













Dies ist ein Teil der digitalen Transformation eines Immobilienriesen. Aus Gründen der Vertraulichkeit werde ich keine Geschäftszahlen preisgeben, aber Sie erhalten einen detaillierten Einblick in unser Datenlager und unsere Optimierungsstrategien.
Fangen wir an.
Architektur
Logischerweise lässt sich unsere Datenarchitektur in vier Teile unterteilen.
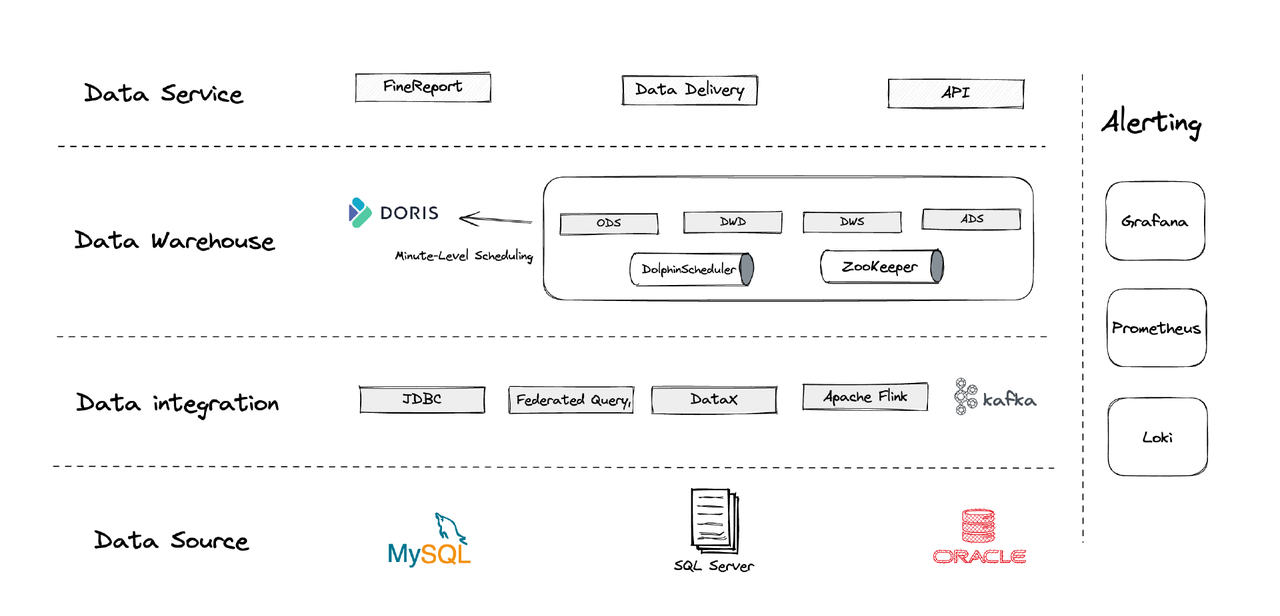
- Datenintegration: Dies wird durch Flink CDC, DataX und die Multi-Catalog-Funktion von Apache Doris unterstützt.
- Datenmanagement: Wir verwenden Apache Dolphinscheduler für die Lebenszyklusverwaltung von Skripten, Berechtigungen in der Multi-Tenancy-Verwaltung und Datenqualitätsüberwachung.
- Warnungen: Wir verwenden Grafana, Prometheus und Loki zur Überwachung von Komponentenressourcen und Protokollen.
- Datendienste: Hier kommen BI-Tools zum Einsatz für die Benutzerinteraktion, wie Datenabfragen und -analyse.
1. Tabellen
Wir erstellen unsere Dimensionstabellen und Faktentabellen, die sich jeweils um jedes operativ tätige Geschäftsglied kreisen, einschließlich Kunden, Häusern usw. Bei einer Reihe von Aktivitäten, die das gleiche operativ tätige Geschäftsglied betreffen, sollten diese durch ein Feld erfasst werden. (Dies ist eine Lehre aus unserem vorherigen chaotischen Datenmanagementsystem.)
2. Schichten
Unser Datenlager ist in fünf konzeptionelle Schichten unterteilt. Wir verwenden Apache Doris und Apache DolphinScheduler, um die DAG-Skripte zwischen diesen Schichten zu planen.

Jeden Tag erfahren die Schichten eine umfassende Aktualisierung neben inkrementellen Aktualisierungen im Falle von Änderungen in historischen Statusfeldern oder unvollständiger Datensynchronisierung von ODS-Tabellen.
3. Inkrementelle Aktualisierungsstrategien
(1) Setze where >= "activity time -1 day or -1 hour" anstelle von where >= "activity time
Der Grund dafür ist, um Datenverschiebungen durch die Zeitlücke von Planungsscripts zu verhindern. Angenommen, das Intervall ist auf 10 Minuten eingestellt, und angenommen, das Script wird um 23:58:00 ausgeführt und ein neues Datenstück kommt um 23:59:00 an. Wenn wir where >= "activity time setzen, würde dieses Datenstück des Tages verpasst.
(2) Hole die ID des größten Primärschlüssels der Tabelle vor jeder Scriptausführung, speichere die ID in einer Hilfstabelle und setze where >= "ID in auxiliary table"
Dies dient zur Vermeidung von Datenduplikation. Datenduplikation könnte auftreten, wenn man das Unique Key Modell von Apache Doris verwendet und eine Gruppe von Primärschlüsseln festlegt, denn wenn es Änderungen an den Primärschlüsseln in der Quelltabelle gibt, werden diese aufgezeichnet und die relevanten Daten werden geladen. Diese Methode kann das beheben, ist jedoch nur anwendbar, wenn die Quelltabellen Primärschlüssel mit Auto-Inkrement haben.
(3) Partitioniere die Tabellen
Bezüglich zeitbasierten automatisch inkrementierenden Daten wie Log-Tabellen könnten die historischen Daten und Status weniger Veränderungen aufweisen, aber das Datenvolumen ist groß, sodass es bei Gesamtaktualisierungen und der Erstellung von Momentaufnahmen enorme Rechenbelastungen geben kann. Daher ist es besser, solche Tabellen zu partitionieren, damit wir bei jeder inkrementellen Aktualisierung nur eine Partition ersetzen müssen. (Auch auf Datenabweichungen sollte geachtet werden.)
4. Gesamtaktualisierungsstrategien
(1) Tabellenlöschung
Lösche die Tabelle und lade dann alle Daten aus der Quelltabelle darin neu. Dies ist für kleine Tabellen und Szenarien ohne Benutzeraktivität in den frühen Morgenstunden geeignet.
(2)ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Dies ist eine atomare Operation und für große Tabellen ratsam. Vor jedem Skriptausführen erstellen wir eine temporäre Tabelle mit dem gleichen Schema, laden alle Daten darin und ersetzen die ursprüngliche Tabelle durch sie.
Anwendung
- ETL-Auftrag: jede Minute
- Konfiguration für erstmalige Bereitstellung: 8 Knoten, 2 Frontends, 8 Backends, hybride Bereitstellung
- Knotenkonfiguration: 32C * 60GB * 2TB SSD
Dies ist unsere Konfiguration für Terabytes an Alt-Daten und Gigabytes an inkrementellen Daten. Sie können sie als Referenz verwenden und Ihr Cluster basierend darauf skalieren. Die Bereitstellung von Apache Doris ist einfach. Sie benötigen keine zusätzlichen Komponenten.
1. Um Offline-Daten und Log-Daten zu integrieren, verwenden wir DataX, das die CSV-Formatformat und Leser vieler relationaler Datenbanken unterstützt, und Apache Doris bietet einen DataX-Doris-Writer.

2. Wir verwenden Flink CDC, um Daten von Quelltabellen zu synchronisieren. Anschließend aggregieren wir die Echtzeit-Metriken mithilfe der Materialized View oder des Aggregate Model von Apache Doris. Da wir nur einen Teil der Metriken in Echtzeit verarbeiten müssen und nicht zu viele Datenbankverbindungen generieren möchten, verwenden wir einen Flink-Job, um mehrere CDC-Quelltabellen zu verwalten. Dies wird durch die Multi-Source-Zusammenführung und die vollständige Datenbanksynchronisierung von Dinky realisiert, oder Sie können selbst eine Flink DataStream Multi-Source-Zusammenführungsaufgabe implementieren. Es ist bemerkenswert, dass sowohl Flink CDC als auch Apache Doris die Unterstützung für Schema-Änderungen bieten.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. Wir verwenden SQL-Skripte oder „Shell + SQL“-Skripte und führen Skript-Lebenszyklus-Management durch. In der ODS-Schicht schreiben wir eine allgemeine DataX-Job-Datei und übergeben Parameter für die Aufnahme jeder Quelltabelle, anstatt einen DataX-Job für jede Quelltabelle zu schreiben. Auf diese Weise erleichtern wir die Wartung erheblich. Wir verwalten die ETL-Skripte von Apache Doris in DolphinScheduler, wo wir auch Versionskontrolle durchführen. Im Falle von Fehlern im Produktionsumfeld können wir jederzeit zurücksetzen.
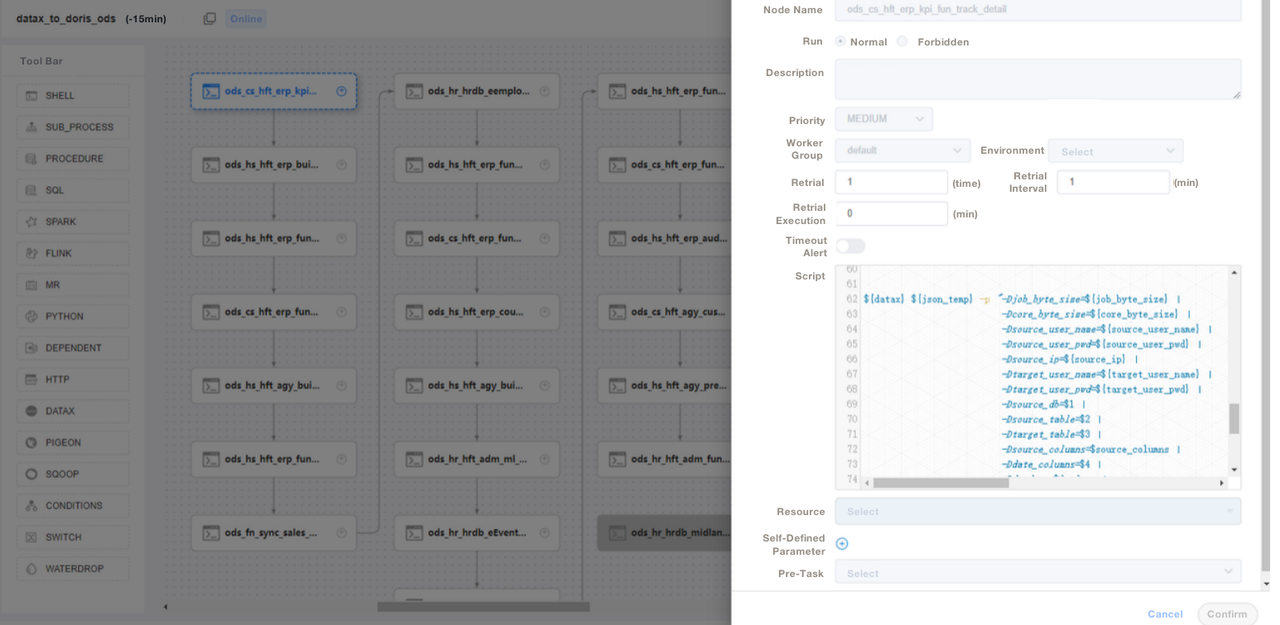
4. Nach der Aufnahme von Daten mit ETL-Skripten erstellen wir eine Seite in unserem Berichtswerkzeug. Wir vergeben unterschiedliche Berechtigungen an verschiedene Konten mithilfe von SQL, einschließlich der Berechtigung zur Änderung von Zeilen, Feldern und globalen Wörterbüchern. Apache Doris unterstützt die bevölkerungsrechtliche Kontrolle über Konten, was genauso funktioniert wie in MySQL.
Wir verwenden auch Apache Doris Datensicherung für Notfallwiederherstellung, Apache Doris Audit-Protokolle zur Überwachung der SQL-Ausführungseffizienz, Grafana+Loki für Cluster-Metrik-Warnungen und Supervisor zur Überwachung der Daemon-Prozesse der Knotenkomponenten.
Optimierung
Datenaufnahme
Wir verwenden DataX, um Offline-Daten per Stream Load zu laden. Es ermöglicht uns, die Größe jeder Charge anzupassen. Die Stream Load-Methode gibt Ergebnisse synchron zurück, was die Anforderungen unserer Architektur erfüllt. Wenn wir asynchrone Datenimporte mit DolphinScheduler ausführen, kann das System annehmen, dass das Skript ausgeführt wurde, und das kann zu Verwirrungen führen. Wenn Sie eine andere Methode verwenden, empfehlen wir, show load im Shell-Skript auszuführen und den Status der Regex-Filterung zu überprüfen, um zu sehen, ob die Aufnahme erfolgreich ist.
Datenmodell
Wir verwenden für die meisten unserer Tabellen das Unique Key Modell von Apache Doris. Das Unique Key Modell stellt die Idempotenz von Datenskripten sicher und vermeidet effektiv eine Wiederholung von Daten aus dem Upstream.
Lesen von externen Daten
Wir nutzen die Multi-Catalog-Funktion von Apache Doris, um auf externe Datenquellen zuzugreifen. Es ermöglicht uns, Zuordnungen für externe Daten auf Katalogebene zu erstellen.
Abfrageoptimierung
Wir empfehlen, die am häufigsten verwendeten Felder von nicht-charakteristischen Typen (wie int und where-Klauseln) in den ersten 36 Bytes zu platzieren, damit Sie diese Felder in Millisekunden bei Punktabfragen filtern können.
Datenwörterbuch
Für uns ist es wichtig, ein Datenwörterbuch zu erstellen, da es den Personalkommunikationsaufwand erheblich reduziert, was bei einer großen Mannschaft zu Kopfschmerzen führen kann. Wir verwenden die information_schema in Apache Doris, um ein Datenwörterbuch zu generieren. Damit können wir schnell den Überblick über die Tabellen und Felder erhalten und somit die Entwicklungseffizienz erhöhen.
Leistung
Offline-Datenaufnahmezeit: Innerhalb von Minuten
Abfrageverzögerung: Für Tabellen mit über 100 Millionen Zeilen antwortet Apache Doris innerhalb einer Sekunde auf Ad-hoc-Abfragen und komplexe Abfragen innerhalb von fünf Sekunden.
Ressourcenverbrauch: Es werden nur wenige Server benötigt, um dieses Datenlager zu errichten. Die Komprimierungsrate von 70% in Apache Doris spart uns viel Speicherplatz.
Erfahrungen und Schlussfolgerungen
Tatsächlich haben wir vor unserer aktuellen Datenarchitektur versucht, Hive, Spark und Hadoop zu verwenden, um ein Offline-Datenlager zu errichten. Es stellte sich heraus, dass Hadoop für ein traditionelles Unternehmen wie uns überdimensioniert war, da wir nicht zu viel zu verarbeitendes Datenmaterial hatten. Es ist wichtig, das für einen passende Komponente zu finden.
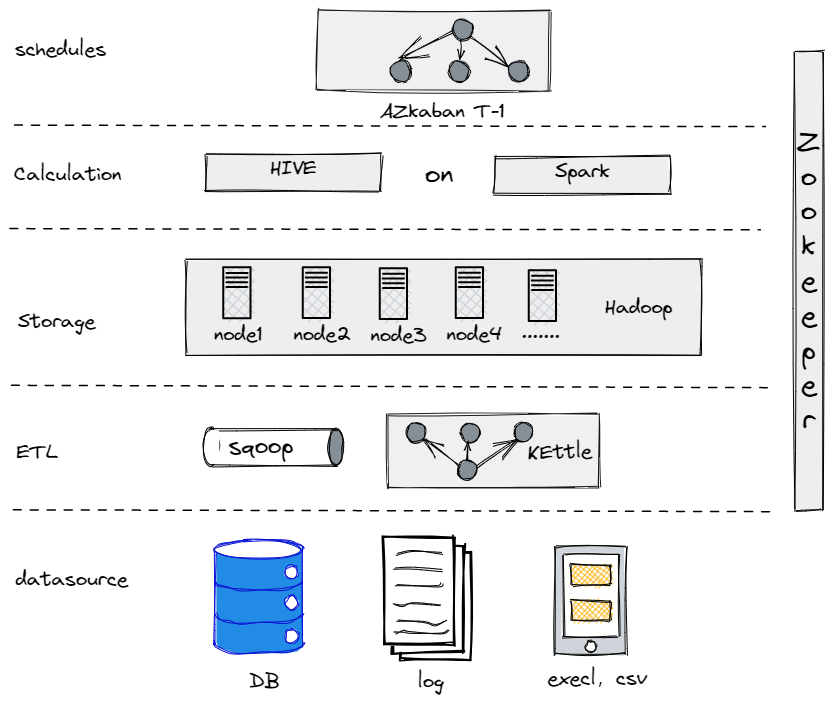
Unser altes Offline-Datenlager
Andererseits müssen wir unsere Datenplattform in Bezug auf Bedienung und Wartung so einfach wie möglich gestalten, um unsere Big-Data-Transition zu erleichtern. Deshalb haben wir uns für Apache Doris entschieden. Es ist kompatibel mit dem MySQL-Protokoll und bietet eine umfangreiche Sammlung von Funktionen, sodass wir unsere eigenen UDFs nicht entwickeln müssen. Darüber hinaus besteht es nur aus zwei Arten von Prozessen: Frontends und Backends, wodurch es einfach zu skalieren und zu verfolgen ist.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry