













Der Aufstieg der agentischen KI hat die Begeisterung für Agenten angeheizt, die autonom Aufgaben ausführen, Empfehlungen abgeben und komplexe Workflows ausführen, die KI mit herkömmlicher Rechenleistung kombinieren. Aber die Schaffung solcher Agenten in realen, produktgetriebenen Umgebungen birgt Herausforderungen, die über die KI selbst hinausgehen.
Ohne sorgfältige Architektur können Abhängigkeiten zwischen Komponenten Engpässe schaffen, die Skalierbarkeit einschränken und die Wartung komplizieren, wenn Systeme sich weiterentwickeln. Die Lösung liegt in der Entkopplung von Workflows, bei der Agenten, Infrastruktur und andere Komponenten fließend interagieren, ohne starre Abhängigkeiten.
Diese Art von flexibler, skalierbarer Integration erfordert eine gemeinsame „Sprache“ für den Datenaustausch – eine robuste ereignisgesteuerte Architektur (EDA), die von Ereignisströmen unterstützt wird. Durch die Organisation von Anwendungen um Ereignisse herum können Agenten in einem reaktionsfähigen, entkoppelten System arbeiten, in dem jeder Teil unabhängig agiert. Teams können Technologieentscheidungen frei treffen, Skalierungsanforderungen separat verwalten und klare Grenzen zwischen Komponenten aufrechterhalten, was echte Agilität ermöglicht.
Um diese Prinzipien zu testen, habe ich PodPrep AI entwickelt, einen KI-gestützten Forschungsassistenten, der mir hilft, mich auf Podcast-Interviews bei Software Engineering Daily und Software Huddle vorzubereiten. In diesem Beitrag werde ich auf das Design und die Architektur von PodPrep AI eingehen und zeigen, wie EDA und Echtzeit-Datenströme ein effektives agentisches System antreiben.
Hinweis: Wenn Sie sich nur den Code ansehen möchten, springen Sie zu meinem GitHub-Repository hier.
Warum eine ereignisgesteuerte Architektur für KI?
In realen AI-Anwendungen hält ein eng gekoppeltes, monolithisches Design nicht stand. Während Machbarkeitsstudien oder Demos oft ein einziges, einheitliches System aus Gründen der Einfachheit verwenden, wird dieser Ansatz schnell unpraktisch in der Produktion, insbesondere in verteilten Umgebungen. Eng gekoppelte Systeme schaffen Engpässe, begrenzen die Skalierbarkeit und verlangsamen die Iteration – alles kritische Herausforderungen, die es zu vermeiden gilt, während AI-Lösungen wachsen.
Betrachten wir einen typischen AI-Agenten.
Er könnte Daten aus mehreren Quellen abrufen, Prompt-Engineering- und RAG-Workflows verwalten und direkt mit verschiedenen Tools interagieren, um deterministische Workflows auszuführen. Die erforderliche Orchestrierung ist komplex, mit Abhängigkeiten von mehreren Systemen. Und wenn der Agent mit anderen Agenten kommunizieren muss, erhöht sich die Komplexität nur noch. Ohne eine flexible Architektur machen diese Abhängigkeiten die Skalierung und Modifikation nahezu unmöglich.

In der Produktion kümmern sich unterschiedliche Teams normalerweise um verschiedene Teile des Stacks: MLOps und Data Engineering verwalten die RAG-Pipeline, Data Science wählt Modelle aus, und Anwendungsentwickler erstellen die Schnittstelle und das Backend. Ein eng gekoppeltes Setup zwingt diese Teams in Abhängigkeiten, die die Lieferung verlangsamen und die Skalierung erschweren. Idealerweise sollten die Anwendungsschichten die Interna der AI nicht verstehen müssen; sie sollten einfach die Ergebnisse bei Bedarf konsumieren.
Darüber hinaus können KI-Anwendungen nicht isoliert arbeiten. Für einen echten Mehrwert müssen KI-Erkenntnisse nahtlos über Kunden-Datenplattformen (CDPs), CRMs, Analysen und mehr fließen. Kundeninteraktionen sollten Echtzeit-Updates auslösen, die direkt in andere Tools zur Handlung und Analyse einfließen. Ohne einen vereinheitlichten Ansatz wird die Integration von Erkenntnissen über Plattformen hinweg zu einem Flickenteppich, der schwer zu verwalten und unmöglich zu skalieren ist.
KI-gesteuerte EDA begegnet diesen Herausforderungen, indem sie ein „zentrales Nervensystem“ für Daten schafft. Mit EDA senden Anwendungen Ereignisse aus, anstatt auf verkettete Befehle angewiesen zu sein. Dies entkoppelt Komponenten, ermöglicht einen asynchronen Datenfluss überall dort, wo er benötigt wird, und ermöglicht es jedem Team, unabhängig zu arbeiten. EDA fördert eine nahtlose Datenintegration, skalierbares Wachstum und Widerstandsfähigkeit – was es zu einer leistungsstarken Grundlage für moderne KI-gesteuerte Systeme macht.
Entwurf eines skalierbaren KI-gesteuerten Forschungsagenten
In den letzten zwei Jahren habe ich Hunderte von Podcasts auf Software Engineering Daily, Software Huddle und Partially Redacted moderiert.
Um mich auf jeden Podcast vorzubereiten, führe ich einen umfassenden Rechercheprozess durch, um einen Podcast-Brief vorzubereiten, der meine Gedanken, Hintergrundinformationen über den Gast und das Thema sowie eine Reihe potenzieller Fragen enthält. Für diesen Brief recherchiere ich typischerweise den Gast und das Unternehmen, für das er arbeitet, höre mir andere Podcasts an, an denen er teilgenommen haben könnte, lese Blogbeiträge, die er verfasst hat, und informiere mich über das Hauptthema, über das wir sprechen werden.
Ich versuche, Verbindungen zu anderen Podcasts, die ich moderiert habe, oder zu meinen eigenen Erfahrungen im Zusammenhang mit dem Thema oder ähnlichen Themen herzustellen. Dieser gesamte Prozess erfordert erhebliche Zeit und Mühe. Große Podcast-Unternehmen haben eigene Forscher und Assistenten, die diese Arbeit für den Moderator erledigen. Ich betreibe hier kein solches Unternehmen. Ich muss das alles selbst machen.
Um dies anzugehen, wollte ich einen Agenten entwickeln, der diese Arbeit für mich erledigen könnte. Auf einer hohen Ebene würde der Agent etwa wie das unten stehende Bild aussehen.

Ich stelle grundlegende Quellenmaterialien wie den Namen des Gasts, das Unternehmen, die Themen, auf die ich mich konzentrieren möchte, einige Referenz-URLs wie Blog-Beiträge und bestehende Podcasts zur Verfügung, und dann geschieht etwas AI-Magie, und meine Recherche ist abgeschlossen.
Diese einfache Idee führte mich zur Entwicklung von PodPrep AI, meinem KI-gestützten Forschungsassistenten, der mich nur Token kostet.
Der Rest dieses Artikels behandelt das Design von PodPrep AI, beginnend mit der Benutzeroberfläche.
Erstellung der Agenten-Benutzeroberfläche
Ich habe die Benutzeroberfläche des Agenten als Webanwendung entworfen, in der ich problemlos Quellenmaterial für den Forschungsprozess eingeben kann. Dazu gehören der Name des Gasts, sein Unternehmen, das Interviewthema, jeglicher zusätzlicher Kontext und Links zu relevanten Blogs, Websites und früheren Podcast-Interviews.
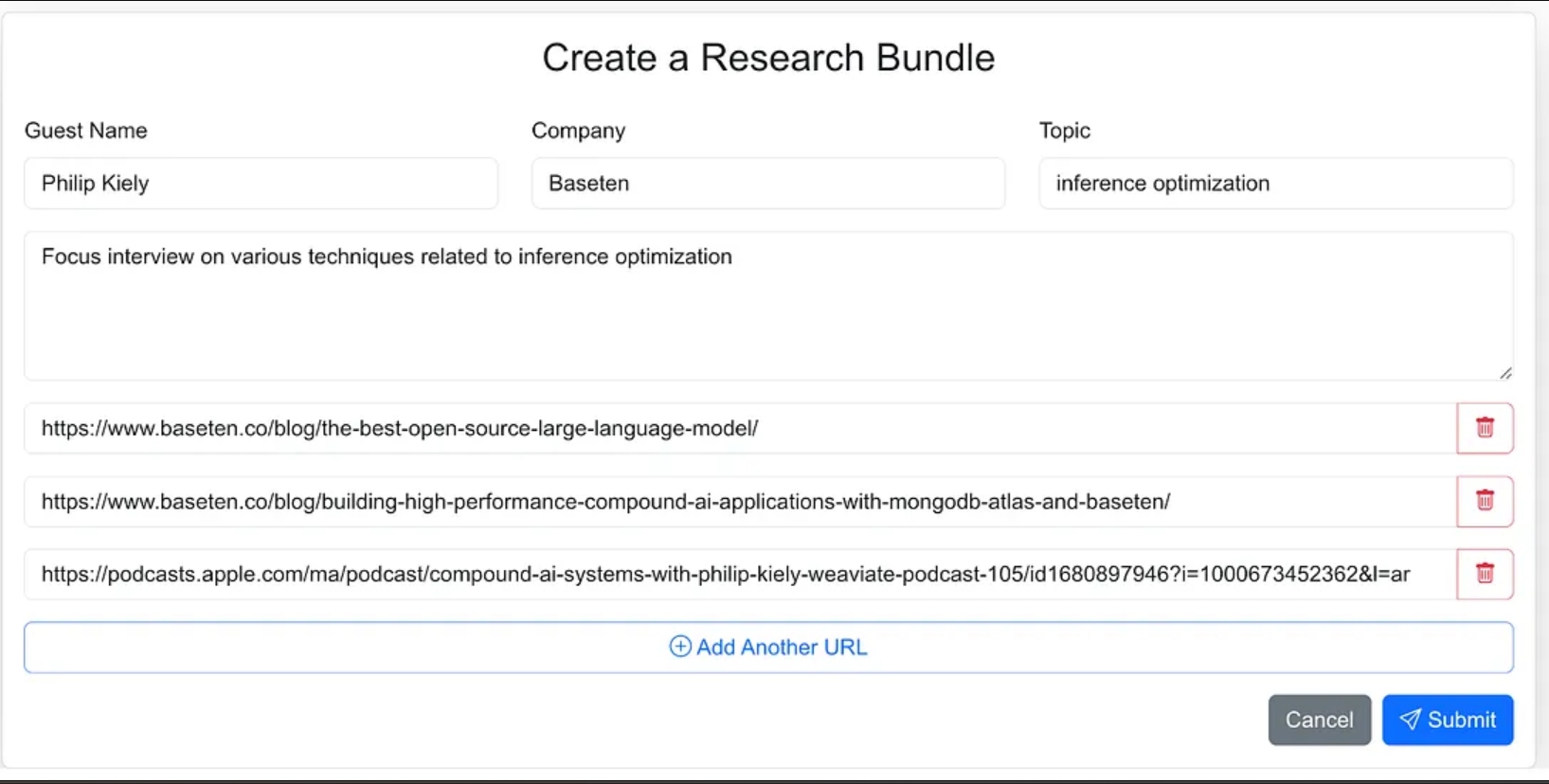
Ich hätte dem Agenten weniger Anweisungen geben können und ihn im Rahmen des agilen Workflows die Quellenmaterialien suchen lassen können, aber für Version 1.0 habe ich beschlossen, die Quell-URLs bereitzustellen.
Die Webanwendung ist eine Standard-Dreischichtenanwendung, die mit Next.js und MongoDB für die Anwendungsdatenbank erstellt wurde. Sie weiß nichts über KI. Sie ermöglicht es einfach dem Benutzer, neue Forschungsbündel einzugeben, die dann im Verarbeitungszustand erscheinen, bis der agentische Prozess den Workflow abgeschlossen und einen Forschungsbericht in der Anwendungsdatenbank erstellt hat.
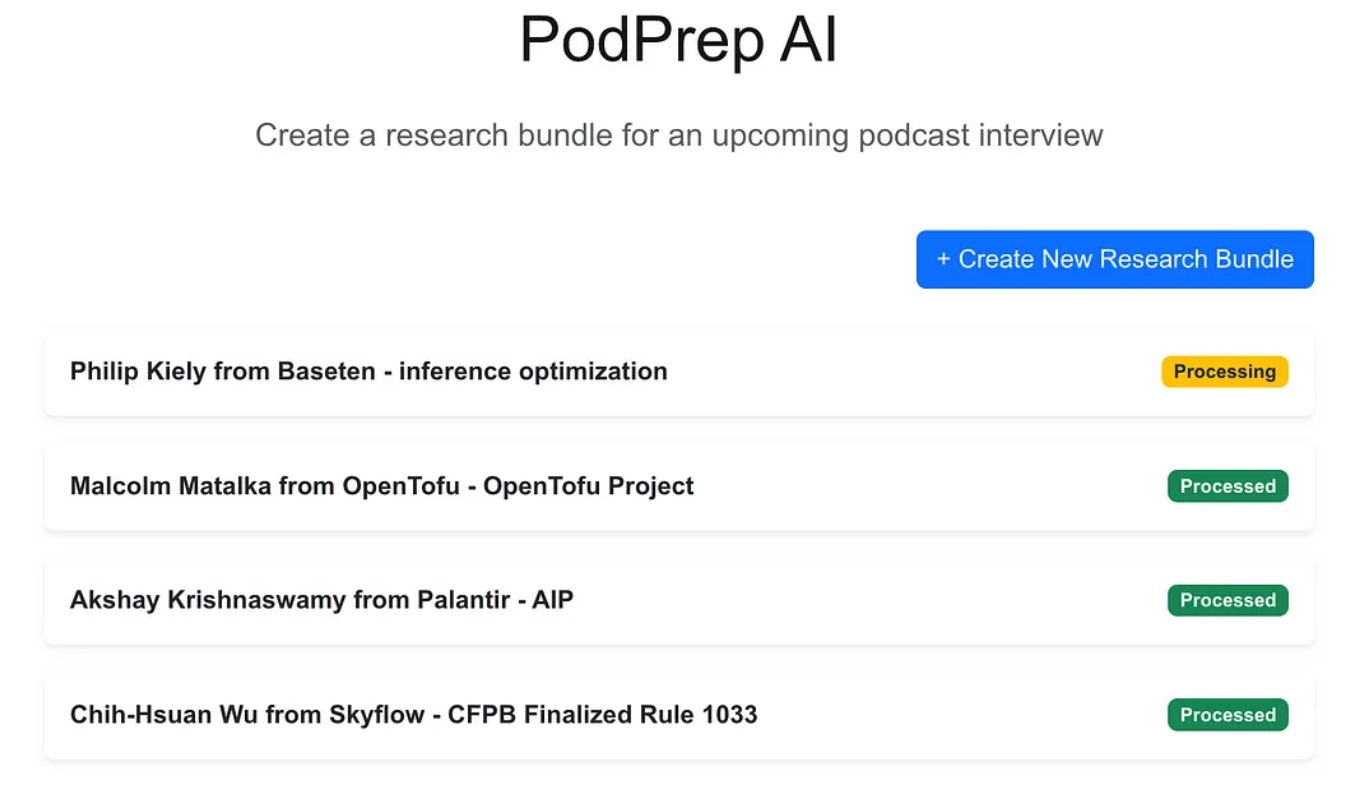
Sobald die KI-Magie abgeschlossen ist, kann ich auf ein Informationsdokument für den Eintrag zugreifen, wie unten dargestellt.

Erstellung des agentischen Workflows
Für Version 1.0 wollte ich in der Lage sein, drei Hauptaktionen zur Erstellung des Forschungsberichts durchzuführen:
- Für jede Website-URL, Blogbeitrag oder Podcast den Text oder die Zusammenfassung abrufen, den Text in angemessene Abschnitte aufteilen, Einbettungen generieren und die Vektorrepräsentation speichern.
- Für alle aus den Forschungsquellen-URLs extrahierten Texte die interessantesten Fragen extrahieren und speichern.
- Einen Podcast-Forschungsbericht erstellen, der den relevantesten Kontext basierend auf den Einbettungen, den besten zuvor gestellten Fragen und allen anderen Informationen enthält, die Teil des Bündeleingangs waren.
Das nachstehende Bild zeigt die Architektur von der Webanwendung bis zum agentischen Workflow.
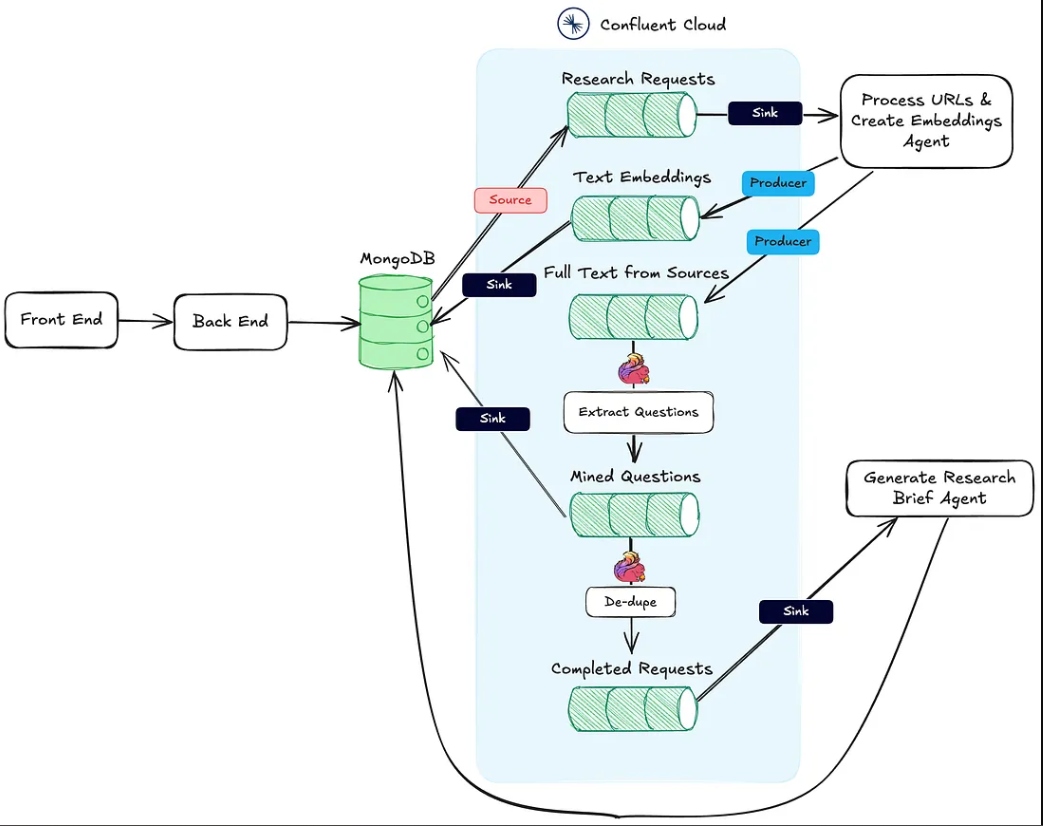
Aktion #1 oben wird durch den HTTP-Senkenendpunkt Process URLs & Create Embeddings Agent unterstützt.
Aktion #2 wird mithilfe von Flink und der integrierten KI-Modellunterstützung in Confluent Cloud durchgeführt.
Schließlich wird Aktion #3 vom Generate Research Brief Agent ausgeführt, der auch ein HTTP-Senken-Endpunkt ist und der aufgerufen wird, sobald die ersten beiden Aktionen abgeschlossen sind.
Im folgenden Abschnitt erläutere ich jede dieser Aktionen im Detail.
Der Prozess-URLs und Einbettungen erstellen Agent
Dieser Agent ist dafür verantwortlich, Texte von den Forschungsquellen-URLs und dem Vektor-Einbettungs-Pipeline abzurufen. Im Folgenden wird der grobe Ablauf dessen, was hinter den Kulissen geschieht, um die Forschungsmaterialien zu verarbeiten, dargestellt.

Nachdem ein Forschungspaket vom Benutzer erstellt und in MongoDB gespeichert wurde, erzeugt ein MongoDB-Quellen-Connector Nachrichten für ein Kafka-Thema namens research-requests. Dies ist es, was den agentischen Workflow startet.
Jeder POST-Request an den HTTP-Endpunkt enthält die URLs aus der Forschungsanfrage und den Primärschlüssel in der MongoDB-Forschungsbündel-Sammlung.
Der Agent durchläuft jede URL und falls es sich nicht um einen Apple-Podcast handelt, ruft er das komplette HTML der Seite ab. Da ich die Struktur der Seite nicht kenne, kann ich mich nicht auf HTML-Analyse-Bibliotheken verlassen, um den relevanten Text zu finden. Stattdessen sende ich den Seitentext an das gpt-4o-mini-Modell mit einer Temperatur von null, um mit dem unten stehenden Prompt zu bekommen, was ich brauche.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Bei Podcasts muss ich noch etwas mehr Arbeit leisten.
Rückwärtsentwicklung von Apple Podcast URLs
Um Daten aus Podcast-Episoden abzurufen, müssen wir zunächst den Ton in Text mithilfe des Whisper-Modells umwandeln. Doch bevor wir das tun können, müssen wir die tatsächliche MP3-Datei für jede Podcast-Episode lokalisieren, herunterladen und in Stücke von 25 MB oder weniger aufteilen (die maximale Größe für Whisper).
Die Herausforderung besteht darin, dass Apple keinen direkten MP3-Link für seine Podcast-Episoden bereitstellt. Das MP3-Dateiformat ist jedoch im ursprünglichen RSS-Feed des Podcasts verfügbar, und wir können diesen Feed programmatisch mithilfe der Apple-Podcast-ID finden.
Zum Beispiel ist im folgenden URL der numerische Teil nach /id die eindeutige Apple-ID des Podcasts:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Mit der API von Apple können wir die Podcast-ID nachschlagen und eine JSON-Antwort abrufen, die die URL für den RSS-Feed enthält:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
Sobald wir den RSS-Feed-XML haben, durchsuchen wir ihn nach der spezifischen Episode. Da wir nur die Episoden-URL von Apple haben (und nicht den tatsächlichen Titel), verwenden wir den Titel-Slug aus der URL, um die Episode im Feed zu finden und ihre MP3-URL abzurufen.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Jetzt, da der Text aus Blogbeiträgen, Websites und MP3s verfügbar ist, verwendet der Agent den rekursiven Text-Splitter von LangChain, um den Text in Abschnitte zu unterteilen und die Embeddings aus diesen Abschnitten zu generieren. Die Abschnitte werden im text-embeddings-Thema veröffentlicht und in MongoDB gespeichert.
- Hinweis: Ich habe mich entschieden, MongoDB sowohl als Anwendungsdatenbank als auch als Vektordatenbank zu verwenden. Aufgrund des EDA-Ansatzes, den ich gewählt habe, können dies jedoch leicht separate Systeme sein, und es ist nur eine Frage des Austauschs des Sink-Connectors vom Thema Text-Embeddings.
Neben der Erstellung und Veröffentlichung der Embeddings veröffentlicht der Agent auch den Text aus den Quellen in ein Thema namens full-text-from-sources. Die Veröffentlichung in diesem Thema initiiert Aktion #2.
Fragen mit Flink und OpenAI extrahieren
Apache Flink ist ein Open-Source-Stream-Verarbeitungs-Framework, das für die Verarbeitung großer Datenmengen in Echtzeit entwickelt wurde und ideal für Anwendungen mit hohem Durchsatz und niedriger Latenz ist. Durch die Kombination von Flink mit Confluent können wir LLMs wie OpenAIs GPT direkt in Streaming-Workflows integrieren. Diese Integration ermöglicht Echtzeit-RAG-Workflows und stellt sicher, dass der Fragenextraktionsprozess mit den aktuellsten verfügbaren Daten arbeitet.
Den Originaltext der Quelle im Stream zu haben, ermöglicht es uns auch, später neue Workflows einzuführen, die dieselben Daten verwenden, was den Prozess der Erstellung von Forschungsbriefen verbessert oder diese an nachgelagerte Dienste wie ein Data Warehouse sendet. Dieses flexible Setup erlaubt es uns, im Laufe der Zeit zusätzliche KI- und Nicht-KI-Funktionen einzufügen, ohne die Kernpipeline überarbeiten zu müssen.
In PodPrep AI verwende ich Flink, um Fragen aus Texten zu extrahieren, die von Quell-URLs abgerufen werden.
Die Einrichtung von Flink, um einen LLM aufzurufen, beinhaltet die Konfiguration einer Verbindung über die CLI von Confluent. Unten finden Sie ein Beispielkommando zur Einrichtung einer OpenAI-Verbindung, obwohl mehrere Optionen verfügbar sind.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Sobald die Verbindung hergestellt ist, kann ich ein Modell erstellen entweder in der Cloud-Konsole oder im Flink SQL-Shell. Für die Fragenextraktion richte ich das Modell entsprechend ein.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
Mit dem bereitgestellten Modell verwende ich die integrierte ml_predict Funktion von Flink, um Fragen aus dem Ausgangsmaterial zu generieren und schreibe die Ausgabe in einen Stream namens mined-questions, der mit MongoDB synchronisiert wird, um später verwendet zu werden.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink hilft auch dabei, nachzuvollziehen, wann alle Forschungsunterlagen verarbeitet wurden, was die Erstellung des Forschungsberichts auslöst. Dies geschieht, indem in einen completed-requests Stream geschrieben wird, sobald die URLs in mined-questions mit denen im Volltextquellen-Stream übereinstimmen.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
Wenn Nachrichten in completed-requests geschrieben werden, wird die eindeutige ID für das Forschungsbundle an den Generate Research Brief Agent gesendet.
Der Generate Research Brief Agent
Dieser Agent nimmt alle relevantesten Forschungsunterlagen und verwendet ein LLM, um einen Forschungsbericht zu erstellen. Unten ist der übergeordnete Ablauf der Ereignisse, die stattfinden, um einen Forschungsbericht zu erstellen.

Ablaufdiagramm für den Generate Research Brief Agent
Lassen Sie uns einige dieser Schritte aufschlüsseln. Um den Prompt für das LLM zu erstellen, kombiniere ich die extrahierten Fragen, das Thema, den Namen des Gastes, den Firmennamen, einen Systemprompt zur Anleitung und den Kontext, der in der Vektordatenbank gespeichert ist und am semantisch ähnlichsten zum Podcast-Thema ist.
Aufgrund des begrenzten Kontextinformationen im Forschungsbundle ist es herausfordernd, den relevantesten Kontext direkt aus dem Vektorspeicher zu extrahieren. Um dies zu lösen, lasse ich das LLM eine Suchanfrage generieren, um den bestmöglich übereinstimmenden Inhalt zu finden, wie im Knoten „Suchanfrage erstellen“ im Diagramm dargestellt.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
Mit der von LLM generierten Anfrage erstelle ich eine Einbettung und durchsuche MongoDB über einen Vektorindex, wobei ich nach der bundleId filtere, um die Suche auf Materialien zu beschränken, die für den spezifischen Podcast relevant sind.
Nachdem die beste Kontextinformation identifiziert wurde, erstelle ich eine Aufforderung und generiere den Forschungsbericht, speichere das Ergebnis in MongoDB, damit die Webanwendung es anzeigen kann.
Zu beachten bei der Implementierung
Ich habe sowohl die Front-End-Anwendung für PodPrep AI als auch die Agents in JavaScript geschrieben, aber in einem realen Szenario wäre der Agent wahrscheinlich in einer anderen Sprache wie Python. Zusätzlich sind sowohl der Prozess URLs & Einbettungen Agent als auch der Generiere Forschungsbericht Agent aus Gründen der Einfachheit im selben Projekt auf demselben Webserver. In einem echten Produktionssystem könnten diese serverlose Funktionen sein, die unabhängig voneinander laufen.
Abschließende Gedanken
Der Aufbau von PodPrep AI hebt hervor, wie eine ereignisgesteuerte Architektur es ermöglicht, KI-Anwendungen in der realen Welt skalierbar und reibungslos anpassbar zu machen. Mit Flink und Confluent habe ich ein System erstellt, das Daten in Echtzeit verarbeitet, um einen KI-gesteuerten Workflow ohne starre Abhängigkeiten zu unterstützen. Dieser entkoppelte Ansatz ermöglicht es den Komponenten, unabhängig voneinander zu arbeiten, aber über Ereignisströme verbunden zu bleiben – dies ist unerlässlich für komplexe, verteilte Anwendungen, bei denen unterschiedliche Teams verschiedene Teile des Systems verwalten.
In der heutigen von KI geprägten Umgebung ist der Zugriff auf frische, Echtzeitdaten über Systeme hinweg unerlässlich. EDA fungiert als „zentrales Nervensystem“ für Daten, das eine nahtlose Integration und Flexibilität bei der Skalierung des Systems ermöglicht.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink