













In Teil 1 dieser Reihe haben wir uns mit MongoDB beschäftigt, einer der zuverlässigsten und robustesten dokumentorientierten NoSQL-Datenbanken. Hier in Teil 2 werden wir uns eine weitere unvermeidliche NoSQL-Datenbank ansehen: Elasticsearch.
Mehr als nur eine beliebte und leistungsstarke quelloffene verteilte NoSQL-Datenbank ist Elasticsearch vor allem eine Such- und Analyse-Engine. Es basiert auf Apache Lucene, der bekanntesten Suchmaschinen-Java-Bibliothek, und kann Echtzeit-Suche und Analyseoperationen an strukturierten und unstrukturierten Daten durchführen. Es ist darauf ausgelegt, große Mengen an Daten effizient zu verarbeiten.
Wir müssen erneut darauf hinweisen, dass dieser kurze Beitrag keinesfalls ein Elasticsearch-Tutorial ist. Der Leser wird daher eindringlich darauf hingewiesen, die offizielle Dokumentation sowie das hervorragende Buch „Elasticsearch in Action“ von Madhusudhan Konda (Manning, 2023) zu nutzen, um mehr über die Architektur und Operationen des Produkts zu erfahren. Hier implementieren wir einfach denselben Use Case wie previously, aber diesmal verwenden wir Elasticsearch anstelle von MongoDB.
Na, dann los!
Das Domänenmodell
Das nachstehende Diagramm zeigt unser *customer-order-product* Domänenmodell:
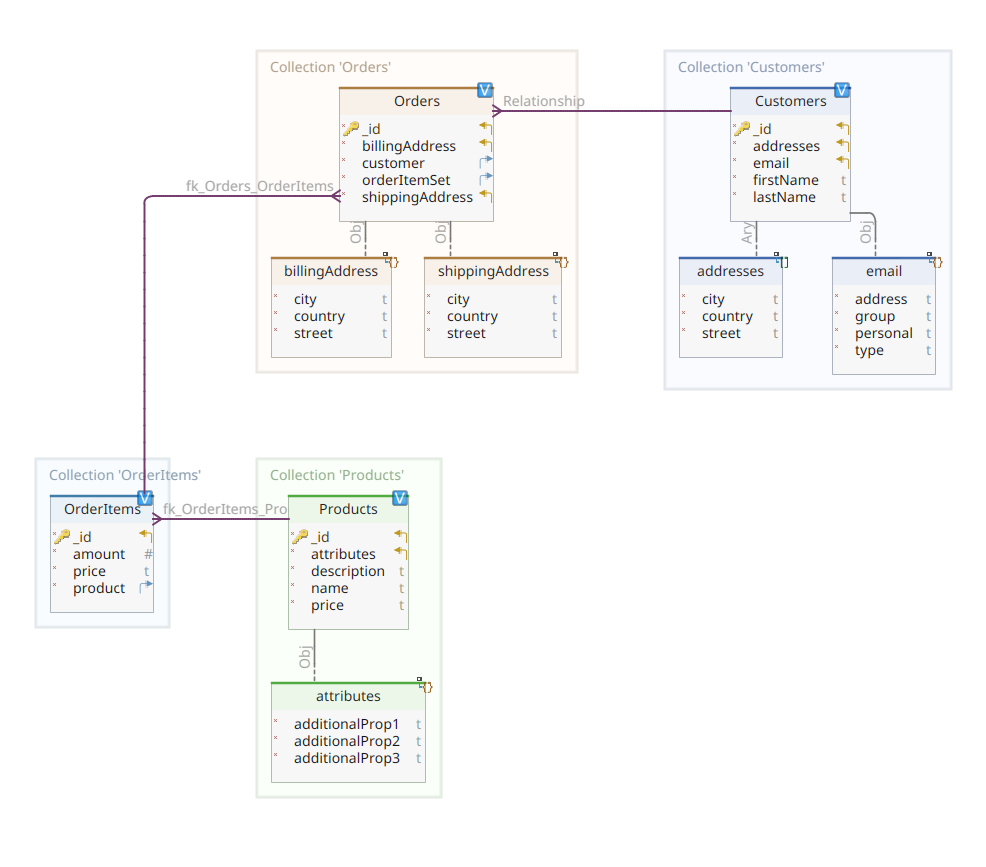
Dieses Diagramm ist dasselbe wie das in Teil 1 vorgestellte. Wie MongoDB ist auch Elasticsearch ein Dokumentendaten Speicher und erwartet daher, dass Dokumente in JSON-Notation präsentiert werden. Der einzige Unterschied ist, dass Elasticsearch zur Verwaltung seiner Daten diese indiziert haben muss.
Es gibt mehrere Möglichkeiten, wie Daten in einem Elasticsearch-Daten Speicher indiziert werden können; zum Beispiel durch das Umleiten von Daten aus einer relationalen Datenbank, das Extrahieren aus einem Dateisystem, das Streamen von Echtzeitquellen usw. Aber egal, welche Methode der Datenimport ist, es besteht letztendlich darin, die Elasticsearch-RESTful-API über einen dedizierten Client aufzurufen. Es gibt zwei Kategorien solcher dedizierter Clients:
- REST-basierte Clients wie
curl,Postman, HTTP-Module für Java, JavaScript, Node.js usw. - Programmiersprachen-SDKs (Software Development Kit): Elasticsearch bietet SDKs für alle am häufigsten verwendeten Programmiersprachen, einschließlich aber nicht beschränkt auf Java, Python usw.
Das Indizieren eines neuen Dokuments mit Elasticsearch bedeutet, es über eine POST-Anfrage gegen einen speziellen RESTful-API-Endpunkt namens _doc zu erstellen. Zum Beispiel wird die folgende Anfrage einen neuen Elasticsearch-Index erstellen und eine neue Kundeninstanz darin speichern.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Die Ausführung der obigen Anfrage mit curl oder der Kibana-Konsole (wie wir später sehen werden) wird das folgende Ergebnis erzeugen:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Dies ist die Standardantwort von Elasticsearch auf eine POST-Anfrage. Sie bestätigt die Erstellung des Indexnamens customers, einen neuen customer-Dokument, das durch eine automatisch generierte ID identifiziert wird (in diesem Fall ZEQsJI4BbwDzNcFB0ubC).
Hier erscheinen andere interessante Parameter wie _version und insbesondere _shards. Ohne zu viel ins Detail zu gehen, erstellt Elasticsearch Indizes als logische Sammlungen von Dokumenten. Genau wie das Aufbewahren von Papierdokumenten in einem Aktenordner, speichert Elasticsearch Dokumente in einem Index. Jeder Index besteht aus Shards, die physische Instanzen von Apache Lucene sind, der Motor im Hintergrund, verantwortlich für das Speichern und Abrufen der Daten. Sie können entweder primär sein, Dokumente speichern, oder Replikate, die, wie der Name vermuten lässt, Kopien der primären Shards speichern. Mehr dazu in der Elasticsearch-Dokumentation – für jetzt müssen wir bemerken, dass unser Index namens customers aus zwei Shards besteht: davon ist natürlich einer primär.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Um zu unserem Domänenmodell-Diagramm zurückzukehren, wie Sie sehen können, ist sein zentrales Dokument Order, das in einer dedizierten Sammlung namens Orders gespeichert ist. Eine Order ist ein Aggregat von OrderItem-Dokumenten, jedes davon verweist auf sein assoziiertes Product. Ein Order-Dokument verweist auch auf den Customer, der sie aufgegeben hat. In Java wird dies wie folgt implementiert:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
Der obige Code zeigt einen Ausschnitt der Customer-Klasse. Dies ist ein einfaches POJO (Plain Old Java Object) mit Eigenschaften wie der Kunden-ID, Vor- und Nachname, E-Mail-Adresse und einer Reihe von Postanschriften.
Lassen Sie uns nun das Order-Dokument betrachten.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Bei diesem können Sie einige Unterschiede im Vergleich zur MongoDB-Version bemerken. Tatsächlich haben wir bei MongoDB eine Referenz zur Kundeninstanz verwendet, die mit dieser Bestellung verbunden ist. Diese Vorstellung von Referenz existiert nicht bei Elasticsearch, und daher verwenden wir diese Dokument-ID, um eine Beziehung zwischen der Bestellung und dem Kunden, der sie aufgegeben hat, herzustellen. Das gilt ebenfalls für die Eigenschaft orderItemSet, die eine Beziehung zwischen der Bestellung und ihren Artikeln herstellt.
Der Rest unseres Domänenmodells ist fairly ähnlich und basiert auf den gleichen Normalisierungsideen. Zum Beispiel das OrderItem-Dokument:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Hier müssen wir das Produkt associieren, das Gegenstand des aktuellen Bestellpostens ist. Letztlich haben wir das Product-Dokument:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}Die Daten-Speicherorte
Quarkus Panache stark vereinfacht den Datenpersistenz-Prozess durch die Unterstützung sowohl des Active Record– als auch des Repository-Designmusters. In Teil 1 haben wir die Quarkus Panache-Erweiterung für MongoDB verwendet, um unsere Daten Repositories zu implementieren, aber es gibt noch keine äquivalente Quarkus Panache-Erweiterung für Elasticsearch. correspondierend, müssen wir hier unsere Daten Repositories manuell mit dem dedizierten Elasticsearch-Client implementieren, während wir auf eine mögliche zukünftige Quarkus-Erweiterung für Elasticsearch warten.
Elasticsearch ist in Java geschrieben und daher ist es keine Überraschung, dass es nativen Support für den Aufruf der Elasticsearch-API über die Java-Client-Bibliothek bietet. Diese Bibliothek basiert auf dem fluent API Builder-Designmuster und bietet sowohl synchrone als auch asynchrone Verarbeitungsmodule. Sie erfordert mindestens Java 8.
Wie sehenalso unsere auf fluent API Builder basierenden Daten Repositories aus? Below ist ein Auszug aus der CustomerServiceImpl-Klasse, die als Daten Repository für das Customer-Dokument dient.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
Wie wir sehen können, muss unsere Daten Repository-Implementierung ein CDI-Bean mit Anwendungsbereich sein. Der Elasticsearch Java-Client wird einfach injiziert, dank der quarkus-elasticsearch-java-client-Quarkus-Erweiterung. Auf diese Weise umgeht man viele überflüssige Verzierungen, die wir ansonsten verwenden mussten. Das einzige, was wir benötigen, um den Client injizieren zu können, ist die Deklaration der folgenden Eigenschaft:
quarkus.elasticsearch.hosts = elasticsearch:9200Hier ist elasticsearch der DNS-(Domain Name Server)-Name, den wir mit dem Elastic Search-Datenbankserver im docker-compose.yaml-Datei verknüpfen. 9200 ist die TCP-Portnummer, die der Server verwendet, um Verbindungen zu empfangen.
Die Methode doIndex() oben erstellt einen neuen Index namens customers, falls dieser nicht existiert, und indiziert (speichert) darin ein neues Dokument, das eine Instanz der Klasse Customer darstellt. Der Indizierungsprozess wird basierend auf einer IndexRequest durchgeführt, die als Eingabeargumente den Indexnamen und den Dokumentenkörper akzeptiert. Was die Dokument-ID angeht, wird diese automatisch generiert und dem Aufrufer für weitere Referenz zurückgegeben.
Die folgende Methode ermöglicht es, den Kunden zu abrufen, der durch die als Eingabeargument übergebene ID identifiziert wird:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
Das Prinzip ist das gleiche: Mit diesem fluent API-Builder-Muster erstellen wir eine GetRequest-Instanz ähnlich wie bei der IndexRequest, und wir führen sie gegen den Elasticsearch Java-Client aus. Die anderen Endpunkte unseres DatenSpeichers, die es uns ermöglichen, vollständige Suchoperationen durchzuführen oder Kunden zu aktualisieren und zu löschen, sind auf die gleiche Weise gestaltet.
Bitte nehmen Sie sich die Zeit, den Code anzusehen, um zu verstehen, wie Dinge funktionieren.
Die REST-API
Unsere MongoDB REST API-Schnittstelle war einfach zu implementieren, dank der quarkus-mongodb-rest-data-panache-Erweiterung, bei der der Annotation Processor automatisch alle erforderlichen Endpunkte generierte. Bei Elasticsearch profitieren wir noch nicht vom gleichen Komfort und müssen daher manuell implementieren. Das ist kein großes Problem, da wir die vorherigen Datenrepräsentationen injizieren können, wie unten gezeigt:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Dies ist die Implementierung der REST API des Kunden. Die anderen in Verbindung mit Bestellungen, Bestellpositionen und Produkten sind ähnlich.
Sehen wir uns nun an, wie man das ganze Ding ausführt und testet.
Running and Testing Our Microservices
Nun, da wir uns die Details unserer Implementierung angesehen haben, schauen wir uns an, wie man sie ausführt und testet. Wir haben uns entschieden, dies im Namen des docker-compose-Dienstprogramms zu tun. Hier ist die zugehörige docker-compose.yml-Datei:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Diese Datei weist das docker-compose-Dienstprogramm an, drei Dienste auszuführen:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
Jetzt können Sie überprüfen, ob alle erforderlichen Prozesse laufen:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Um zu bestätigen, dass der Elasticsearch-Server verfügbar ist und Abfragen ausführen kann, können Sie sich mit Kibana unter http://localhost:601 verbinden. Nach dem Blättern nach unten auf der Seite und der Auswahl von Dev Tools im Einstellungsmenü können Sie Abfragen wie unten gezeigt ausführen:
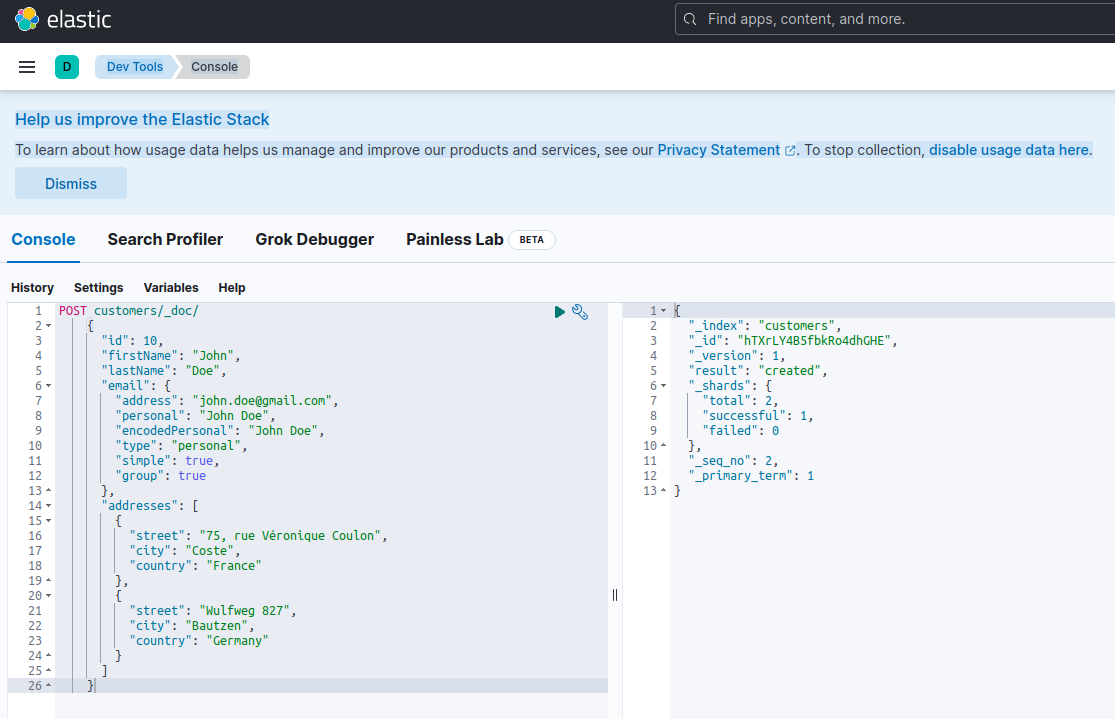
Um die Microservices zu testen, gehen Sie wie folgt vor:
1. Klonen Sie das zugehörige GitHub-Repository:
$ git clone https://github.com/nicolasduminil/docstore.git2. Gehen Sie zum Projekt:
$ cd docstore3. Wechseln Sie zur richtigen Zweigstelle:
$ git checkout elastic-search4. Kompilieren:
$ mvn clean install5. Führen Sie die Integrations tests aus:
$ mvn -DskipTests=false failsafe:integration-testDieser letzte Befehl führt die 17 bereitgestellten Integrations tests aus, die alle erfolgreich abgeschlossen werden sollten. Sie können auch die Swagger UI-Oberfläche zu Testzwecken verwenden, indem Sie Ihren bevorzugten Browser auf http://localhost:8080/q:swagger-ui aufrufen. Anschließend können Sie die in den JSON-Dateien im Verzeichnis src/resources/data des docstore-api-Projekts befindlichen Daten als Payload für die Endpunkt-Tests verwenden.
Genießen Sie!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse