













Jede datengesteuerte Organisation hat betriebliche und analytische Workloads. Ein Best-of-Breed-Ansatz entsteht mit verschiedenen Datenplattformen, einschließlich Daten-Streaming, Data Lake, Data Warehouse und Lakehouse-Lösungen sowie Cloud-Diensten. Ein offenes Tabellenformat-Framework wie Apache Iceberg ist in der Enterprise-Architektur entscheidend, um zuverlässiges Datenmanagement und -teilung, nahtlose Schemavorentwicklung, effiziente Handhabung großer Datensätze und kostengünstige Speicherung zu gewährleisten, während starke Unterstützung für ACID-Transaktionen und Zeitreisenabfragen geboten wird.
Dieser Artikel untersucht Markttrends; die Adoption von Tabellenformat-Frameworks wie Iceberg, Hudi, Paimon, Delta Lake und XTable; sowie die Produktstrategie einiger führender Anbieter von Datenplattformen wie Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena und Google BigQuery.
Was ist ein offenes Tabellenformat für eine Datenplattform?
Ein offenes Tabellenformat hilft dabei, die Datenintegrität zu erhalten, die Abfragleistung zu optimieren und sicherzustellen, dass die in der Plattform gespeicherten Daten klar verstanden werden.
Das offene Tabellenformat für Datenplattformen umfasst typischerweise eine gut definierte Struktur mit spezifischen Komponenten, die sicherstellen, dass die Daten organisiert, zugänglich und einfach abfragbar sind. Ein typisches Tabellenformat enthält einen Tabellennamen, Spaltennamen, Datentypen, Primär- und Fremdschlüssel, Indizes und Constraints.
Dies ist kein neuer Begriff. Deine Lieblingsdatenbank aus den letzten Jahrzehnten — wie Oracle, IBM DB2 (sogar auf dem Mainframe) oder PostgreSQL — nutzt die gleichen Prinzipien. Allerdings haben sich die Anforderungen und Herausforderungen etwas für Cloud-Datenbanken, Datenseen und Lakehouses in Bezug auf Skalierbarkeit, Leistung und Abfragemöglichkeiten geändert.
Vorteile eines „Lakehouse-Tabellenformats“ wie Apache Iceberg
Jeder Teil einer Organisation wird datengesteuert. Die Konsequenz sind extensive Datensätze, Datenfreigabe mit Datenprodukten über Geschäftseinheiten hinweg und neue Anforderungen an die Datenverarbeitung in nahezu Echtzeit.
Apache Iceberg bietet viele Vorteile für die Enterprise-Architektur:
- Einzelne Speicherung: Daten werden einmal gespeichert (aus verschiedenen Datenquellen stammend), was Kosten und Komplexität reduziert
- Interoperabilität: Zugriff ohne Integrationsaufwand von jeder analytischen Engine
- Alle Daten: Verknüpfung von operativen und analytischen Workloads (Transaktionssysteme, Big-Data-Logs/IoT/Clickstream, mobile APIs, Drittanbieter-B2B-Schnittstellen, etc.)
- Anbieterunabhängigkeit: Arbeit mit jeder bevorzugten Analytik-Engine (egal ob nahe Echtzeit, Batch oder API-basiert)
Apache Hudi und Delta Lake bieten die gleichen Merkmale. Allerdings wird Delta Lake hauptsächlich von Databricks als einzelnem Anbieter vorangetrieben.
Tabellenformat und Katalog-Schnittstelle
Es ist wichtig zu verstehen, dass Diskussionen über Apache Iceberg oder ähnliche Tabellenformat-Frameworks zwei Konzepte umfassen: Tabellenformat und Katalog-Schnittstelle! Als Endbenutzer der Technologie benötigen Sie beides!
Das Apache Iceberg-Projekt implementiert das Format, aber stellt nur eine Spezifikation (aber keine Implementierung) für den Katalog bereit:
- Das Tabellenformat definiert, wie Daten in einer Tabelle organisiert, gespeichert und verwaltet werden.
- Die Katalog-Schnittstelle verwaltet die Metadaten für Tabellen und bietet eine Abstraktionsebene für den Zugriff auf Tabellen in einem Data Lake.
Die Apache Iceberg-Dokumentation untersucht die Konzepte viel detaillierter, basierend auf diesem Diagramm:
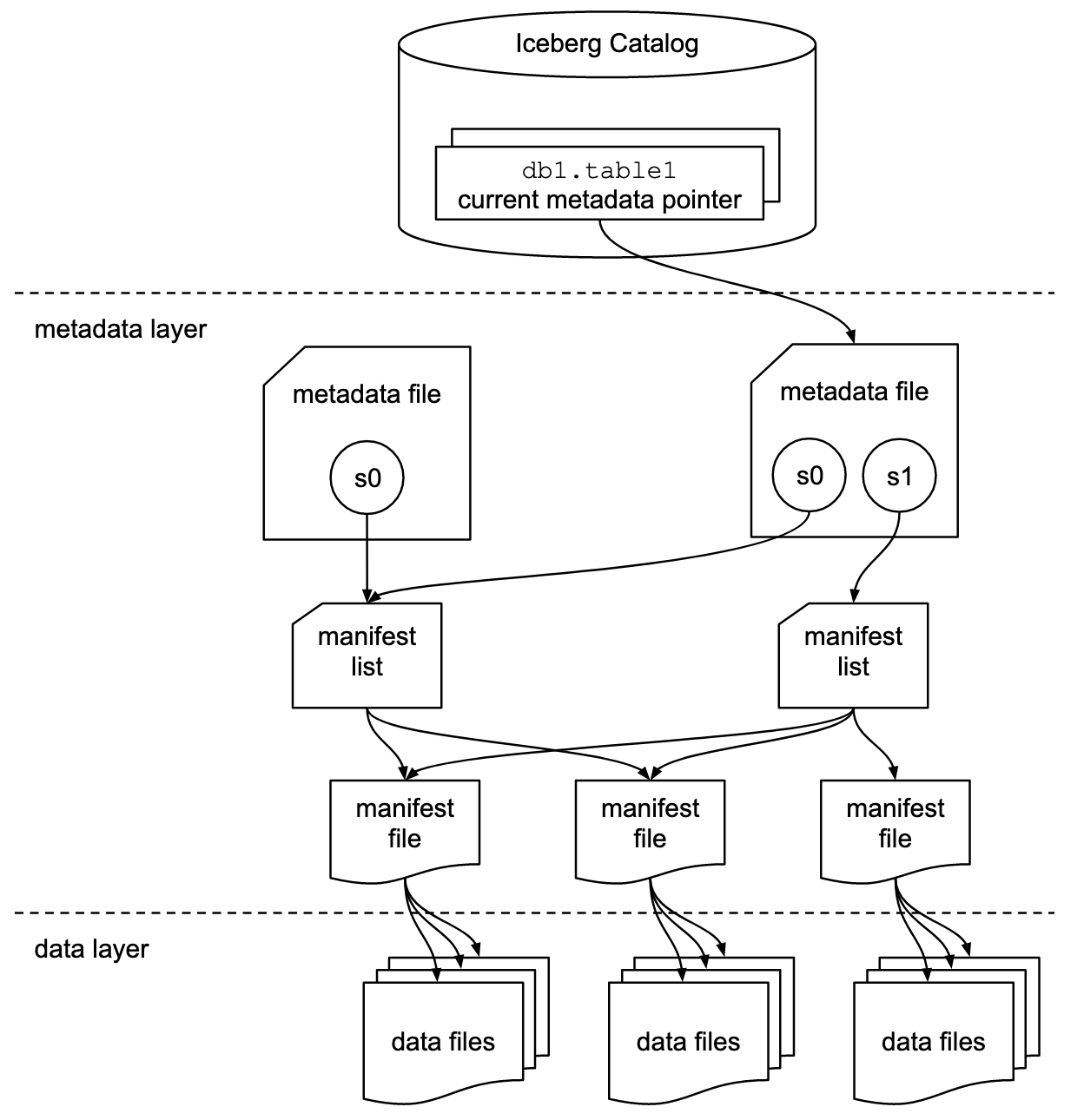
Organisationen verwenden verschiedene Implementierungen für Icebergs Katalog-Schnittstelle. Jede integriert sich mit verschiedenen Metadaten-Speichern und -Diensten. Wichtige Implementierungen umfassen:
- Hadoop-Katalog: Verwendet das Hadoop Distributed File System (HDFS) oder andere kompatible Dateisysteme zur Speicherung von Metadaten. Geeignet für Umgebungen, die bereits Hadoop verwenden.
- Hive-Katalog: Integriert sich mit dem Apache Hive Metastore zur Verwaltung von Tabellenmetadaten. Ideal für Benutzer, die Hive für ihre Metadatenverwaltung nutzen.
- AWS Glue-Katalog: Verwendet den AWS Glue Data Catalog zur Speicherung von Metadaten. Entworfen für Benutzer, die im AWS-Ökosystem operieren.
- REST-Katalog: Bietet eine RESTful-Schnittstelle für Katalogoperationen über HTTP. Ermöglicht die Integration mit benutzerdefinierten oder Drittanbieter-Metadaten-Diensten.
- Nessie-Katalog: Nutzt Projekt Nessie, das eine Git-ähnliche Erfahrung für das Management von Daten bietet.
Der Schwung und die wachsende Adoption von Apache Iceberg motivieren viele Datenplattformanbieter, ihren eigenen Iceberg-Katalog zu implementieren. Ich diskutiere einige Strategien in der folgenden Sektion über Datenplattform- und Cloud-Anbieterstrategien, einschließlich Snowflakes Polaris, Databricks‘ Unity und Confluent’s Tableflow.
Erste-Klasse Iceberg-Unterstützung vs. Iceberg-Connector
Bitte beachten Sie, dass die Unterstützung von Apache Iceberg (oder Hudi/Delta Lake) weit mehr bedeutet als nur die Bereitstellung eines Connectors und der Integration mit dem Tabellenformat über API. Anbieter und Cloud-Dienste differenzieren sich durch erweiterte Funktionen wie automatische Abbildung zwischen Datenformaten, kritische SLAs, Zeitreisen, intuitive Benutzeroberflächen und so weiter.
Sehen wir uns ein Beispiel an: Integration zwischen Apache Kafka und Iceberg. Verschiedene Kafka Connect Connectors wurden bereits implementiert. Allerdings gibt es hier die Vorteile einer erstklassigen Integration mit Iceberg (z.B. Confluent’s Tableflow) im Vergleich zur Nutzung eines Kafka Connect Connectors:
- Keine Connector-Konfiguration
- Keine Konsumation über Connector
- Integrierte Wartung (Komprimierung, Müllabfuhr, Snapshot-Management)
- Automatische Schemaveränderung
- Synchronisation mit externem Katalog-Dienst
- Einfachere Operationen (in einer vollständig verwalteten SaaS-Lösung ist sie serverlos und erfordert keine Skalierung oder Operationen durch den Endbenutzer)
Ähnliche Vorteile gelten auch für andere Datenplattformen und potenzielle erstklassige Integration im Vergleich zur Bereitstellung einfacher Connector.
Offenes Tabellenformat für einen Data Lake/Lakehouse mit Apache Iceberg, Apache Hudi und Delta Lake
Das allgemeine Ziel von Tabellenformat-Frameworks wie Apache Iceberg, Apache Hudi und Delta Lake ist es, die Funktionalität und Zuverlässigkeit von Data Lakes zu verbessern, indem sie sich mit häufigen Herausforderungen beim Management großer Datenmengen befassen. Diese Frameworks helfen dabei:
- Verbesserung des Datenmanagements
- Erleichterung der Handhabung von Dateningest, Speicherung und Abruf in Data Lakes.
- Effiziente Datenorganisation und Speicherung, die bessere Leistung und Skalierbarkeit unterstützen.
- Sicherstellung der Datenkonsistenz
- Bereitstellung von Mechanismen für ACID-Transaktionen, die sicherstellen, dass die Daten auch während gleichzeitiger Lese- und Schreiboperationen konsistent und zuverlässig bleiben.
- Unterstützung der Snapshots-Isolation, die es Benutzern ermöglicht, einen konsistenten Datenzustand zu einem beliebigen Zeitpunkt zu betrachten.
- Unterstützt Schemavorentwicklung
- Ermöglicht Änderungen an der Datenstruktur (wie Hinzufügen, Umbenennen oder Entfernen von Spalten), ohne bestehende Daten zu stören oder komplexe Migrationen zu erfordern.
- Optimiert die Abfragemethodik
- Implementiert fortgeschrittene Indexierungs- und Partitionierungsstrategien, um die Geschwindigkeit und Effizienz von Datenabfragen zu verbessern.
- Ermöglicht effizientes Metadatenmanagement, um große Datensätze und komplexe Abfragen effektiv zu handhaben.
- Verbessert die Datenverwaltung
- Bietet Werkzeuge zur besseren Verfolgung und Verwaltung von Datenabstammung, Versionierung und Auditierung, die entscheidend für die Aufrechterhaltung der Datenqualität und Konformität sind.
Durch die Bearbeitung dieser Ziele helfen Tabellenformat-Frameworks wie Apache Iceberg, Apache Hudi und Delta Lake Organisationen dabei, robustere, skalierbare und zuverlässigere Datenseen und Lakehouses zu构建. Dateningenieure, Datenwissenschaftler und Geschäftsanalysten nutzen Analytik-, AI/ML- oder Berichts/Visualisierungstools auf top der Tabellenformate, um große Datenmengen zu verwalten und zu analysieren.
Vergleich von Apache Iceberg, Hudi, Paimon und Delta Lake
Ich werde hier keinen Vergleich der Tabellenformat-Frameworks Apache Iceberg, Apache Hudi, Apache Paimon und Delta Lake vornehmen. Viele Experten haben bereits darüber geschrieben. Jedes Tabellenformat-Framework hat einzigartige Stärken und Vorteile. Aber monatliche Updates sind erforderlich, aufgrund der schnellen Evolution und Innovation, die neue Verbesserungen und Fähigkeiten innerhalb dieser Frameworks hinzufügen.
Hier ist eine Zusammenfassung dessen, was ich in verschiedenen Blogposts über die vier Optionen sehe:
- Apache Iceberg: Bewährt sich in der Schema- und Partitionsentwicklung, effizienter Metadatenverwaltung und breiter Kompatibilität mit verschiedenen Datenverarbeitungsmotoren.
- Apache Hudi: Am besten geeignet für Echtzeit-Dateningest und Upserts, mit starker Fähigkeit zur Änderungsdatenerfassung und Datenversionierung.
- Apache Paimon: Ein Seeformat, das den Aufbau einer Echtzeit-Lakehouse-Architektur mit Flink und Spark für both Streaming- und Batch-Operationen ermöglicht.
- Delta Lake: Bietet robuste ACID-Transaktionen, Schemaregelung und Zeitreisenfunktionen, was es ideal für die Aufrechterhaltung der Datenqualität und -integrität macht.
Ein entscheidender Wendepunkt könnte sein, dass Delta Lake nicht von einer breiten Gemeinschaft wie Iceberg und Hudi vorangetrieben wird, sondern hauptsächlich von Databricks als einem einzigen Anbieter dahinter.
Apache XTable als interoperables Cross-Table Framework, das Iceberg, Hudi und Delta Lake unterstützt
Benutzer haben viele Möglichkeiten. XTable, ehemals als OneTable bekannt, ist eine weitere inkubierende Tabellenstruktur unter der Apache Open-Source-Lizenz, die eine nahtlose Interoperabilität zwischen Apache Hudi, Delta Lake und Apache Iceberg ermöglicht.
Apache XTable:
- Stellt omnidirektionale Interoperabilität zwischen Tabellenformaten in Data Lakes bereit.
- Ist kein neues oder separates Format. Apache XTable bietet Abstraktionen und Werkzeuge für die Übersetzung von Metadaten der Tabellenformate in Data Lakes.
Vielleicht ist Apache XTable die Antwort, um Optionen für spezifische Datenplattformen und Cloud-Anbieter zu bieten, während gleichzeitig einfache Integration und Interoperabilität ermöglicht wird.
Achten Sie jedoch: Eine Wrapper-Schicht über verschiedene Technologien ist kein Silber bullet. Das haben wir vor Jahren gesehen, als Apache Beam aufkam. Apache Beam ist ein quelloffenes, vereinheitlichtes Modell und ein Satz von sprachspezifischen SDKs zur Definition und Ausführung von Data-Ingestion- und Data-Processing-Workflows. Es unterstützt eine Vielzahl von Stream-Processing-Engines wie Flink, Spark und Samza. Der Hauptinitiator hinter Apache Beam ist Google, der die Migrations-Workflows in Google Cloud Dataflow ermöglicht. Allerdings sind die Einschränkungen riesig, da ein solcher Wrapper den kleinsten gemeinsamen Nenner der unterstützten Funktionen finden muss. Und der Hauptvorteil der meisten Frameworks sind die 20%, die in einen solchen Wrapper nicht passen. Aus diesen Gründen unterstützt Kafka Streams absichtlich nicht Apache Beam, weil es zu viele designbezogene Einschränkungen bedeutet hätte.
Markteinführung von Tabellenformat-Frameworks
Zunächst einmal befinden wir uns noch in den Anfangsphasen. Wir sind noch am Innovationsauslöser im Sinne des Gartner Hype Cycle, der sich dem Gipfel der übertriebenen Erwartungen nähert. Die meisten Organisationen evaluieren diese Tabellenformate noch, haben sie aber noch nicht im Produktionsbetrieb Across the Organization übernommen.
Zeitsprung zurück: Der Containerkrieg zwischen Kubernetes, Mesosphere und Cloud Foundry
Die Debatte um Apache Iceberg erinnert mich an die Container Kriege vor ein paar Jahren. Der Begriff „Container Kriege“ bezieht sich auf den Wettbewerb und die Rivalität zwischen verschiedenen Containerisierungs-Technologien und -Plattformen im Bereich der Softwareentwicklung und IT-Infrastruktur.
Die drei konkurrierenden Technologien waren Kubernetes, Mesosphere und Cloud Foundry. Hier ist, wie es gelaufen ist:

Cloud Foundry und Mesosphere waren früh dran, aber Kubernetes hat toch den Kampf gewonnen. Warum? Ich habe niemals alle technischen Details und Unterschiede verstanden. Am Ende, wenn die drei Frameworks ziemlich ähnlich sind, dann dreht sich alles um:
- Community-Adoption
- Richitige Timing von Feature-Veröffentlichungen
- Gutes Marketing
- Glück
- Und einige andere Faktoren
Aber es ist gut für die Softwarebranche, wenn es ein führendes Open-Source-Framework gibt, auf dem Lösungen und Geschäftsmodelle aufgebaut werden können, anstatt dass drei konkurrieren.
Jetzt: Der Table Format Wars von Apache Iceberg vs. Hudi vs. Delta Lake
Natürlich ist Google Trends keine statistische Beweisführung oder eine anspruchsvolle Forschung. Aber ich habe es in der Vergangenheit oft als intuitives, einfaches, kostenloses Werkzeug zur Analyse von Markttrends verwendet. Daher habe ich dieses Tool auch verwendet, um zu sehen, ob Google-Suchen mit meiner persönlichen Erfahrung der Marktannahme von Apache Iceberg, Hudi und Delta Lake (Apache XTable ist noch zu klein, um hinzugefügt zu werden) übereinstimmen:
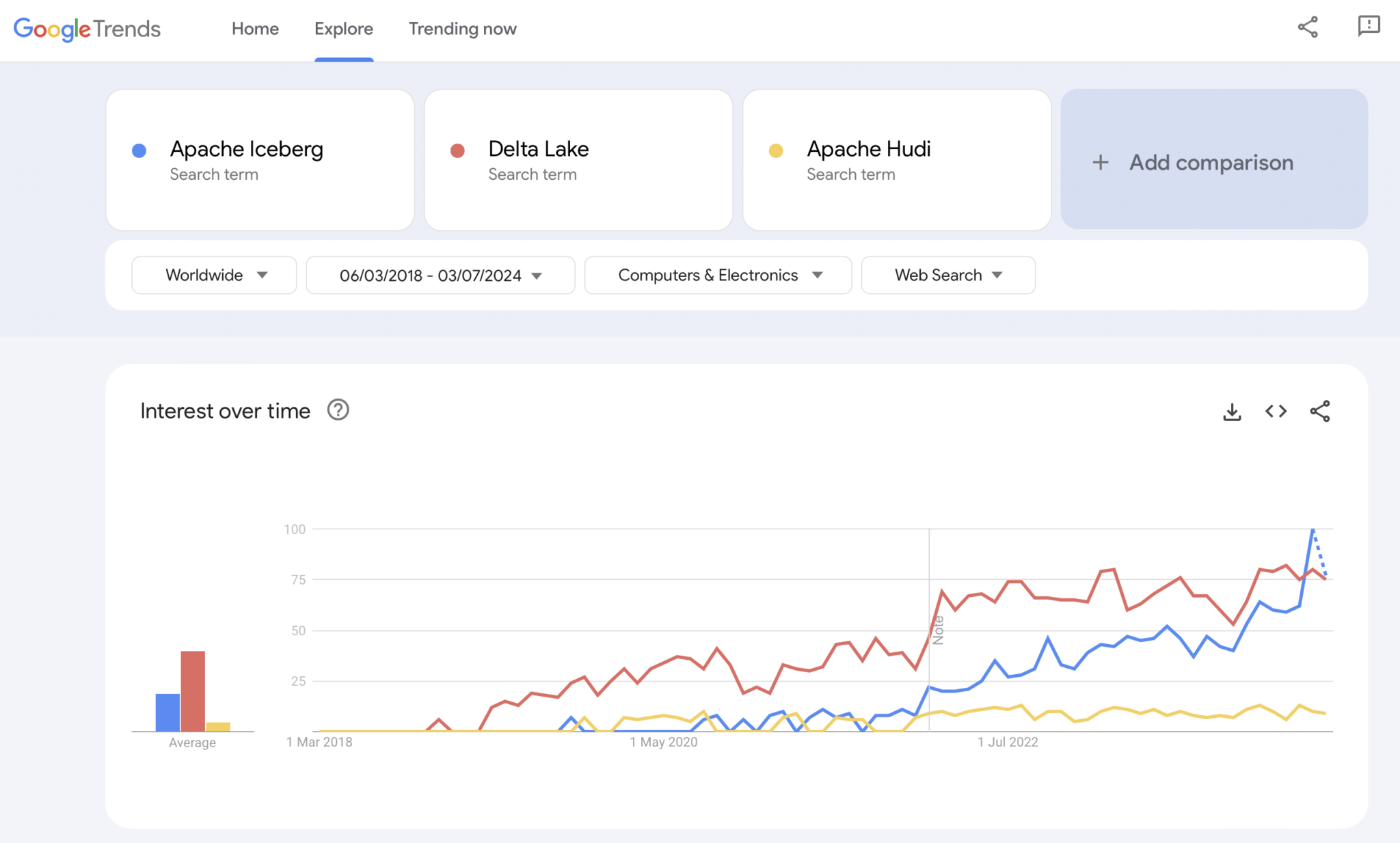
Wir sehen offensichtlich ein ähnliches Muster wie bei den Container-Kriegen vor einigen Jahren. Ich habe keine Ahnung, wohin das führt. Und ob eine Technologie gewinnt oder ob die Frameworks sich genug unterscheiden, um zu beweisen, dass es kein Silver Bullet gibt, das wird die Zukunft uns zeigen.
Meine persönliche Meinung? Ich denke, Apache Iceberg wird das Rennen gewinnen. Warum? Ich kann keine technischen Gründe anführen. Ich sehe nur, dass immer mehr Kunden aus allen Branchen darüber sprechen. Und immer mehr Anbieter beginnen es zu unterstützen. Aber wir werden sehen. Eigentlich ist es mir egal, wer gewinnt. Dennoch, ähnlich wie bei den Containerkriegen, denke ich, dass es gut ist, einen einheitlichen Standard zu haben und dass sich Anbieter mit Funktionen darum unterscheiden, ähnlich wie bei Kubernetes.
Aber mit diesem Gedanken wollen wir die aktuelle Strategie der führenden Datenplattformen und Cloud-Anbieter hinsichtlich der Unterstützung von Tabellenformaten in ihren Plattformen und Cloud-Diensten erkunden.
Strategien der Datenplattformen und Cloud-Anbieter für Apache Iceberg
In diesem Abschnitt werde ich keine Spekulationen anstellen. Die Entwicklung der Tabellenformat-Frameworks schreitet schnell voran, und die Strategien der Anbieter ändern sich schnell. Bitte konsultieren Sie die Websites der Anbieter für die neuesten Informationen. Hier ist der Status quo bezüglich der Strategien der Datenplattformen und Cloud-Anbieter hinsichtlich der Unterstützung und Integration von Apache Iceberg.
- Snowflake:
- Unterstützt Apache Iceberg schon seit einiger Zeit
- Regelmäßige Verbesserung der Integration und Hinzufügen neuer Funktionen
- Interne und externe Speicheroptionen (mit Kompromissen) wie Snowflakes Speicher oder Amazon S3
- Hat Polaris angekündigt, eine Open-Source-Katalogimplementierung für Iceberg, mit dem Engagement zur Unterstützung einer gemeinschaftsgetriebenen, anbieterneutralen bidirektionalen Integration
- Databricks:
- Fokus auf Delta Lake als Tabellenformat und (nun als Open Source verfügbare) Unity als Katalog
- Übernahme von Tabular, dem führenden Unternehmen hinter Apache Iceberg
- Unklare zukünftige Strategie zur Unterstützung der offenen Iceberg-Schnittstelle (in beide Richtungen) oder nur zum Übertragen von Daten in seine Lakehouse-Plattform und Technologien wie Delta Lake und Unity Catalog
- Confluent:
- Integriert Apache Iceberg als erstklassigen Bürger in seine Daten-Streaming-Plattform (das Produkt heißt Tableflow)
- Verwandelt ein Kafka-Thema und verwandte Schemametadaten (d.h. Datenvertrag) in eine Iceberg-Tabelle
- Bidirektionale Integration zwischen operativen und analytischen Workloads
- Analytics mit eingebettetem serverlosem Flink und seiner unified Batch- und Streaming-API oder Datenfreigabe mit Drittanbieter-Analyse-Engines wie Snowflake, Databricks oder Amazon Athena
- Mehr Datenplattformen und Open-Source-Analyse-Engines:
- Die Liste der Technologien und Cloud-Dienste, die Iceberg unterstützen, wächst jeden Monat
- Einige Beispiele: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst, der Trino (früher PrestoSQL) verwendet, Cloudera, der Impala verwendet, Imply, der Apache Druid verwendet, Fivetran
- Cloud-Diensteanbieter (AWS, Azure, Google Cloud, Alibaba):
- Unterschiedliche Strategien und Integrationen, aber alle Cloud-Anbieter erhöhen diese Tage die Iceberg-Unterstützung über ihre Dienste hinweg, zum Beispiel:
- Objektspeicher: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Kataloge: Cloud-spezifisch wie AWS Glue Catalog oder herstellerunabhängig wie Project Nessie oder Hive Catalog
- Analytics: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- Unterschiedliche Strategien und Integrationen, aber alle Cloud-Anbieter erhöhen diese Tage die Iceberg-Unterstützung über ihre Dienste hinweg, zum Beispiel:
Shift Left Architecture Mit Kafka, Flink und Iceberg zur Vereinigung von operativen und analytischen Workloads
Die Shift Left Architektur verlagert die Datenverarbeitung näher an die Datenquelle, indem sie Echtzeit-Datenströmungstechnologien wie Apache Kafka und Flink nutzt, um Daten direkt nach der Aufnahme in Bewegung zu verarbeiten. Dieser Ansatz verringert die Latenz und verbessert die Datenkonsistenz und Datenqualität.
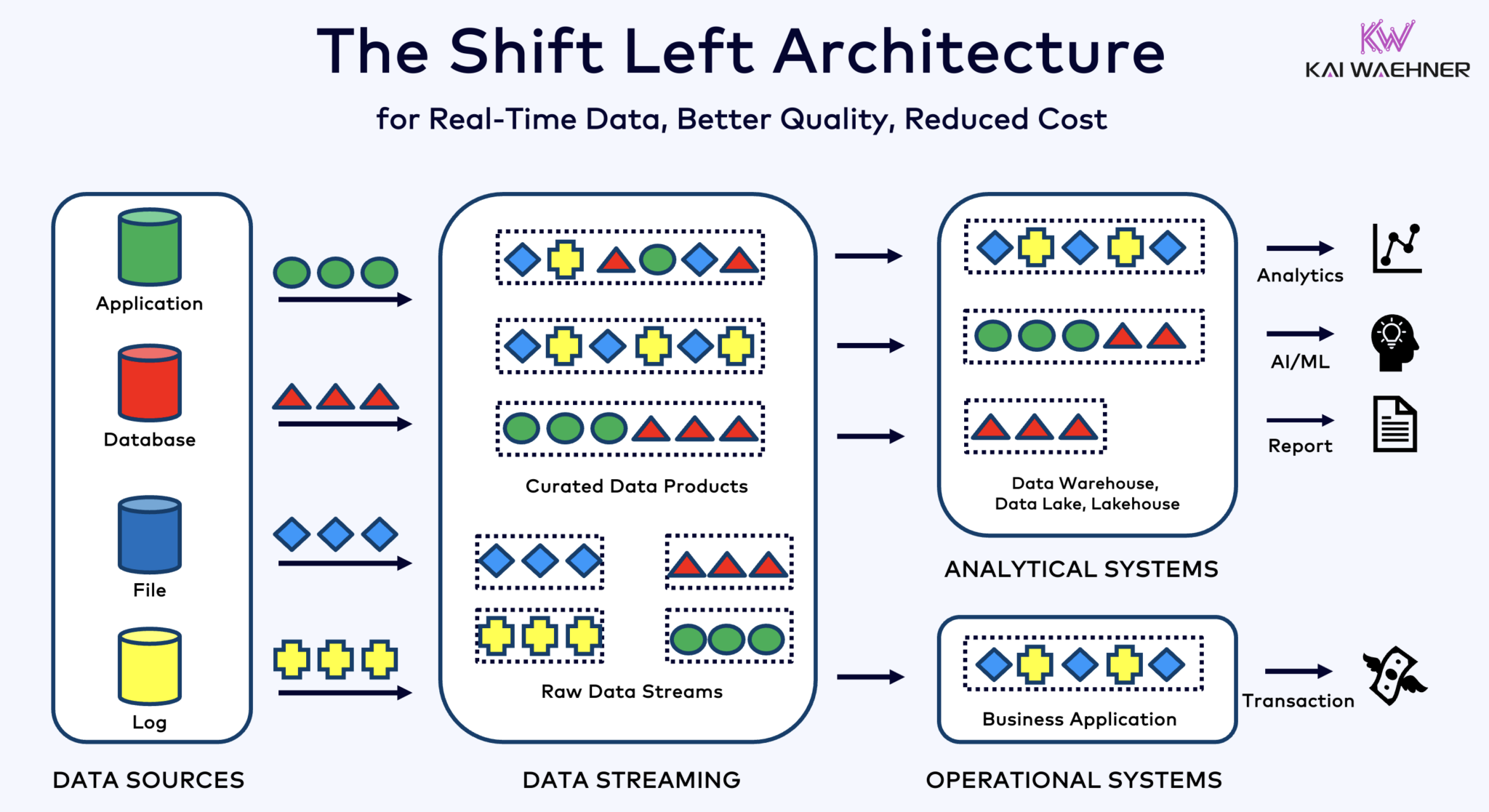
Im Gegensatz zu ETL und ELT, die Batch-Verarbeitung mit ruhend gelagerten Daten beinhalten, ermöglicht die Shift Left Architektur die Echtzeit-Erfassung und Transformation von Daten. Sie steht im Einklang mit dem Zero-ETL-Konzept, indem Daten sofort nutzbar gemacht werden. Aber im Gegensatz zu Zero-ETL verlagert das Verschieben der Datenverarbeitung zur linken Seite der Unternehmensarchitektur eine komplexe, schwer zu wartende Spaghetti-Architektur mit vielen Punkt-zu-Punkt-Verbindungen.
Die Shift-Left-Architektur verringert auch die Notwendigkeit von Reverse ETL, indem sie sicherstellt, dass Daten in Echtzeit handhabbar sind für sowohl operative als auch analytische Systeme. Insgesamt verbessert diese Architektur die Datenfrische, reduziert Kosten und beschleunigt die Time-to-Market für datengesteuerte Anwendungen. Erfahren Sie mehr über dieses Konzept in meinem Blogbeitrag über „Die Shift-Left-Architektur.“
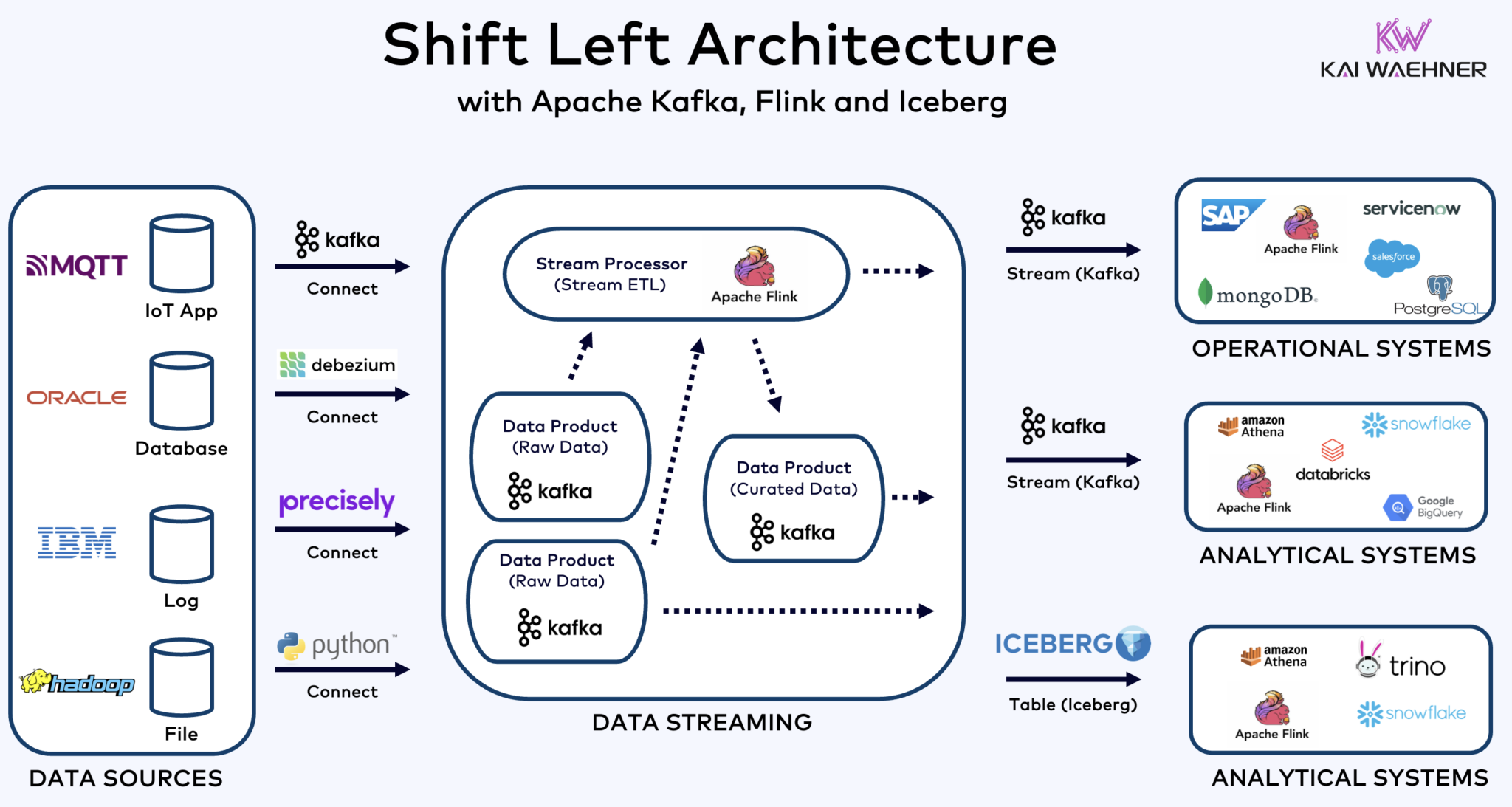
Apache Iceberg als offenes Tabellenformat und Katalog für nahtloses Daten-Sharing Across Analytics Engines
Ein offenes Tabellenformat und Katalog führt enorme Vorteile in die Unternehmensarchitektur ein:
- Interoperabilität
- Freiheit der Wahl der Analytics-Engines
- Schnellere Time-to-Market
- Reduzierte Kosten
Apache Iceberg scheint zum neuen的事实标准 across Anbieter und Cloud-Anbieter zu werden. Allerdings befindet es sich noch in einem frühen Stadium und konkurrierende und umhüllende Technologien wie Apache Hudi, Apache Paimon, Delta Lake und Apache XTable versuchen ebenfalls, Momentum zu gewinnen.
Eisberg und andere offene Tabellenformate sind nicht nur ein großer Gewinn für die einzelne Speicherung und Integration mit mehreren Analytics-/Data-/AI/ML-Plattformen wie Snowflake, Databricks, Google BigQuery und anderen, sondern auch für die Vereinigung von operativen und analytischen Workloads durch Datenströme mit Technologien wie Apache Kafka und Flink. Die Shift-left-Architektur bringt bedeutende Vorteile, um Anstrengungen zu reduzieren, die Datenqualität und -konsistenz zu verbessern und Echtzeit- statt Batch-Anwendungen und Einblicke zu ermöglichen.
Schließlich, wenn du dich immer noch fragst, was die Unterschiede zwischen Datenströmen und Data-Lakehouses (und wie sie sich ergänzen) sind, schau dir dieses zehnminütige Video an:
Welche Tabelleformatstrategie verfolgst du? Welche Technologien und Cloud-Dienste verbindest du? Lassen wir uns über LinkedIn verbinden und darüber diskutieren!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming