













AWS Lambda is a powerful serverless compute service that enables you to run code without managing infrastructure, so you can focus solely on writing code without worrying about provisioning or maintaining servers.
In this tutorial, we will explore AWS Lambda, from setting up your first function to integrating it with other AWS services. Whether you’re processing data streams or building APIs, this guide will help you get started with serverless deployments using AWS Lambda.
What is AWS Lambda?
AWS Lambda is a serverless computing platform provided by Amazon Web Services (AWS) that allows developers to run code without provisioning or managing servers. AWS Lambda facilitates this by dynamically allocating resources to execute your functions only when needed, charging you based on usage rather than pre-allocated server capacity.
This approach to application development removes the need for traditional infrastructure setup, enabling you to focus solely on writing and deploying code.
AWS Lambda is event-driven, meaning it is triggered by specific events from other AWS services, making it ideal for building responsive, scalable, and cost-efficient solutions.
Traditional deployment methods require setting up and managing servers, which involves scaling, updating, and patching. These tasks can be time-consuming, costly, and less efficient for sporadic workloads. In contrast, serverless deployment eliminates these overheads, offering automatic scaling and high availability out of the box.
Features of AWS Lambda
- Event-driven architecture: AWS Lambda functions are invoked in response to events such as changes in data, HTTP requests, or updates to AWS resources.
- Multiple runtime support: Lambda supports various runtimes, including Python, Node.js, Java, Go, Ruby, and .NET. Developers can also bring their own runtime using the AWS Lambda Runtime API, making it a versatile platform for diverse use cases.
- Automatic scalability: AWS Lambda automatically scales your application based on demand. Whether processing a single event or handling thousands simultaneously, Lambda adjusts compute resources dynamically.
- Pay-as-you-go pricing: Costs are determined by the number of requests and the execution time of your functions. This eliminates the need for upfront investments and ensures you only pay for what you use.
- Integrated security: Lambda works with AWS Identity and Access Management (IAM), ensuring fine-grained access control and secure interactions between your functions and other AWS services.
Common use cases of Lambda
- Processing data streams: AWS Lambda integrates with Amazon Kinesis to process and analyze streaming data in real time. For example, you can monitor IoT devices or process log files dynamically.
- Building RESTful APIs: Lambda functions can be paired with AWS API Gateway to create scalable APIs for web and mobile applications. This setup is commonly used to handle user authentication, query databases, or generate dynamic content.
- Automating workflows: Automate complex workflows by triggering Lambda functions based on events from services like S3, DynamoDB, or CloudWatch. For instance, you can resize images uploaded to S3 or archive old database records automatically.
- Event handling in data pipelines: You can use Lambda to handle real-time data events, such as processing new uploads to an S3 bucket, transforming data before storage, or enriching data streams with external API calls.
- Serverless backend processing: Lambda is commonly used to offload backend tasks such as data validation, ETL (Extract, Transform, Load) processes, or sending notifications via Amazon SNS or SES.
How Does AWS Lambda Work?
AWS Lambda operates on an event-driven model, meaning it executes code in response to specific triggers or events. The key to Lambda’s functionality is its integration with other AWS services and ability to execute functions on demand. Let’s dive into the mechanics of how AWS Lambda works step-by-step:
An example architecture diagram using Lambda and other core AWS services. Image source: AWS.
1. Triggering AWS Lambda functions
AWS Lambda functions are initiated by events from various AWS services or external systems. Common examples of event sources include:
- API Gateway: When a user sends an HTTP request (e.g., a GET or POST request) to your API Gateway endpoint, Lambda can execute a function to process the request—for example, A RESTful API endpoint for creating a user in a database.
- S3 events: Lambda functions can respond to actions like uploading, deleting, or modifying an object in an S3 bucket. For example, they can resize images or convert file formats after an image is uploaded to an S3 bucket.
- DynamoDB streams: Any changes to DynamoDB tables, such as inserts, updates, or deletions, can trigger a Lambda function. For example, triggering an analytics pipeline when new rows are added to a DynamoDB table.
- Custom applications: You can invoke Lambda functions directly using SDKs, CLI, or HTTP requests, allowing you to integrate with external systems.
2. Execution environment
When an event triggers a Lambda function, AWS automatically creates an execution environment to run the code. This environment includes:
- Your function code: The code you wrote for your specific task.
- Allocated resources: CPU and memory (configurable) are dynamically assigned based on the function’s needs.
- Dependencies: Any external libraries or packages specified during deployment are included.
3. Concurrency and scaling
AWS Lambda supports automatic scaling by running multiple instances of your function in parallel. It manages to scale transparently without any configuration. Here’s how concurrency works:
- If your function needs to process 100 events simultaneously, Lambda will create as many execution environments as needed (up to the concurrency limit).
4. Integration with other AWS services
AWS Lambda integrates deeply with AWS services to build robust, end-to-end solutions:
- Database interactions: Lambda can read/write data to DynamoDB or RDS during execution.
- Messaging services: Lambda can trigger notifications via SNS or send messages to SQS queues for downstream processing.
- Monitoring and logging: CloudWatch captures all logs, metrics, and error details for Lambda functions, enabling you to monitor and troubleshoot performance issues.
Now, let’s get started with setting up your first Lambda function!
Setting up AWS Lambda
Prerequisites
- AWS account: Make sure you have an active AWS account. Sign up here.
- IAM user setup: Create an IAM user with permissions for AWS Lambda. Follow the IAM guide.
Setting up the development environment
- Install AWS CLI: Download and install the AWS CLI. Configure it using your IAM credentials.
- Set up Python or Node.js: Install Python or Node.js based on your preferred runtime. AWS Lambda supports multiple runtimes. We will use Python runtime in this tutorial.
Step 1: Access the AWS Lambda console
- Log in to the AWS Management Console.
- Navigate to the Lambda service.
Navigation dashboard in AWS console.
Click on Lambda in the navigation menu to see the dashboard:
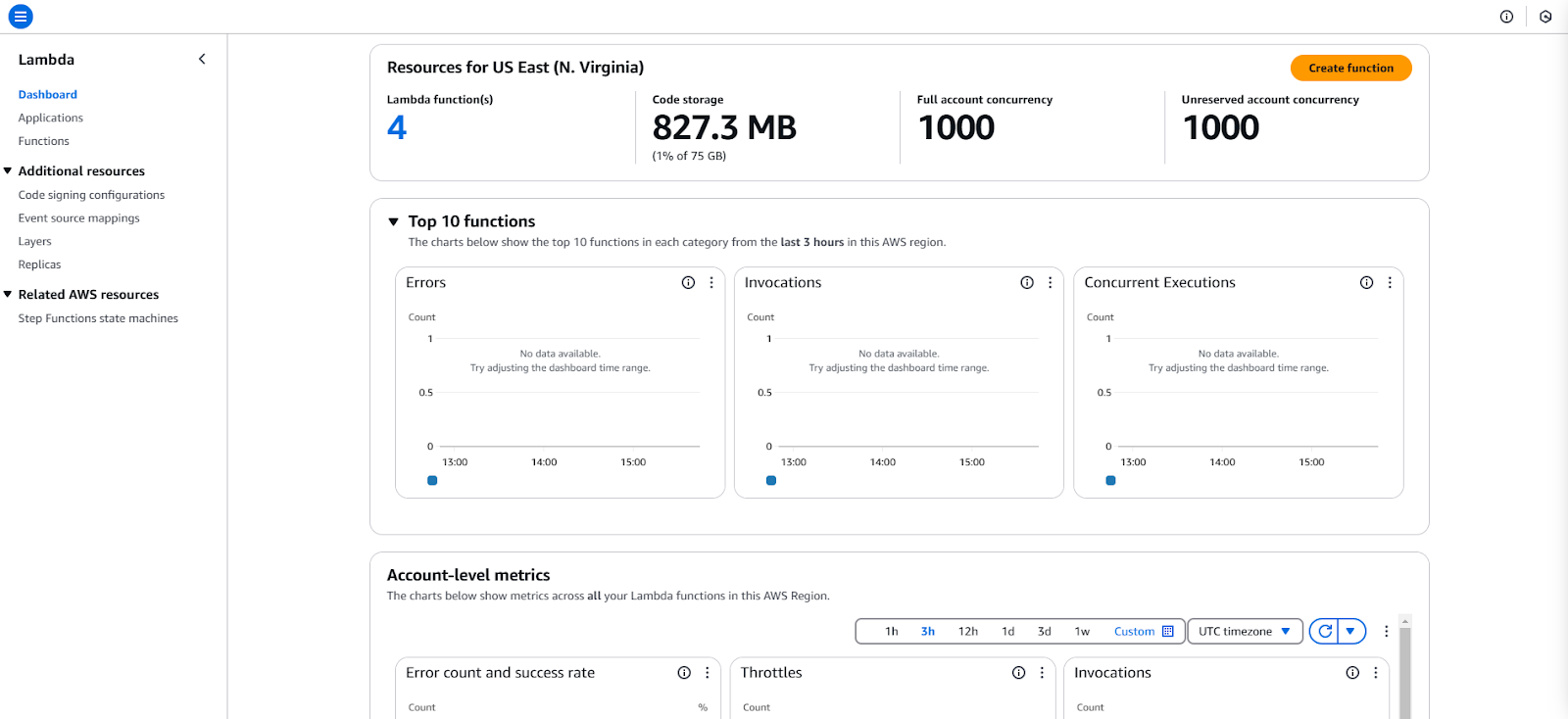
AWS Lambda Dashboard in AWS Console.
Step 2: Create a new function
- Click Create Function.
- Choose “Author from Scratch.”
- Provide a name for your function.
- Select a runtime (e.g., Python 3.11).
- Click on the Create Function button.
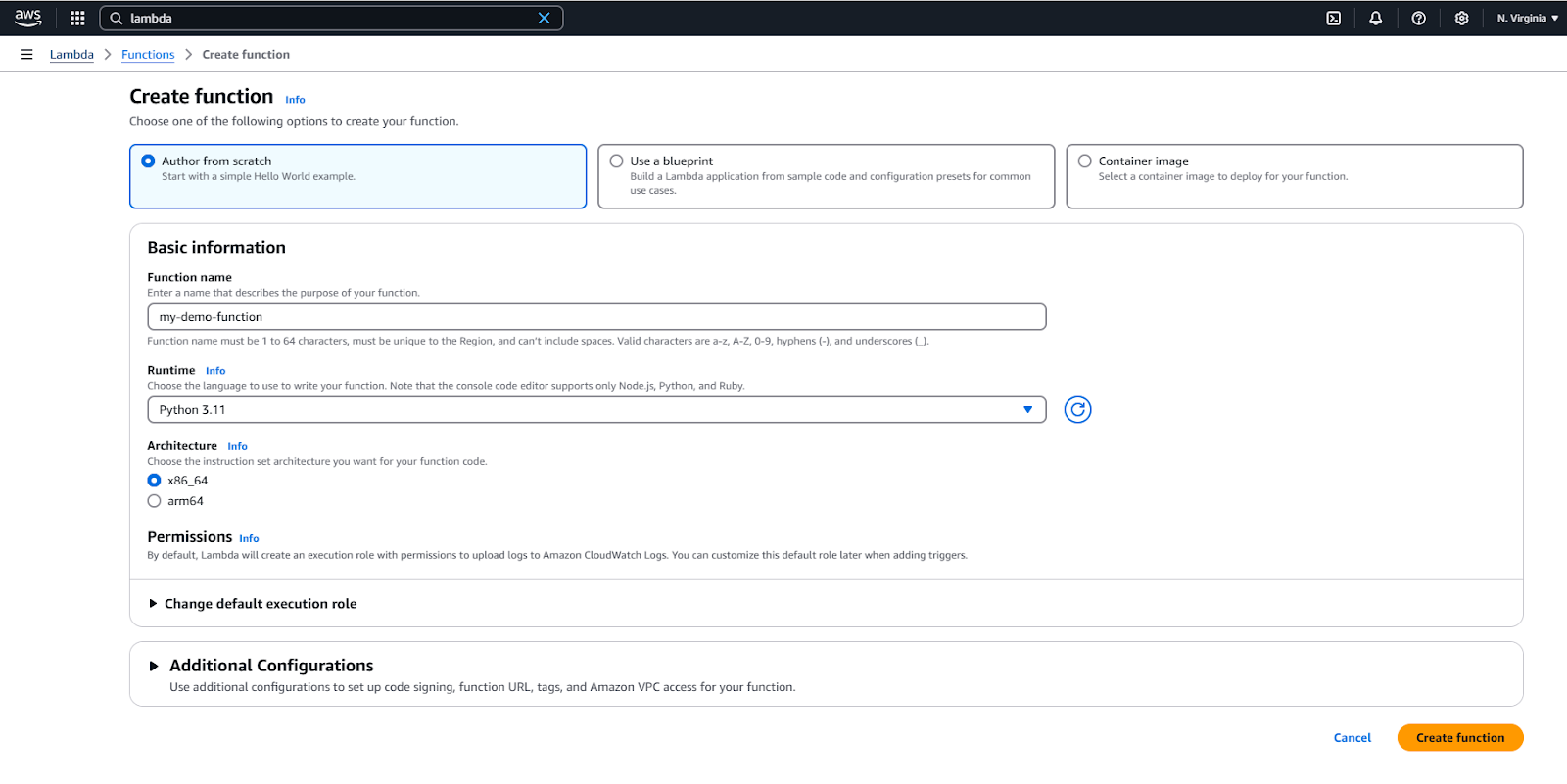
Create a new AWS Lambda function.
It will take a few seconds. Once the function is created, you will see a successful message on the top.
Step 3: Write your function code
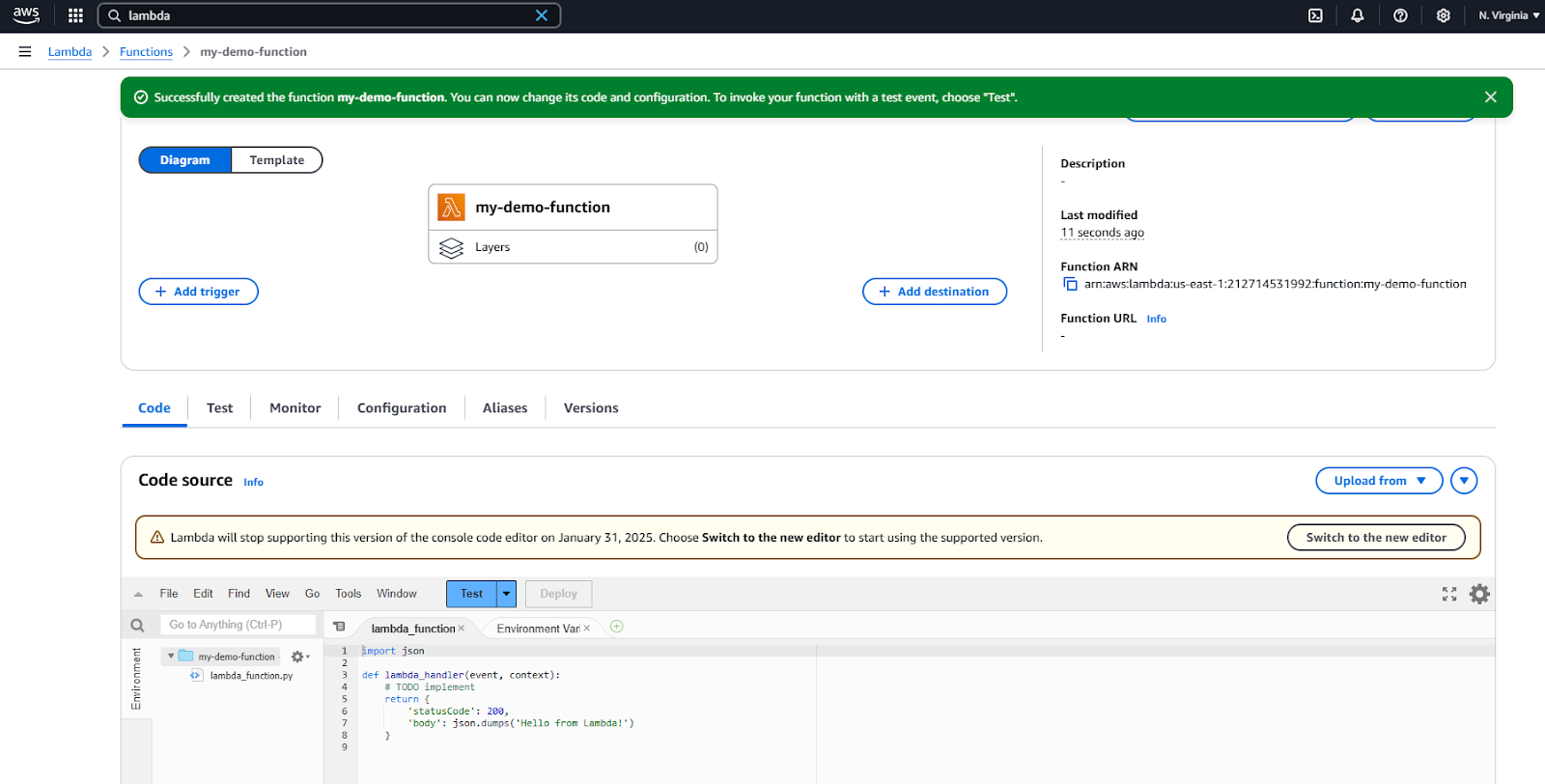
AWS Lambda browser IDE for simple code editing.
Step 4: Test your Lambda function
At this point, this function just returns the string “Hello from Lambda!”.
There is no logic, no dependencies, nothing.
We have a Python script called lambda_function.py that contains the function named lambda_handler() that returns a string.
We can now test it by simply clicking the Test button.
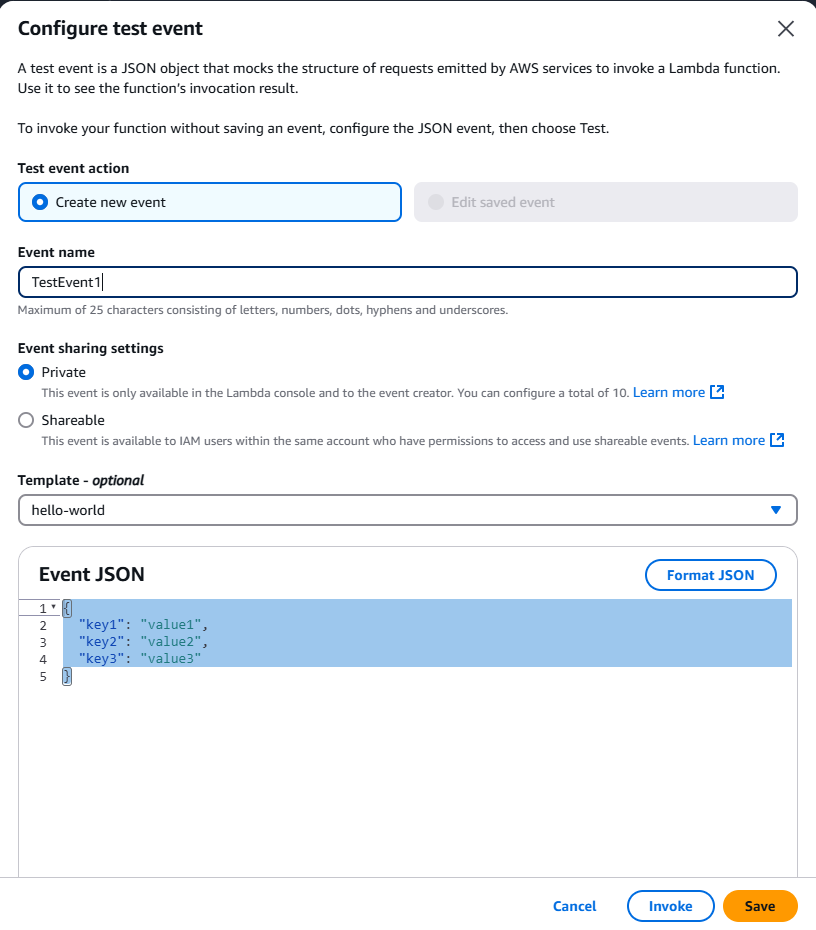
Test your AWS lambda function in browser.
You can remove the “Event JSON” as our function takes no input. Give an event name and click on the Invoke button.
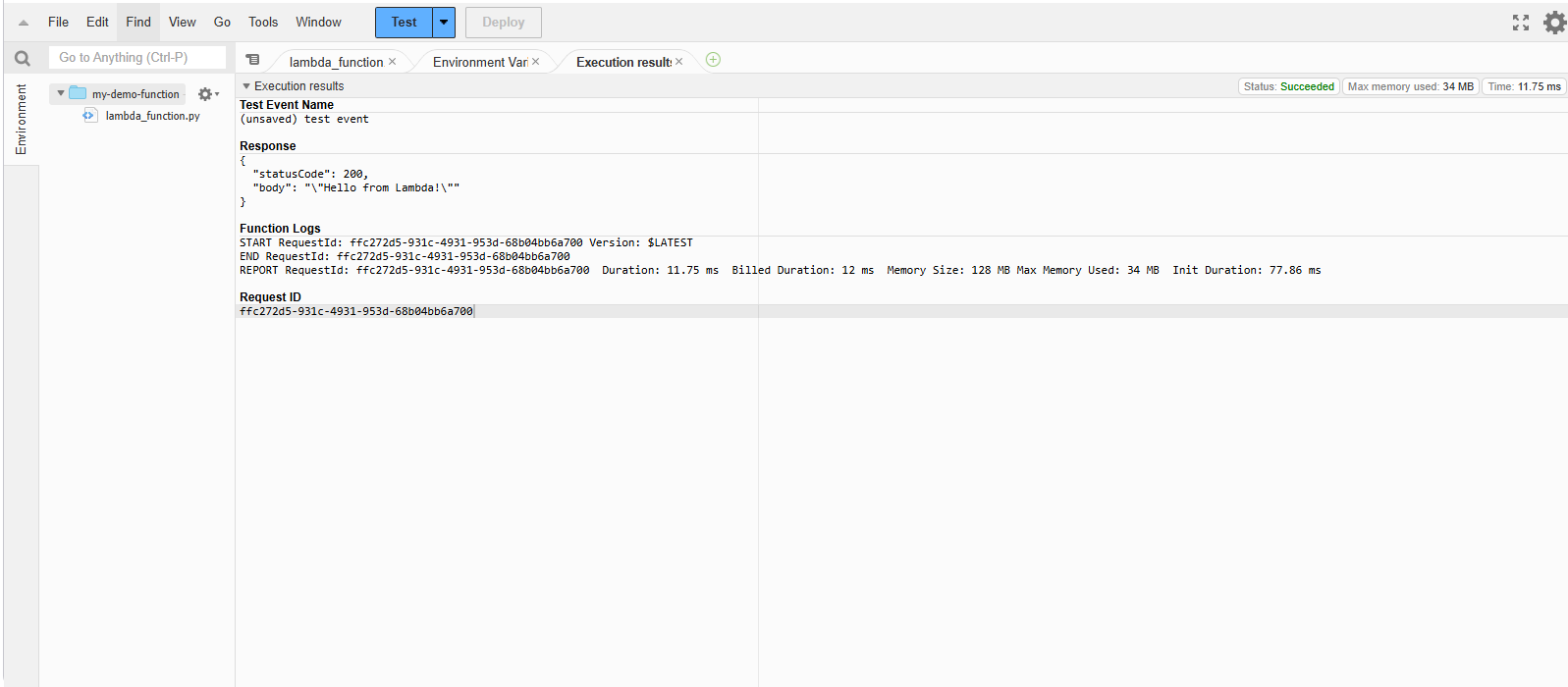
Successful test of AWS Lambda function.
The function was successfully executed, and the message was returned.
Yayy! We just deployed a serverless function using AWS Lambda. It doesn’t do much at the moment, but it is up and running. Every time this function is invoked, it returns a simple string.
Triggering Lambda with Events
As mentioned, the AWS Lambda architecture allows you to trigger functions in response to specific events from various AWS services, making it a versatile tool for automating workflows and integrating systems.
Events like file uploads to an S3 bucket, updates in a DynamoDB table, or API calls through API Gateway can invoke Lambda functions, enabling real-time processing and scalable execution.
1. Setting up an S3 trigger
- Go to the S3 console.
- Select S3 bucket.
- Under Properties, add an event notification to trigger your Lambda function when creating an object.
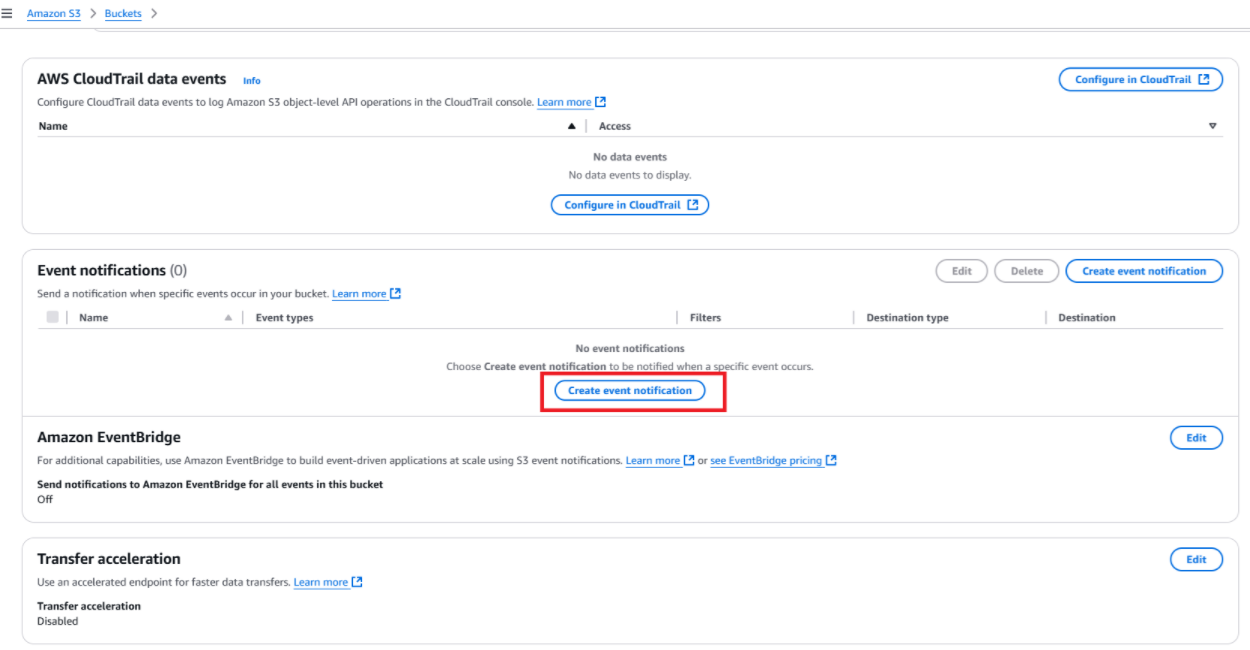 Create event notification in the AWS S3 bucket.
Create event notification in the AWS S3 bucket.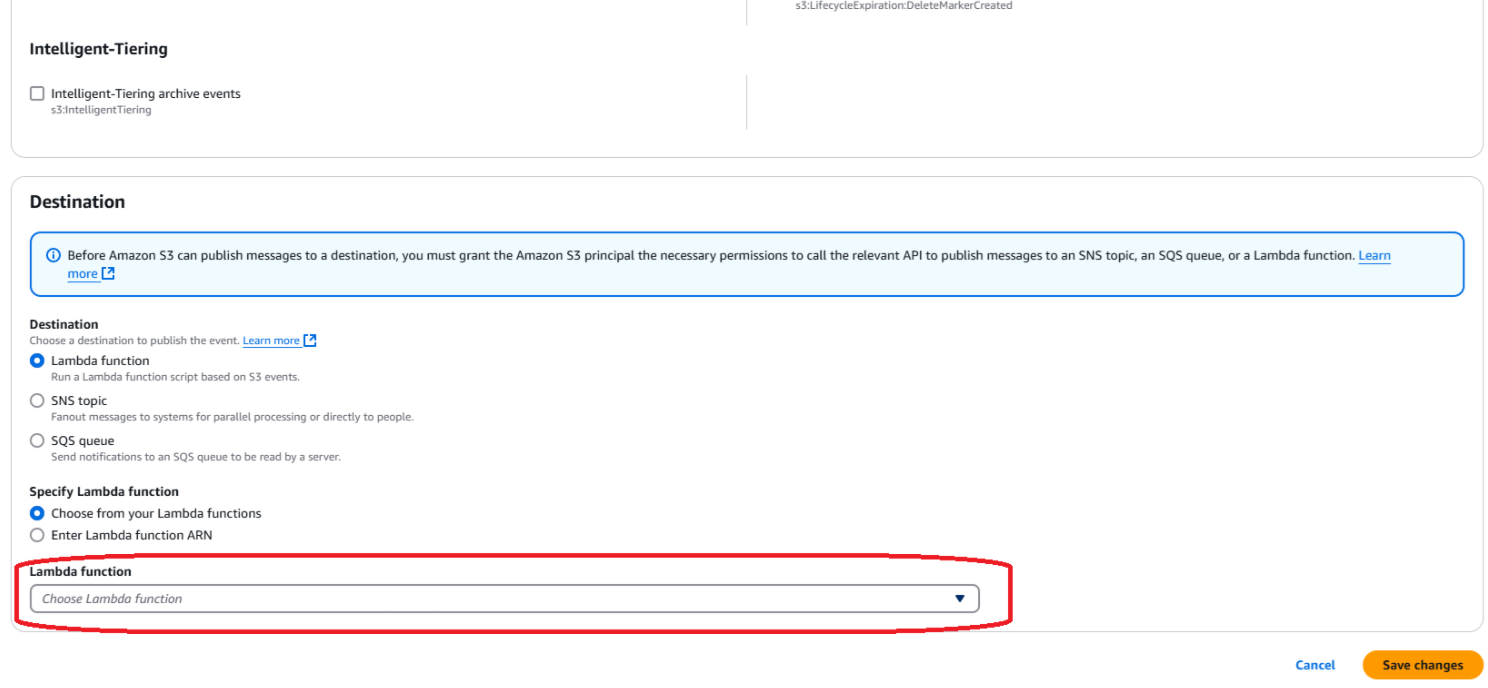 Select the Lambda function to trigger in S3.
Select the Lambda function to trigger in S3.
Example use cases:
-
- Automatically resize images uploaded to S3.
- Convert videos into multiple resolutions or formats for streaming.
- Check file formats, sizes, or metadata when uploading.
- Use AI to extract text from uploaded documents (e.g., via Amazon Textract).
2. API Gateway integration
- Navigate to the API Gateway service.
The API Gateway Service Dashboard in AWS Console.
- Create a new REST API.
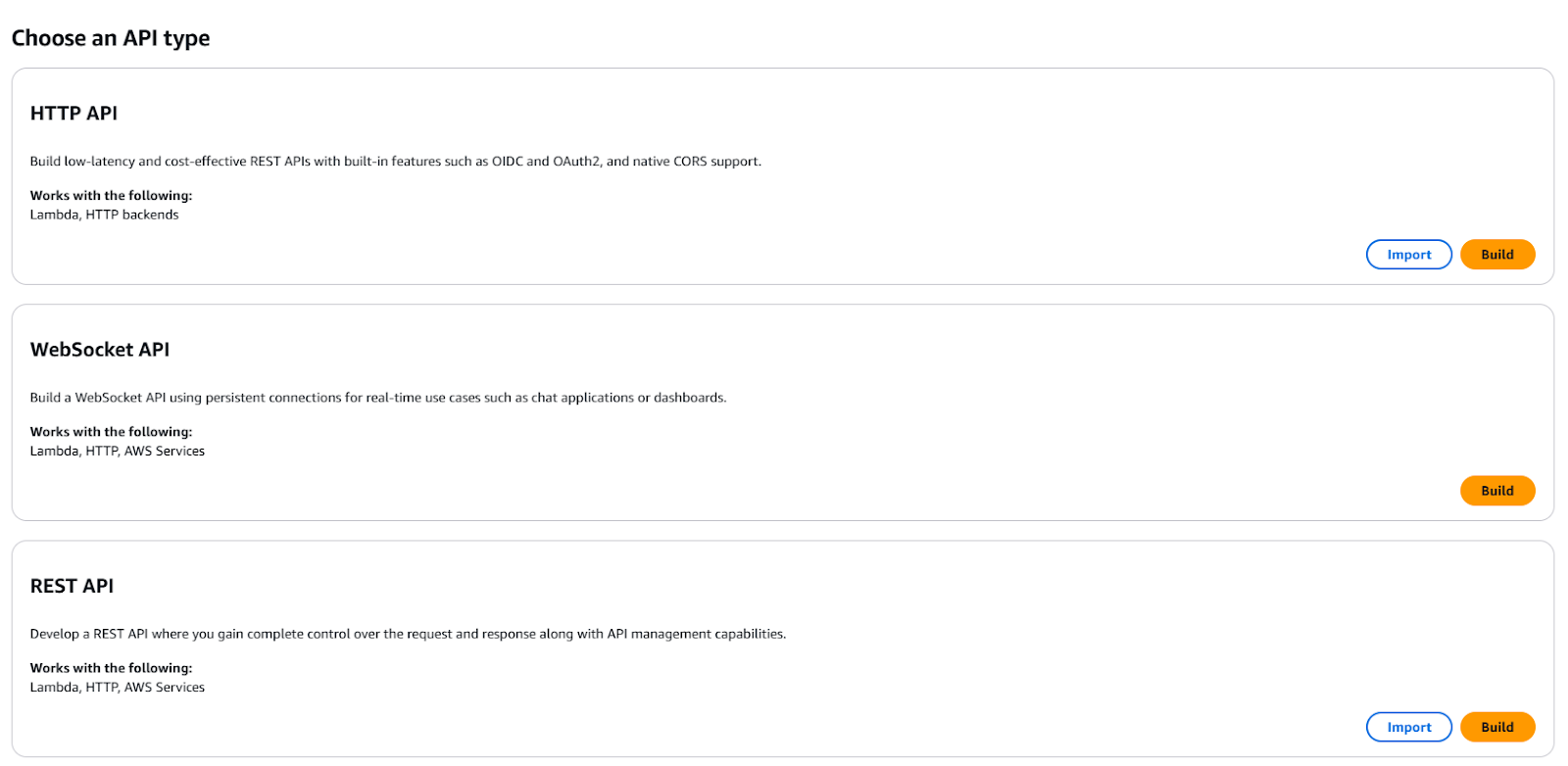
Create a new REST API via API Gateway.
- Configure a method (e.g., POST) to trigger your Lambda function.
Example use cases:
-
- Build a serverless API for real-time responses.
- Trigger a Lambda function to create and store user data in a database.
- Handle POST requests to process and validate customer orders in real-time
- Trigger a Lambda function to query and return data from a database or API.
Deploying and Monitoring AWS Lambdas
Deploying AWS Lambda functions is straightforward and can be done using different methods depending on your needs, such as the AWS Management Console for manual deployments or the AWS CLI for automated deployments.
1. Manual deployment using the AWS Console
The AWS Management Console provides an intuitive web interface for deploying Lambda functions. This method is ideal for small projects or quick changes. Here’s how to deploy a Lambda function using the console:
- Create or edit a function:
- Log in to the AWS Management Console.
- Navigate to AWS Lambda.
- Click on Create Function to set up a new function or select an existing function to update.
- Upload your code:
- Choose Upload from and select .zip file or container image.
- You can edit your function code directly in the integrated code editor for small-scale development.
- Configure the function:
- Define environment variables, memory allocation, and timeout limits based on your use case.
- Add necessary permissions using AWS IAM roles to allow the function to interact with other AWS services.
- Deploy the changes:
- Click Deploy to save and activate your changes.
- Use the Test feature to invoke the function manually and validate that it works as expected.
2. Automated deployment using the AWS CLI
The AWS CLI is an efficient way to deploy and update Lambda functions for automation or frequent updates. It ensures consistency and reduces manual errors, especially in larger projects or CI/CD pipelines.
Step 1 – Prepare the deployment package
Package your code and dependencies into a .zip file. For example:
zip -r my-deployment-package.zip .
Step 2 – Deploy the function using CLI
Use the update-function-code command to upload the new code to AWS Lambda:
aws lambda update-function-code \ --function-name MyFunction \ --zip-file fileb://my-deployment-package.zip
Step 3 – Check the deployment
After deployment, verify the status of the function using:
aws lambda get-function --function-name MyFunction
This command retrieves the function’s configuration and confirms the deployment.
Monitoring Lambda with CloudWatch
Monitoring is critical to ensuring your Lambda functions run efficiently, handle errors gracefully, and meet performance expectations. AWS Lambda integrates with Amazon CloudWatch to provide monitoring and logging capabilities.
Amazon CloudWatch automatically collects and displays key metrics for your Lambda functions. These metrics help you analyze your function’s performance and troubleshoot issues.
Metrics to monitor:
- Invocations: Tracks the number of times your function is invoked. Helps you understand traffic patterns and usage trends.
- Errors: Displays the number of errors during function execution. Use this to identify failure rates and debug issues.
- Duration: Measures the time taken to execute the function. This is crucial for optimizing performance and managing costs.
- Throttles: Shows the number of invocations that were throttled due to hitting concurrency limits.
Accessing metrics:
- Navigate to the CloudWatch Metrics Console.
- Select Lambda from the list of namespaces.
- Choose the function you want to monitor to view detailed metrics.
AWS Lambda Best Practices
Now that you have deployed your first Lambda function, knowing some best practices for future, more complex projects is useful. In this section, I provide some best practices to keep in mind.
1. Optimize function cold starts
Cold starts occur when a Lambda function is invoked after being idle, leading to slight latency as AWS provisions the execution environment. While AWS minimizes this overhead, there are steps you can take to reduce cold start time:
Use smaller deployment packages
- Keep your deployment package lightweight by only including necessary dependencies.
- Use tools like AWS Lambda Layers to share common libraries (e.g., AWS SDK) across functions without including them in individual packages.
- Compress and minify code where possible, especially for JavaScript or Python-based functions.
Avoid heavy initialization in your function
Move resource-intensive initialization (e.g., database connections, API clients, or third-party libraries) outside the function handler. This ensures the code is executed only once per environment and reused across invocations.
Leverage provisioned concurrency
For critical, latency-sensitive functions, use Provisioned Concurrency to keep the execution environment ready to serve requests. While it incurs additional costs, it guarantees low latency for high-priority workloads.
2. Keep functions stateless
Statelessness is a fundamental principle of serverless architecture, ensuring your application scales seamlessly:
Avoid reliance on in-memory data
Lambda functions are ephemeral, meaning their execution environment is temporary and may not persist across invocations. Instead of relying on in-memory variables, store state information in external systems like DynamoDB, S3, or Redis.
Enable idempotency
Design your functions to handle duplicate events gracefully. Use unique identifiers for requests and check logs or databases to ensure the same event isn’t processed multiple times.
3. Use environment variables
Environment variables are a secure and convenient way to configure your Lambda functions:
Store sensitive information
- Store API keys, database connection strings, and other secrets as environment variables. AWS Lambda encrypts these variables at rest and decrypts them during execution.
- For added security, use AWS Secrets Manager or Systems Manager Parameter Store to manage secrets dynamically.
Simplify configuration management
Use environment variables to manage configurations like log levels, region settings, or third-party service URLs. This eliminates the need for hardcoded values, making your function more portable across environments (e.g., dev, staging, prod).
Conclusion
This tutorial has provided a guide to starting with AWS Lambda, from understanding its features and use cases to deploying and monitoring functions effectively. You can create robust and maintainable serverless applications by adhering to best practices, such as optimizing cold starts, keeping functions stateless, and using environment variables.
AWS Lambda is a way to build modern, event-driven architectures that integrate with the AWS ecosystem. If you want to learn more about it, I recommend checking out DataCamp’s AWS courses.