Xpand wird jeder Shard als Slice bezeichnet. Zeilen werden mithilfe einer Hash-Funktion eines Teils der Tabellenspalten geschnitten. Nicht nur Daten werden geschnitten, sondern auch Indizes werden geschnitten und auf die Knoten (Datenbankinstanzen) verteilt. Darüber hinaus werden zur Sicherstellung der hohen Verfügbarkeit Slices auf anderen Knoten repliziert (die Anzahl der Replikate pro Knoten ist konfigurierbar). Dies geschieht ebenfalls automatisch:
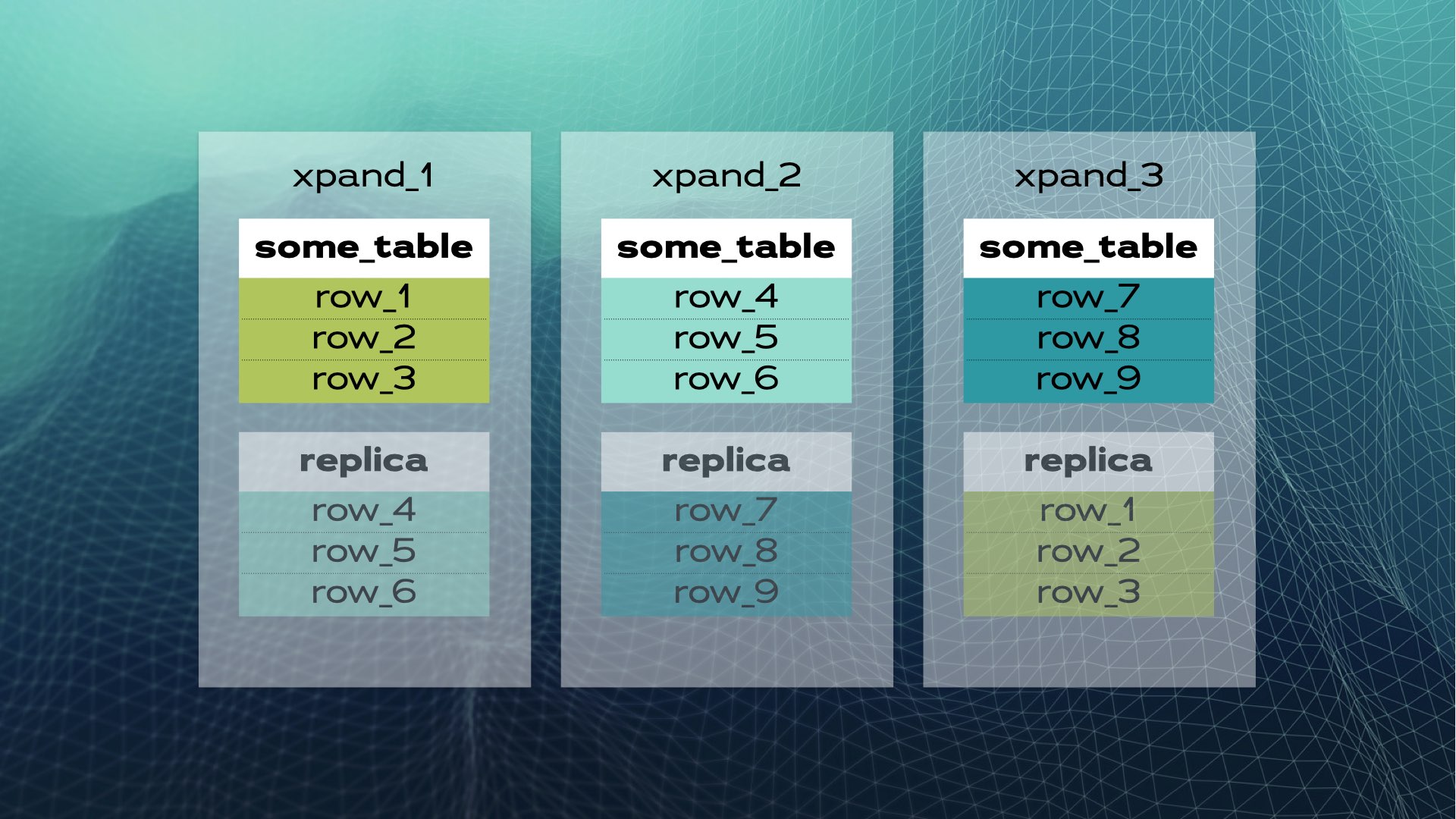
Wenn ein neuer Knoten zum Cluster hinzugefügt wird oder ein Knoten ausfällt, reagiert Xpand automatisch, indem es die Daten umverteilt, ohne dass eine manuelle Intervention erforderlich ist. Hier ist, was passiert, wenn ein Knoten zum vorherigen Cluster hinzugefügt wird:

Einige Zeilen werden auf den neuen Knoten verschoben, um die Gesamtkapazität des Systems zu erhöhen. Denken Sie daran, dass, obwohl im Diagramm nicht gezeigt, sowohl Indizes als auch Replikate ebenfalls umgelagert und entsprechend aktualisiert werden. Ein etwas vollständigerer Blick (mit einer etwas anderen Umlagerung von Daten) auf den vorherigen Cluster wird in diesem Diagramm gezeigt:
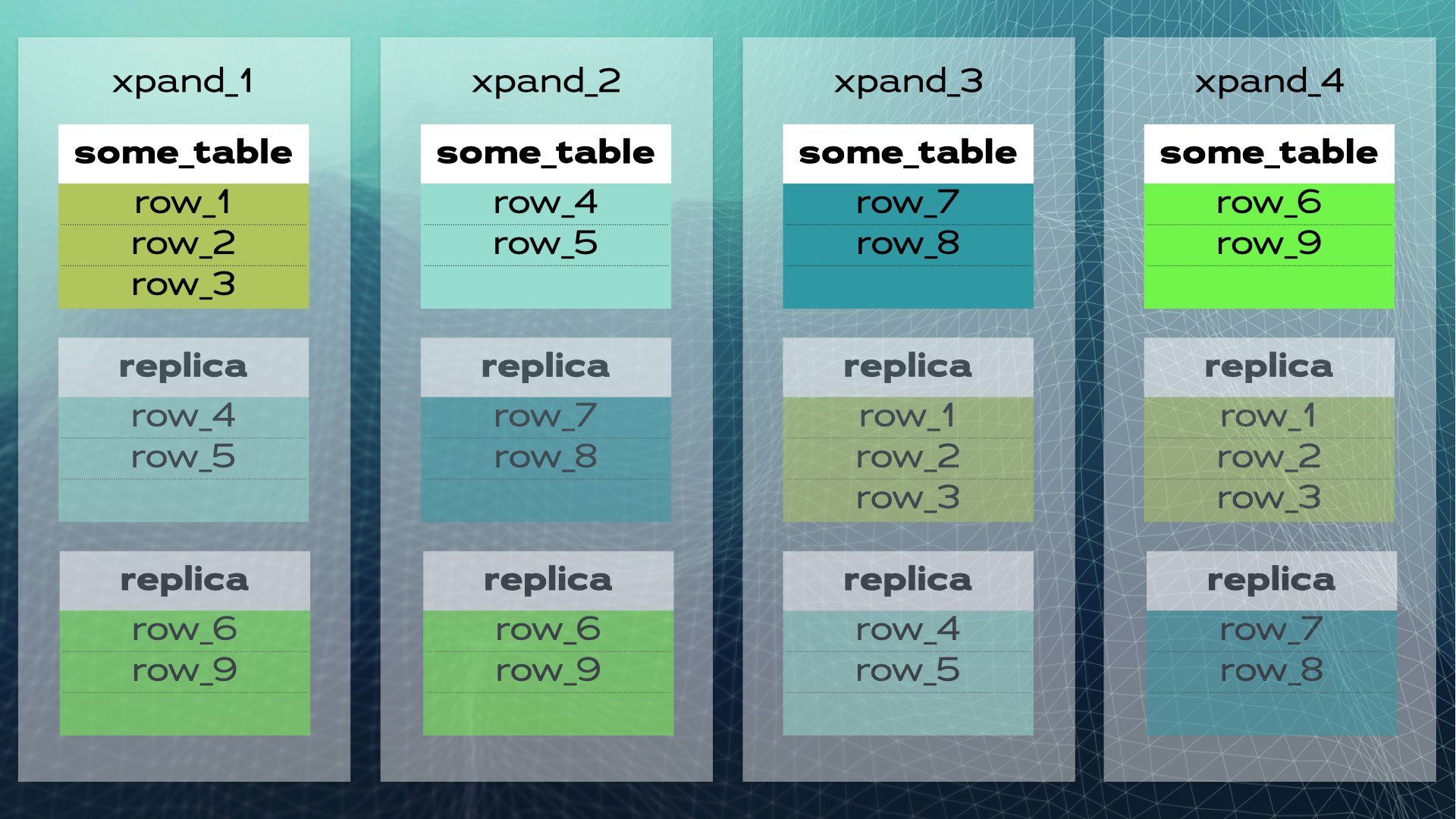
Diese Architektur ermöglicht eine annähernd lineare Skalierbarkeit. Es ist keine manuelle Intervention auf Anwendungsebene erforderlich. Für die Anwendung sieht der Cluster wie eine einzelne logische Datenbank aus. Die Anwendung verbindet sich einfach über einen Lastverteiler (MariaDB MaxScale) mit der Datenbank:
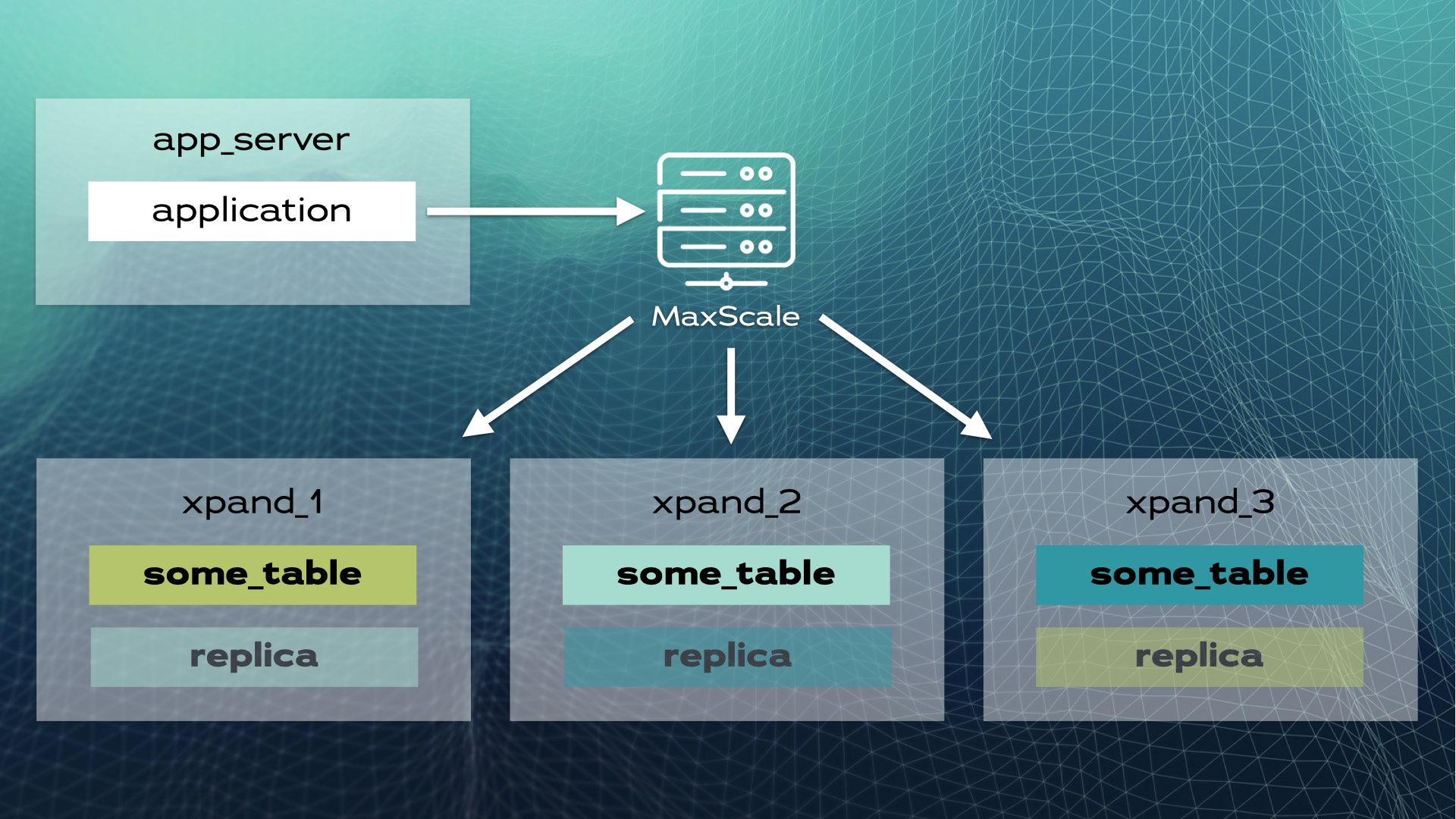
Wenn die Anwendung eine Schreiboperation sendet (zum Beispiel INSERT oder UPDATE), wird der Hash berechnet und an die korrekte Slice gesendet. Mehrere Schreibvorgänge werden parallel an mehrere Knoten gesendet.
Wann nicht auf verteilte SQL zurückzugreifen
Das Sharding eines Datenbanksystems verbessert zwar die Leistung, führt aber auch zu zusätzlichem Overhead auf Kommunikationsebene zwischen den Knoten. Dies kann zu einer verlangsamten Leistung führen, wenn die Datenbank nicht korrekt konfiguriert ist oder der Abfrage-Router nicht optimiert wurde. Verteilte SQL könnte möglicherweise keine geeignete Alternative sein für Anwendungen mit weniger als 10.000 Abfragen pro Sekunde oder 5.000 Transaktionen pro Sekunde. Auch wenn Ihre Datenbank hauptsächlich aus vielen kleinen Tabellen besteht, könnte eine monolithische Datenbank eine bessere Leistung bieten.
Erste Schritte mit verteiltem SQL
Da eine verteilte SQL-Datenbank für eine Anwendung wie eine einzige logische Datenbank aussieht, ist der Einstieg recht einfach. Sie benötigen Folgendes:
- Einen SQL-Client wie DBeaver, DbGate, DataGrip oder eine SQL-Client-Erweiterung für Ihre IDE
- A distributed SQL database
Docker vereinfacht den zweiten Teil. Zum Beispiel veröffentlicht MariaDB das mariadb/xpand-single Docker-Image, das es Ihnen ermöglicht, eine einnodige Xpand-Datenbank für die Bewertung, Tests und Entwicklung zu starten.
Um einen Xpand-Container zu starten, führen Sie den folgenden Befehl aus:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Siehe das Docker-Image Dokumentation für Details.
Hinweis: Zum Zeitpunkt der Erstellung dieses Artikels ist das Docker-Image mariadb/xpand-single für ARM-Architekturen nicht verfügbar. Auf diesen Architekturen (zum Beispiel Apple-Maschinen mit M1-Prozessoren) verwenden Sie UTM zum Erstellen einer virtuellen Maschine (VM) und installieren beispielsweise Debian. Weisen Sie einen Hostnamen zu und verwenden Sie SSH zum Herstellen einer Verbindung zur VM, um Docker zu installieren und den MariaDB Xpand-Container zu erstellen.
Herstellen einer Verbindung zur Datenbank
Das Herstellen einer Verbindung zu einer Xpand-Datenbank entspricht dem Herstellen einer Verbindung zu einem MariaDB Community– oder Enterprise-Server. Wenn Sie das mariadb-CLI-Tool installiert haben, führen Sie einfach Folgendes aus:
mariadb -h 127.0.0.1 -u user -pSie können sich über eine grafische Benutzeroberfläche (GUI) für SQL-Datenbanken wie DBeaver, DataGrip oder eine SQL-Erweiterung für Ihr IDE (wie diese hier für VS Code) mit der Datenbank verbinden. Wir werden einen kostenlosen und quelloffenen SQL-Client namens DbGate verwenden. Sie können DbGate herunterladen und als Desktop-Anwendung ausführen oder, da Sie Docker verwenden, es als Webanwendung bereitstellen, die Sie von überall aus über einen Webbrowser zugänglich machen können (ähnlich dem beliebten phpMyAdmin). Führen Sie einfach den folgenden Befehl aus:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateSobald der Container startet, führen Sie in Ihrem Browser http://localhost:3000/ aus. Geben Sie die Verbindungsdetails ein:
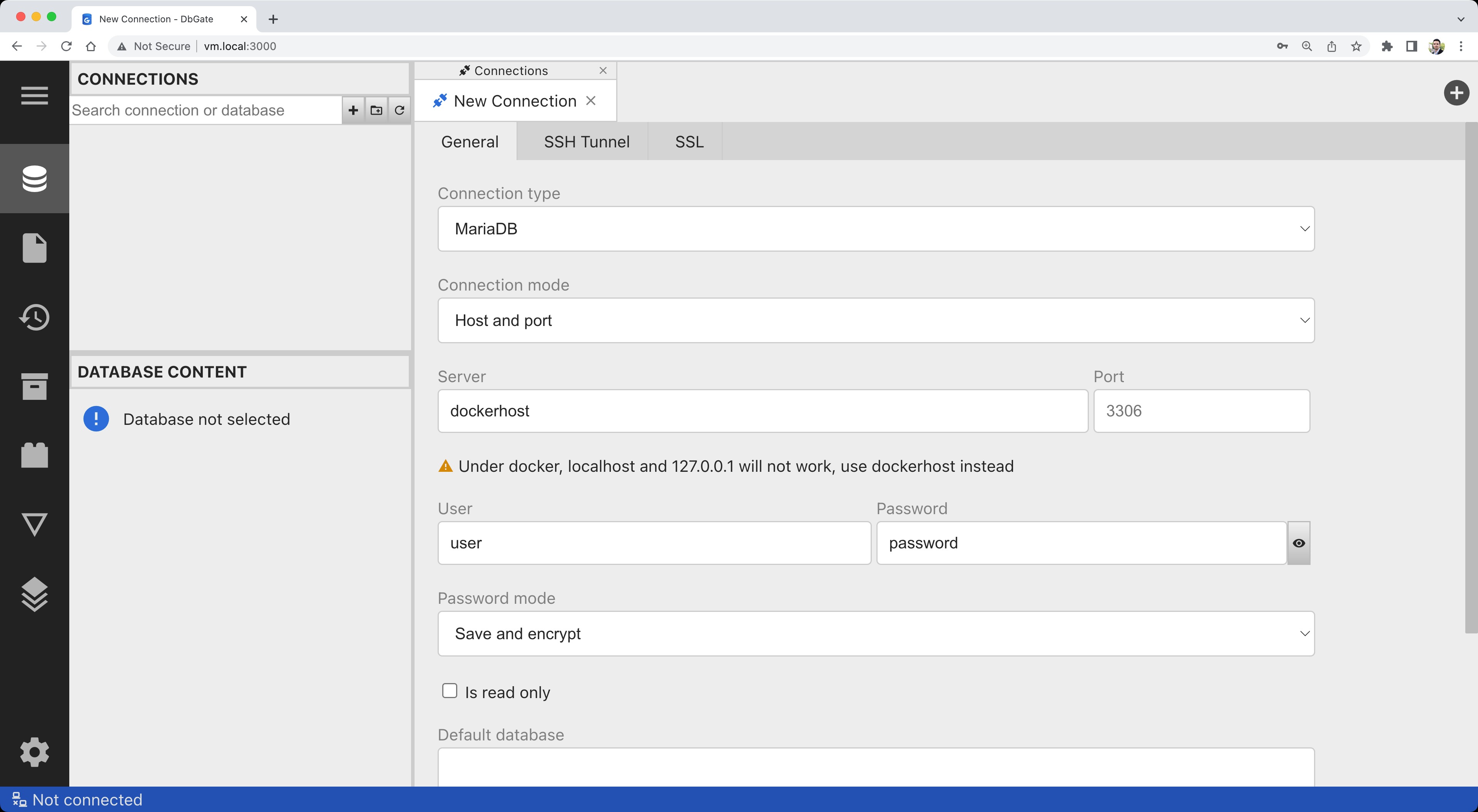
Klicken Sie auf Test und bestätigen Sie, dass die Verbindung erfolgreich ist:

Klicken Sie auf Speichern und erstellen Sie über einen Rechtsklick auf die Verbindung im linken Bereich eine neue Datenbank, indem Sie Datenbank erstellen auswählen. Probieren Sie das Erstellen von Tabellen oder das Importieren eines SQL-Skripts aus. Wenn Sie nur etwas ausprobieren möchten, sind Nation oder Sakila gute Beispieldatenbanken.
Verbinden aus Java, JavaScript, Python und C++
Um eine Verbindung zu Xpand aus Anwendungen herzustellen, können Sie die MariaDB Connectors verwenden. Es gibt viele Kombinationen von Programmiersprachen und Persistenzframeworks. Die Abdeckung dieser Thematik liegt außerhalb des Umfangs dieses Artikels, aber wenn Sie nur anfangen möchten und etwas in Aktion sehen wollen, schauen Sie sich diese Schnellstartseite mit Codebeispielen für Java, JavaScript, Python und C++ an.
Die wahre Macht der verteilten SQL
In diesem Artikel haben wir gelernt, wie man einen einzelnen Xpand-Knoten für Entwicklungs- und Testzwecke startet, im Gegensatz zu Produktionsarbeitslasten. Die wahre Stärke einer verteilten SQL-Datenbank liegt jedoch in ihrer Fähigkeit, nicht nur Lesevorgänge (wie bei klassischer Datenbanksharding) zu skalieren, sondern auch Schreibvorgänge, indem einfach weitere Knoten hinzugefügt und der Rebalancer die Daten optimal umverteilt. Obwohl es möglich ist, Xpand in einer Multi-Node-Topologie zu implementieren, ist der einfachste Weg, es in der Produktion zu verwenden, über SkySQL.
Wenn Sie mehr über verteilte SQL und MariaDB Xpand erfahren möchten, finden Sie hier eine Liste nützlicher Ressourcen:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding