













Organisationen beginnen ihre Daten-Streaming-Adoption mit einem einzelnen Apache Kafka-Cluster, um die ersten Anwendungsfälle zu implementieren. Der Bedarf an konzernweiter Datenverwaltung und Sicherheit, aber unterschiedliche SLAs, Latenzzeiten und Infrastrukturanforderungen führen zur Einführung neuer Kafka-Cluster. Mehrere Kafka-Cluster sind die Norm, nicht die Ausnahme. Anwendungsfälle umfassen hybride Integration, Aggregation, Migration und Notfallwiederherstellung. In diesem Blogbeitrag werden Erfolgsgeschichten aus der Praxis und Clusterstrategien für verschiedene Kafka-Bereitstellungen in verschiedenen Branchen erkundet.

Apache Kafka: Der De-facto-Standard für ereignisgesteuerte Architekturen und Daten-Streaming
Apache Kafka ist eine Open-Source, verteilte Event-Streaming-Plattform, die für eine hohe Durchsatzrate und geringe Latenzzeiten bei der Datenverarbeitung entwickelt wurde. Es ermöglicht das Veröffentlichen, Abonnieren, Speichern und Verarbeiten von Datensätzen in Echtzeit.
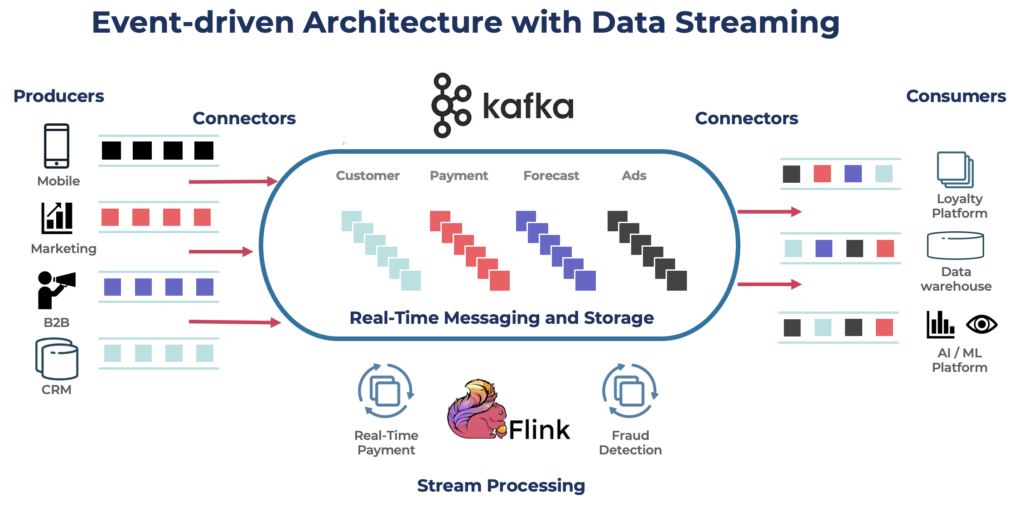
Kafka ist eine beliebte Wahl für den Aufbau von Echtzeit-Datenpipelines und Streaming-Anwendungen. Das Kafka-Protokoll wurde zum de facto Standard für Event-Streaming in verschiedenen Frameworks, Lösungen und Cloud-Diensten. Es unterstützt operative und analytische Workloads mit Funktionen wie persistentem Speicher, Skalierbarkeit und Fehlertoleranz. Kafka umfasst Komponenten wie Kafka Connect für die Integration und Kafka Streams für die Stream-Verarbeitung, was es zu einem vielseitigen Werkzeug für verschiedene datengestützte Anwendungsfälle macht.
Während Kafka für Echtzeitanwendungen bekannt ist, nutzen viele Projekte die Datenstreaming-Plattform für die Datenkonsistenz in der gesamten Unternehmensarchitektur, einschließlich Datenbanken, Datenseen, Altsystemen, offenen APIs und Cloud-nativen Anwendungen.
Verschiedene Apache Kafka Cluster-Typen
Kafka ist ein verteiltes System. Eine Produktionsumgebung erfordert normalerweise mindestens vier Broker. Daher gehen die meisten Menschen automatisch davon aus, dass man nur einen einzigen verteilten Cluster benötigt, den man bei zusätzlichem Durchsatz und Anwendungsfällen skalieren kann. Das ist zu Beginn nicht falsch. Aber…
Ein Kafka-Cluster ist nicht die richtige Antwort für jeden Anwendungsfall. Verschiedene Eigenschaften beeinflussen die Architektur eines Kafka-Clusters:
- Verfügbarkeit: Null Ausfallzeiten? 99,99% Verfügbarkeits-SLA? Nicht kritische Analysen?
- Latenz: End-to-End-Verarbeitung in <100 ms (einschließlich Verarbeitung)? 10-minütige End-to-End-Datenlagerpipeline? Zeitreisen zur erneuten Verarbeitung historischer Ereignisse?
- Kosten: Wert vs. Kosten? Gesamtbetriebskosten (TCO) sind wichtig. Beispielsweise können in der öffentlichen Cloud die Netzwerkkosten bis zu 80% der Gesamtkosten von Kafka ausmachen!
- Sicherheit und Datenschutz: Datenschutz (PCI-Daten, DSGVO usw.)? Datenverwaltung und Compliance? End-to-End-Verschlüsselung auf Attributsebene? Eigenen Schlüssel mitbringen? Öffentlicher Zugriff und Datenfreigabe? Luftdichtes Edge-Umfeld?
- Durchsatz und Datenmenge: Kritische Transaktionen (typischerweise geringes Volumen)? Große Datenfeeds (Clickstream, IoT-Sensoren, Sicherheitsprotokolle usw.)?
Zusammenhängende Themen wie On-Premise vs. öffentliche Cloud, regional vs. global und viele andere Anforderungen beeinflussen ebenfalls die Kafka-Architektur.
Strategien und Architekturen von Apache Kafka-Clustern
Ein einzelner Kafka-Cluster ist oft der richtige Ausgangspunkt für Ihre Daten-Streaming-Reise. Er kann verschiedene Anwendungsfälle aus verschiedenen Geschäftsbereichen aufnehmen und Gigabyte pro Sekunde verarbeiten (wenn er richtig betrieben und skaliert wird).
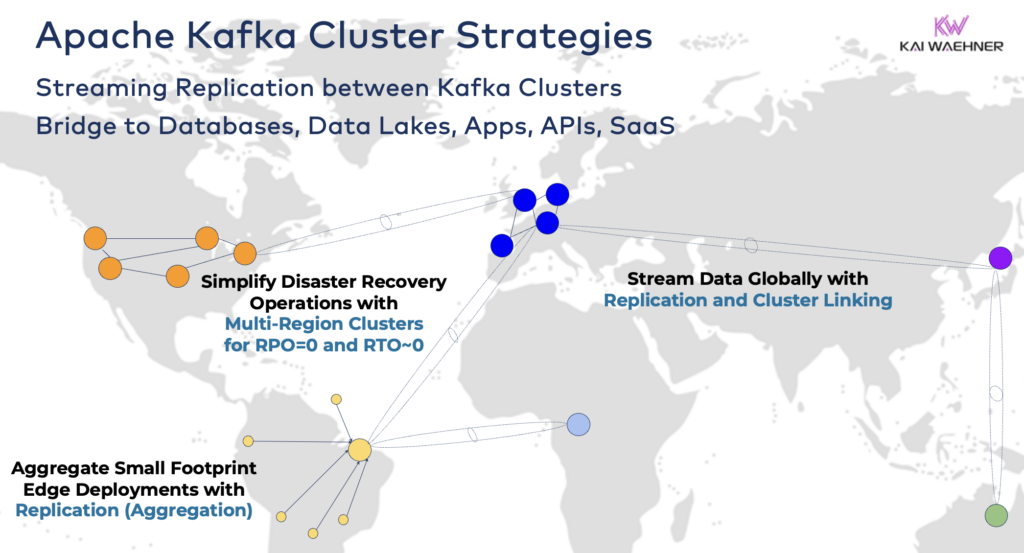
Je nach den Anforderungen Ihres Projekts benötigen Sie jedoch eine Unternehmensarchitektur mit mehreren Kafka-Clustern. Hier sind ein paar gängige Beispiele:
- Hybrid-Architektur: Datenintegration und uni- oder bidirektionale Datensynchronisation zwischen mehreren Rechenzentren. Oftmals Verbindung zwischen einem lokalisierten Rechenzentrum und einem öffentlichen Cloud-Service-Anbieter. Migration von Legacy-Systemen in die Cloud-Analyse ist eines der häufigsten Szenarien. Aber auch Befehls- und Steuerungskommunikation ist möglich, d.h. das Senden von Entscheidungen/Empfehlungen/Transaktionen in eine regionale Umgebung (z.B. Speichern einer Zahlung oder Bestellung aus einer mobilen App im Mainframe).
- Mehrregionen-/Multi-Cloud: Datenreplikation aus Gründen der Einhaltung von Vorschriften, Kosten oder Datenschutz. Datenfreigabe beinhaltet in der Regel nur einen Teil der Ereignisse, nicht alle Kafka-Themen. Das Gesundheitswesen ist eine von vielen Branchen, die diesen Weg gehen.
- Notfallwiederherstellung: Replikation kritischer Daten im aktiven-aktiven oder aktiven-passiven Modus zwischen verschiedenen Rechenzentren oder Cloud-Regionen. Beinhaltet Strategien und Tools für Failover- und Rückfallmechanismen im Falle eines Notfalls, um die Geschäftskontinuität und die Einhaltung von Vorschriften zu gewährleisten.
- Aggregation: Regionale Cluster für lokale Verarbeitung (z.B. Vorverarbeitung, Streaming-ETL, Stream-Verarbeitung von Geschäftsanwendungen) und Replikation kuratierter Daten zum großen Rechenzentrum oder zur Cloud. Einzelhandelsgeschäfte sind ein ausgezeichnetes Beispiel.
- Migration: IT-Modernisierung durch Migration von lokalisierten Systemen in die Cloud oder von selbstverwalteten Open-Source-Lösungen in ein vollständig verwaltetes SaaS. Solche Migrationen können ohne Ausfallzeiten oder Datenverlust durchgeführt werden, während das Geschäft während des Umstiegs weiterläuft.
- Kante (Getrennt/luftdicht): Sicherheit, Kosten oder Latenz erfordern Kantenbereitstellungen, z. B. in einer Fabrik oder einem Einzelhandelsgeschäft. Einige Branchen setzen in sicherheitskritischen Umgebungen unidirektionale Hardware-Gateways und Daten-Dioden ein.
- Einzelner Makler: Nicht belastbar, aber ausreichend für Szenarien wie die Einbettung eines Kafka-Brokers in eine Maschine oder auf einen Industrie-PC (IPC) und die Replikation von aggregierten Daten in einen großen Cloud-Analytics-Kafka-Cluster. Ein schönes Beispiel ist die Installation von Daten-Streaming (einschließlich Integration und Verarbeitung) auf dem Computer eines Soldaten auf dem Schlachtfeld.
Hybride Kafka-Cluster überbrücken
Diese Optionen können kombiniert werden. Beispielsweise repliziert ein einzelner Makler am Randtypischerweise einige ausgewählte Daten an ein entferntes Rechenzentrum. Hybride Cluster haben je nach Art der Verbindung unterschiedliche Architekturen: Verbindungen über das öffentliche Internet, private Verbindung, VPC-Peering, Transit-Gateway usw.
Nachdem ich die Entwicklung von Confluent Cloud im Laufe der Jahre gesehen habe, habe ich unterschätzt, wie viel Entwicklungszeit für Sicherheit und Konnektivität aufgewendet werden muss. Allerdings sind fehlende Sicherheitsbrücken die Hauptblocker für die Akzeptanz eines Kafka-Cloud-Dienstes. Daher führt kein Weg daran vorbei, verschiedene Sicherheitsbrücken zwischen Kafka-Clustern bereitzustellen, die über das öffentliche Internet hinausgehen.
Es gibt sogar Anwendungsfälle, bei denen Organisationen Daten aus dem Rechenzentrum in die Cloud replizieren müssen, aber der Cloud-Dienst nicht dazu berechtigt ist, die Verbindung zu initiieren. Confluent hat eine spezifische Funktion namens „Quell-initiierte Verbindung“ für solche Sicherheitsanforderungen entwickelt, bei der die Quelle (d. h. der lokale Kafka-Cluster) immer die Verbindung initiiert – auch wenn die Cloud-Kafka-Cluster die Daten verbrauchen:
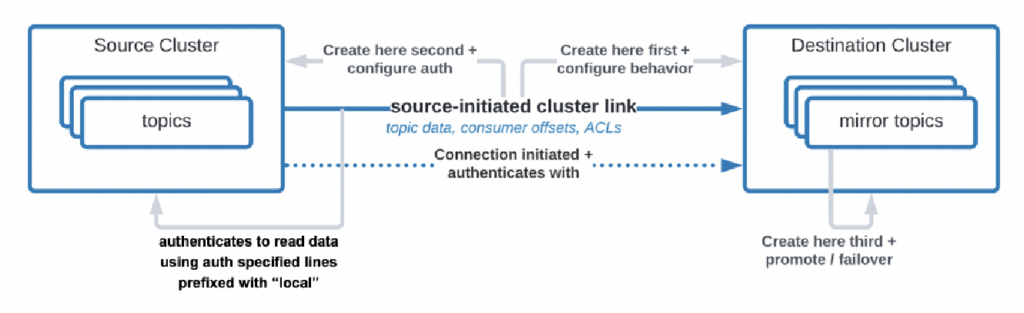 Quelle: Confluent
Quelle: Confluent
Wie Sie sehen können, wird es schnell komplex. Finden Sie von Anfang an die richtigen Experten, um Ihnen zu helfen, nicht erst, nachdem Sie bereits die ersten Cluster und Anwendungen bereitgestellt haben.
Vor langer Zeit habe ich bereits in einer ausführlichen Präsentation die Architekturmuster für verteilte, hybride, Edge- und globale Apache Kafka-Bereitstellungen beschrieben. Schauen Sie sich diese Folien und die Videoaufzeichnung für weitere Details zu den Bereitstellungsoptionen und Kompromissen an.
RPO vs. RTO = Datenverlust vs. Ausfallzeit
RPO und RTO sind zwei wichtige KPIs, über die Sie diskutieren müssen, bevor Sie eine Kafka-Cluster-Strategie festlegen:
- RPO (Recovery Point Objective) ist die maximal akzeptable Menge an Datenverlust, gemessen in Zeit, und zeigt an, wie häufig Backups erfolgen sollten, um den Datenverlust zu minimieren.
- RTO (Recovery Time Objective) ist die maximal akzeptable Dauer, die benötigt wird, um die Geschäftstätigkeit nach einer Unterbrechung wiederherzustellen. Zusammen helfen sie Organisationen, ihre Daten-Backup- und Disaster-Recovery-Strategien zu planen, um Kosten und operative Auswirkungen auszugleichen.
Obwohl viele Menschen mit dem Ziel starten, RPO = 0 und RTO = 0 zu erreichen, erkennen sie schnell, wie schwierig (aber nicht unmöglich) das ist. Sie müssen entscheiden, wie viele Daten Sie im Falle eines Desasters verlieren können. Sie benötigen einen Notfallwiederherstellungsplan, wenn ein Desaster eintritt. Die Rechts- und Compliance-Teams müssen Ihnen sagen, ob es in Ordnung ist, im Falle eines Desasters einige Datensätze zu verlieren oder nicht. Diese und viele andere Herausforderungen müssen diskutiert werden, wenn Sie Ihre Kafka-Clusterstrategie bewerten.
Die Replikation zwischen Kafka-Clustern mit Tools wie MIrrorMaker oder Cluster Linking erfolgt asynchron, und RPO > 0. Nur ein gestreckter Kafka-Cluster bietet RPO = 0.
Gestreckter Kafka-Cluster: Null Datenverlust durch synchrone Replikation über Rechenzentren hinweg
Die meisten Bereitstellungen mit mehreren Kafka-Clustern nutzen die asynchrone Replikation über Rechenzentren oder Clouds mithilfe von Tools wie MirrorMaker oder Confluent Cluster Linking. Dies ist für die meisten Anwendungsfälle ausreichend. Im Falle eines Desasters gehen jedoch einige Nachrichten verloren. Die RPO beträgt > 0.
Ein gestreckter Kafka-Cluster verteilt Kafka-Broker eines einzigen Clusters über drei Rechenzentren. Die Replikation erfolgt synchron (da dies ist, wie Kafka Daten innerhalb eines Clusters repliziert) und garantiert keinen Datenverlust (RPO = 0) – selbst im Falle eines Desasters!
Warum sollten Sie nicht immer gestreckte Cluster verwenden?
- Niedrige Latenz (<~50ms) und stabile Verbindung sind zwischen Rechenzentren erforderlich.
- Drei (!) Rechenzentren sind erforderlich; zwei sind nicht ausreichend, da eine Mehrheit (Quorum) Schreib- und Lesevorgänge bestätigen muss, um die Zuverlässigkeit des Systems zu gewährleisten.
- Sie sind schwer einzurichten, zu betreiben und zu überwachen und viel schwieriger als ein Cluster, der in einem Rechenzentrum läuft.
- Kosten vs. Wert rechnen sich in vielen Anwendungsfällen nicht; während eines echten Notfalls haben die meisten Organisationen und Anwendungsfälle größere Probleme als den Verlust einiger Nachrichten (auch wenn es sich um kritische Daten wie eine Zahlung oder Bestellung handelt).
Um klar zu sein, in der öffentlichen Cloud hat eine Region normalerweise drei Rechenzentren (= Verfügbarkeitszonen). Daher hängt es in der Cloud von Ihren SLAs ab, ob eine Cloud-Region als gestreckter Cluster zählt oder nicht. Die meisten SaaS Kafka-Angebote implementieren hier einen gestreckten Cluster.
Viele Compliance-Szenarien sehen jedoch nicht ein Kafka-Cluster in einer Cloud-Region als ausreichend an, um SLAs und Geschäftskontinuität im Falle eines Notfalls zu garantieren.
Confluent hat ein dediziertes Produkt entwickelt, um (einige) dieser Herausforderungen zu lösen: Multi-Region Clusters (MRC). Es bietet Funktionen zur synchronen und asynchronen Replikation innerhalb eines gestreckten Kafka-Clusters.
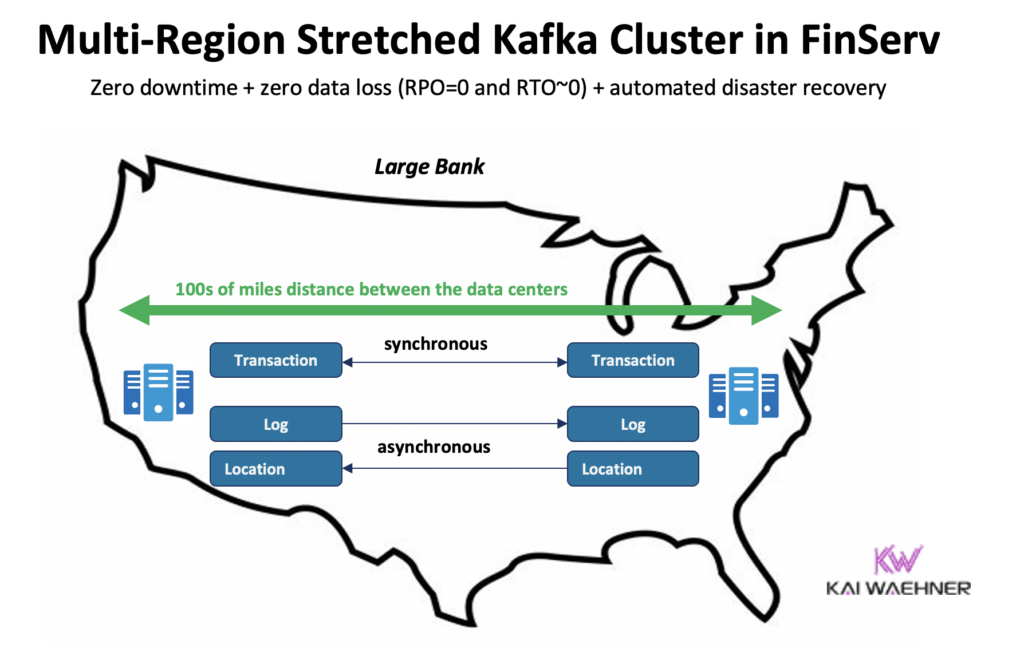
Beispielsweise repliziert MRC in einem Finanzdienstleistungsszenario kritische Transaktionen mit geringem Volumen synchron, aber Logs mit hohem Volumen asynchron:
- Verarbeitet ‚Zahlungs‘-Transaktionen, die aus den USA Ost und den USA West eingehen, mit vollständig synchroner Replikation
- ‚Log‘- und ‚Standort‘-Informationen im selben Cluster werden asynchron verwendet – optimiert für Latenz
- Automatisierte Katastrophenwiederherstellung (Null Ausfallzeit, kein Datenverlust)
Weitere Details zu gestreckten Kafka-Clustern gegenüber aktiven-aktiven / aktiven-passiven Replikationen zwischen zwei Kafka-Clustern in meiner globalen Kafka-Präsentation.
Preisgestaltung von Kafka Cloud-Angeboten (vs. Self-Managed)
Die obigen Abschnitte erläutern, warum Sie je nach Ihren Projektanforderungen verschiedene Kafka-Architekturen in Betracht ziehen müssen. Selbstverwaltete Kafka-Cluster können nach Bedarf konfiguriert werden. In der öffentlichen Cloud sehen vollständig verwaltete Angebote anders aus (genauso wie bei jedem anderen vollständig verwalteten SaaS). Die Preisgestaltung ist unterschiedlich, da SaaS-Anbieter vernünftige Grenzen konfigurieren müssen. Der Anbieter muss spezifische SLAs bereitstellen.
Die Daten-Streaming-Landschaft umfasst verschiedene Kafka-Cloud-Angebote. Hier ist ein Beispiel für die aktuellen Cloud-Angebote von Confluent, einschließlich Mehrmandanten- und dedizierten Umgebungen mit unterschiedlichen SLAs, Sicherheitsfunktionen und Kostenmodellen.
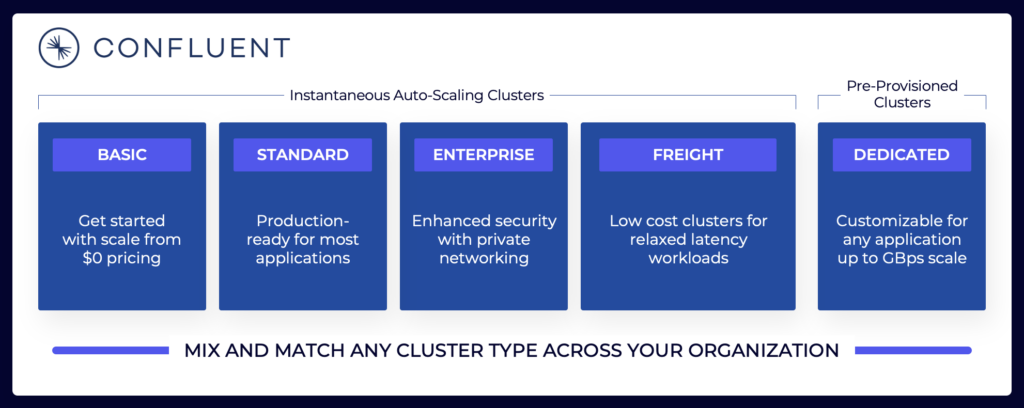 Quelle: Confluent
Quelle: Confluent
Stellen Sie sicher, dass Sie die verschiedenen Cluster-Typen verschiedener Anbieter in der öffentlichen Cloud evaluieren und verstehen, einschließlich TCO, bereitgestellter Betriebszeit SLAs, Replikationskosten zwischen Regionen oder Cloud-Anbietern usw. Die Lücken und Einschränkungen sind oft absichtlich in den Details verborgen.
Zum Beispiel, wenn Sie Amazon Managed Streaming für Apache Kafka (MSK) nutzen, sollten Sie sich darüber im Klaren sein, dass in den Geschäftsbedingungen festgelegt ist, dass „Die Service-Verpflichtung nicht für jede Nichtverfügbarkeit, Aussetzung oder Kündigung gilt… verursacht durch die zugrunde liegende Apache Kafka oder Apache Zookeeper-Engine-Software, die zu Anfragefehlern führt.“
Preisgestaltung und Support-SLAs sind jedoch nur ein kritisches Vergleichselement. Es gibt viele „build vs. buy“ Entscheidungen, die Sie als Teil der Evaluierung einer Daten-Streaming-Plattform treffen müssen.
Kafka-Speicher: Gestufter Speicher und Iceberg-Tabellenformat zur Speicherung von Daten nur einmal
Apache Kafka hat Tiered Storage hinzugefügt, um Berechnung und Speicherung zu trennen. Die Funktion ermöglicht skalierbarere, zuverlässigere und kosteneffizientere Unternehmensarchitekturen. Tiered Storage für Kafka ermöglicht einen neuen Kafka-Cluster-Typ: Speichern von Petabytes an Daten im Kafka-Commit-Log auf kostengünstige Weise (wie in Ihrem Data Lake) mit Zeitstempeln und garantierte Reihenfolge, um historische Daten zur erneuten Verarbeitung zurückzuverfolgen. KOR Financial ist ein gutes Beispiel für die Verwendung von Apache Kafka als Datenbank für Langzeitpersistenz.
Kafka ermöglicht eine Shift-Left-Architektur, um Daten nur einmal für operationale und analytische Datensätze zu speichern:

Mit diesem Gedanken im Hinterkopf sollten Sie nochmals über die oben beschriebenen Anwendungsfälle für mehrere Kafka-Cluster nachdenken. Sollten Daten immer noch batchweise im Ruhezustand von einem Rechenzentrum oder einer Cloud-Region in ein anderes in die Datenbank, den Data Lake oder das Lakehouse repliziert werden? Nein. Sie sollten die Daten in Echtzeit synchronisieren, die Daten nur einmal speichern (normalerweise in einem Objektspeicher wie Amazon S3) und dann alle analytischen Engines wie Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery und so weiter mit diesem Standardtabellenformat verbinden.
Real-World Success Stories für mehrere Kafka-Cluster
Die meisten Organisationen verfügen über mehrere Kafka-Cluster. In diesem Abschnitt werden vier Erfolgsgeschichten aus verschiedenen Branchen untersucht:
- Paypal (Finanzdienstleistungen) – USA: Sofortzahlungen, Betrugsprävention.
- JioCinema (Telco/Media) – APAC: Datenintegration, Klickstromanalyse, Werbung, Personalisierung.
- Audi (Automobil/Herstellung) – EMEA: Vernetzte Autos mit kritischen und analytischen Anforderungen.
- New Relic (Software/Cloud) – US: Beobachtbarkeit und Anwendungsleistungsmanagement (APM) weltweit.
Paypal: Trennung nach Sicherheitszone
PayPal ist eine digitale Zahlungsplattform, die es Benutzern ermöglicht, sicher und bequem weltweit in Echtzeit Geld online zu senden und zu empfangen. Dies erfordert eine skalierbare, sichere und konforme Kafka-Infrastruktur.
Während des Black Friday 2022 erreichte das Kafka-Verkehrsvolumen täglich etwa 1,3 Billionen Nachrichten. Derzeit verfügt PayPal über 85+ Kafka-Cluster, und jedes Urlaubsgeschäft verstärkt ihre Kafka-Infrastruktur, um den Verkehrsanstieg zu bewältigen. Die Kafka-Plattform skaliert nahtlos weiter, um dieses Verkehrswachstum zu unterstützen, ohne Auswirkungen auf ihr Geschäft zu haben.
Heute besteht PayPals Kafka-Flotte aus über 1.500 Brokern, die über 20.000 Themen hosten. Die Ereignisse werden zwischen den Clustern repliziert und bieten eine Verfügbarkeit von 99,99%.
Kafka-Cluster-Bereitstellungen sind in unterschiedliche Sicherheitszonen innerhalb eines Rechenzentrums aufgeteilt:
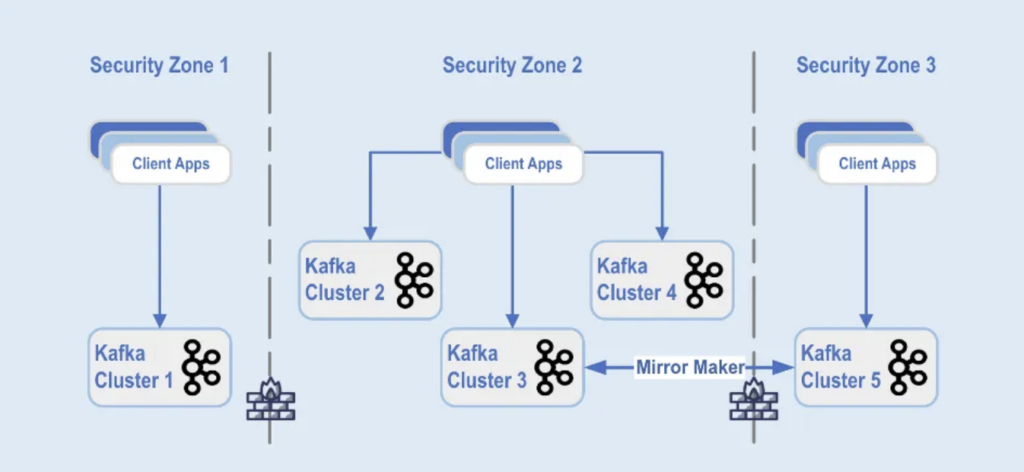 Quelle: Paypal
Quelle: Paypal
Die Kafka-Cluster sind in diesen Sicherheitszonen bereitgestellt, basierend auf Datenklassifizierung und geschäftlichen Anforderungen. Echtzeit-Replikation mit Tools wie MirrorMaker (in diesem Beispiel, das auf der Kafka-Connect-Infrastruktur läuft) oder Confluent Cluster Linking (der einen einfacheren und weniger fehleranfälligen Ansatz verwendet, der direkt das Kafka-Protokoll für die Replikation nutzt) wird verwendet, um die Daten über die Datenzentren hinweg zu spiegeln, was bei der Katastrophenwiederherstellung und zur Erreichung der Kommunikation zwischen Sicherheitszonen hilft.
JioCinema: Trennung nach Anwendungsfall und SLA
JioCinema ist eine schnell wachsende Video-Streaming-Plattform in Indien. Der Telco-OTT-Dienst ist bekannt für sein umfangreiches Content-Angebot, einschließlich Live-Sportarten wie der Indian Premier League (IPL) für Cricket, einem neu gestarteten Anime Hub und umfassenden Plänen zur Berichterstattung über große Ereignisse wie die Olympischen Spiele 2024 in Paris.
Die Datenarchitektur nutzt Apache Kafka, Flink und Spark zur Datenverarbeitung, wie auf dem Kafka Summit India 2024 in Bangalore präsentiert:
 Quelle: JioCinema
Quelle: JioCinema
Datenstreaming spielt eine entscheidende Rolle in verschiedenen Anwendungsfällen, um Benutzererfahrungen und Inhaltslieferung zu transformieren. Über zehn Millionen Nachrichten pro Sekunde verbessern Analysen, Benutzererkenntnisse und Inhaltsliefermechanismen.
Die Anwendungsfälle von JioCinema umfassen:
- Inter-Service-Kommunikation
- Klickstrom/Analysen
- Werbetracker
- Maschinenlernen und Personalisierung
Kushal Khandelwal, Leiter der Datenplattform, Analytik und Konsum bei JioCinema, erklärte, dass nicht alle Daten gleich sind und die Prioritäten sowie SLAs je nach Anwendungsfall variieren:
 Quelle: JioCinema
Quelle: JioCinema
Datenstreaming ist eine Reise. Wie viele andere Organisationen weltweit begann JioCinema mit einem großen Kafka-Cluster, das über 1000 Kafka-Themen und über 100.000 Kafka-Partitionen für verschiedene Anwendungsfälle nutzte. Im Laufe der Zeit entwickelte sich eine Trennung der Anliegen bezüglich Anwendungsfällen und SLAs zu mehreren Kafka-Clustern:
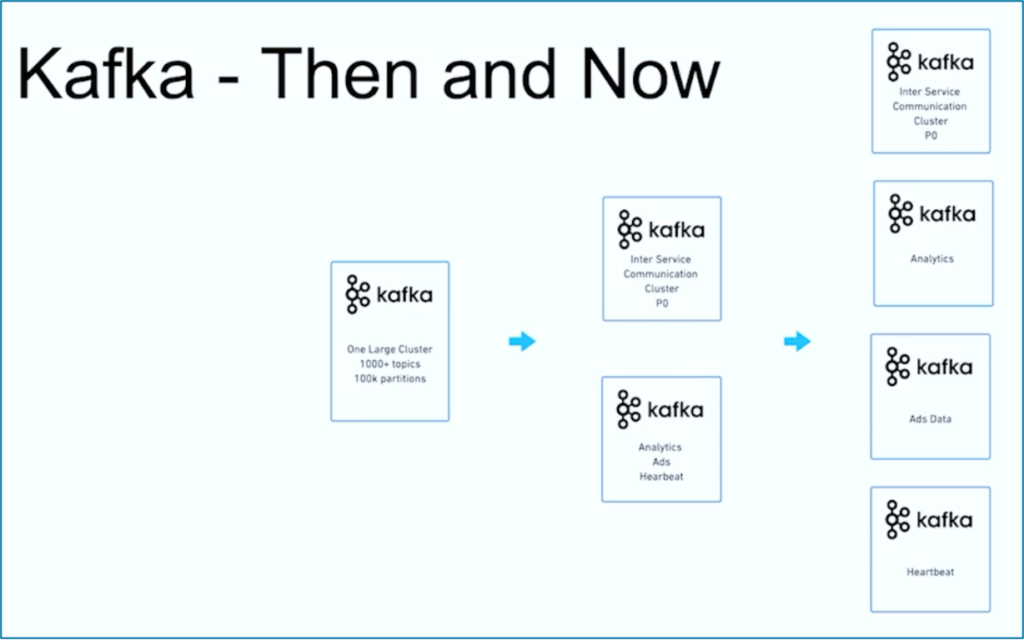 Quelle: JioCinema
Quelle: JioCinema
Die Erfolgsgeschichte von JioCinema zeigt die übliche Entwicklung einer Datenstreaming-Organisation. Lassen Sie uns nun ein weiteres Beispiel erkunden, in dem von Anfang an zwei sehr unterschiedliche Kafka-Cluster für einen Anwendungsfall bereitgestellt wurden.
Audi: Betrieb vs. Analytik für vernetzte Autos
Der Automobilhersteller Audi bietet vernetzte Autos mit fortschrittlicher Technologie an, die Internetverbindung und intelligente Systeme integriert. Die Autos von Audi ermöglichen eine Navigation in Echtzeit, Ferndiagnosen und eine verbesserte Unterhaltung im Auto. Diese Fahrzeuge sind mit Audi Connect-Diensten ausgestattet. Die Funktionen umfassen Notrufe, Online-Verkehrsinformationen und die Integration mit Smart-Home-Geräten, um Komfort und Sicherheit für Fahrer zu erhöhen.
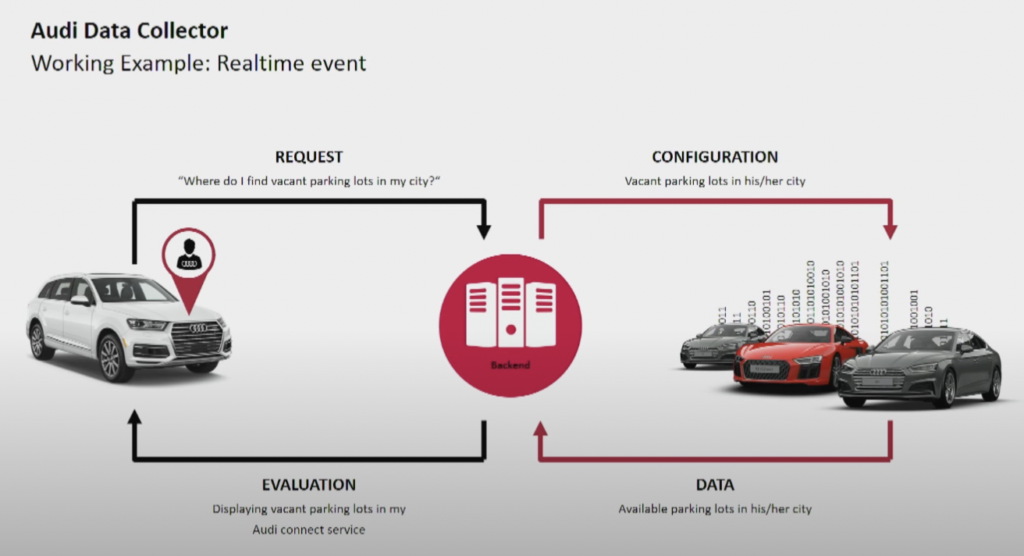 Quelle: Audi
Quelle: Audi
Audi stellte seine Architektur für vernetzte Autos in der Keynote des Kafka Summit 2018 vor. Die Unternehmensarchitektur von Audi basiert auf zwei Kafka-Clustern mit sehr unterschiedlichen SLAs und Anwendungsfällen.
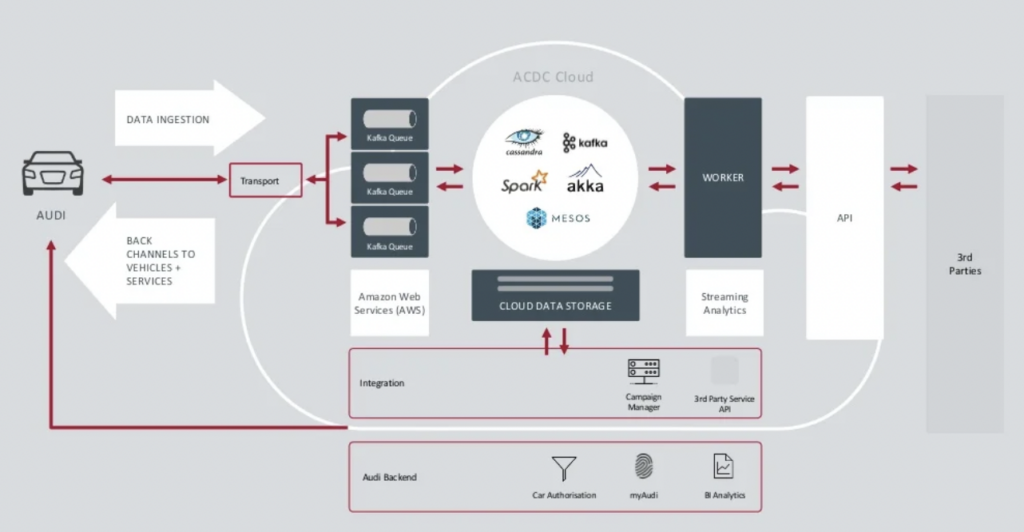 Quelle: Audi
Quelle: Audi
Der Data Ingestion Kafka-Cluster ist sehr kritisch.Er muss rund um die Uhr im großen Maßstab laufen. Er stellt die letzte Verbindung zu Millionen von Autos über Kafka und MQTT her. Rückkanäle von der IT-Seite zum Fahrzeug unterstützen die Servicekommunikation und Over-the-Air-Updates (OTA).
ACDC Cloud ist der Analytics Kafka-Cluster der vernetzten Fahrzeugarchitektur von Audi. Der Cluster bildet die Grundlage für viele analytische Workloads, die riesige Datenmengen aus dem IoT und Protokolldaten im großen Maßstab mit Batch-Verarbeitungs-Frameworks wie Apache Spark verarbeiten.
Diese Architektur wurde bereits 2018 vorgestellt. Der Slogan von Audi, „Fortschritt durch Technik“, zeigt, wie das Unternehmen neue Technologien für Innovationen einsetzte, lange bevor die meisten Automobilhersteller ähnliche Szenarien implementierten. Alle Sensordaten von vernetzten Autos werden in Echtzeit verarbeitet und für die historische Analyse und Berichterstattung gespeichert.
New Relic: Weltweite Multi-Cloud-Beobachtbarkeit
New Relic ist eine cloudbasierte Beobachtbarkeitsplattform, die Echtzeit-Leistungsüberwachung und -analyse für Anwendungen und Infrastrukturen für Kunden auf der ganzen Welt bietet.
Andrew Hartnett, VP of Software Engineering bei New Relic, erklärt, wie die Datenströmung für das gesamte Geschäftsmodell von New Relic entscheidend ist:
„Kafka ist unser zentrales Nervensystem. Es ist ein Teil von allem, was wir tun. Die meisten Services über 110 verschiedene Engineering-Teams mit Hunderten von Services berühren auf die eine oder andere Weise Kafka in unserem Unternehmen, daher ist es wirklich geschäftskritisch. Was wir gesucht haben, ist die Möglichkeit zu wachsen, und Confluent Cloud hat das ermöglicht.“
New Relic verarbeitet bis zu 7 Milliarden Datenpunkte pro Minute und soll bis 2023 voraussichtlich 2,5 Exabyte an Daten verarbeiten. Während New Relic seine Multi-Cloud-Strategien ausweitet, werden Teams Confluent Cloud für eine einheitliche Übersicht über alle Umgebungen nutzen.
„New Relic ist Multi-Cloud. Wir möchten dort sein, wo unsere Kunden sind. Wir möchten in denselben Umgebungen, in denselben Regionen sein und wir wollten unser Kafka dort bei uns haben.“ sagt Artnett in einer Confluent-Fallstudie.
Mehrere Kafka-Cluster sind die Norm, keine Ausnahme
Event-getriebene Architekturen und Stream-Verarbeitung existieren seit Jahrzehnten. Die Akzeptanz wächst mit Open-Source-Frameworks wie Apache Kafka und Flink in Kombination mit vollständig verwalteten Cloud-Services. Immer mehr Organisationen kämpfen mit ihrem Kafka-Maßstab. Unternehmensweite Datenverwaltung, Zentrum für Exzellenz, Automatisierung von Bereitstellung und Betrieb sowie bewährte Best Practices der Unternehmensarchitektur helfen dabei, Datenstreaming erfolgreich mit mehreren Kafka-Clustern für unabhängige oder zusammenarbeitende Geschäftsbereiche bereitzustellen.
Mehrere Kafka-Cluster sind die Norm, nicht die Ausnahme. Anwendungsfälle wie Hybridintegration, Notfallwiederherstellung, Migration oder Aggregation ermöglichen Echtzeit-Datenstrom überall mit den erforderlichen SLAs.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies