













التحول إلى اليسار هو نهج في تطوير البرمجيات والعمليات التي تؤكد على الاختبار والمراقبة والأتمتة أولاً في دورة مرور حياة البرمجيات. الهدف من نهج التحول إلى اليسار هو منع المشاكل قبل أن تحدث عن طريق التقاطها مبكرًا ومعالجتها بسرور.
عندما تحدد مشكلة قابلية التوسع أو خللًا مبكرًا ، يكون من السريع والاقتصادي حلها. نقل الشفرة الغير فعالة إلى حاويات السحابة يمكن أن يكون مكلفًا ، حيث قد يتم تنشيط التوسع التلقائي وزيادة حسابك الشهري. علاوة على ذلك ، ستكون في حالة طوارىء حتى تتمكن من تحديدها وعزلها وإصلاحها.
بيان المشكلة
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
هذا هو توقيت الأحداث.
في 6 أغسطس في 14:13 ، تم إعادة تشغيل التطبيق بملف جار التشغيل Spring Boot الجديد الذي يحتوي على تومكات جافا ضمني.
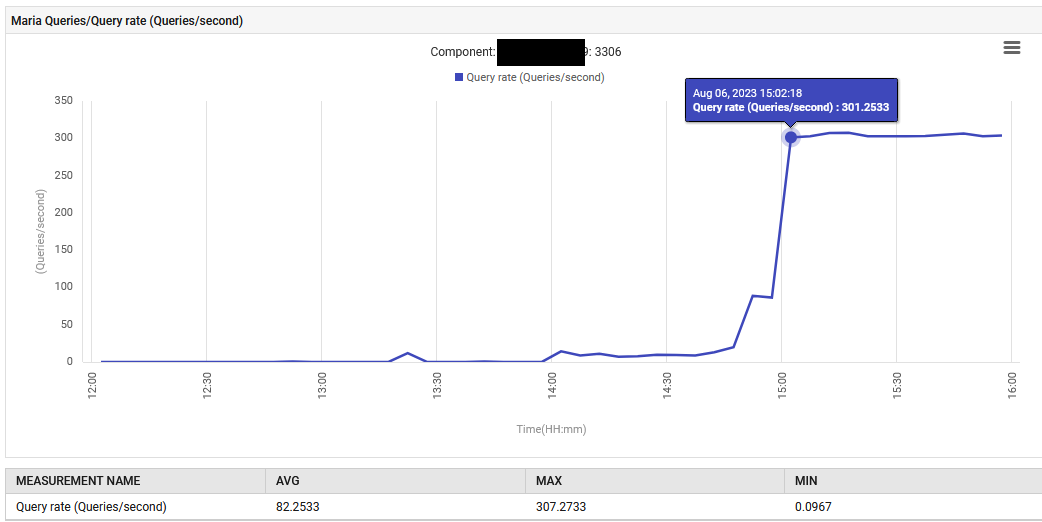
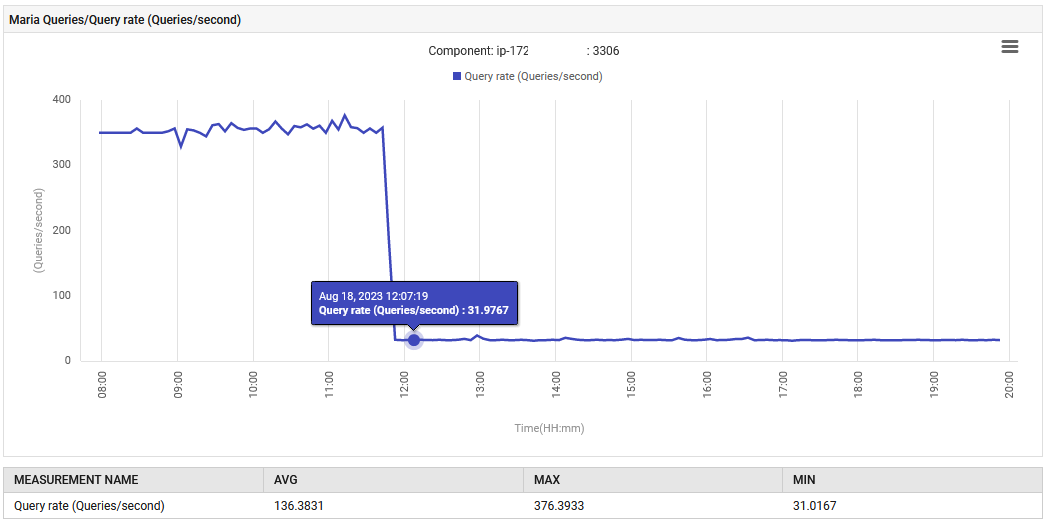
في 14:52 ، ارتفع معدل معالجة الاستعلامات لـ MariaDB من 0.1 إلى 88 استعلام في الثانية ومن ثم إلى 301 استعلام في الثانية.
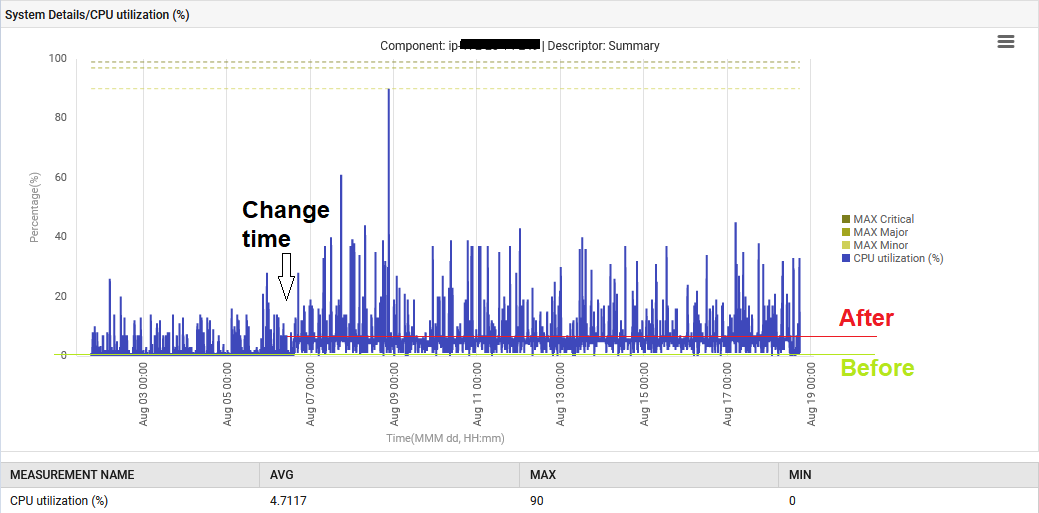
إضافة إلى ذلك ، ارتفع معدل المعالجة المركزي للنظام من 1٪ إلى 6٪.
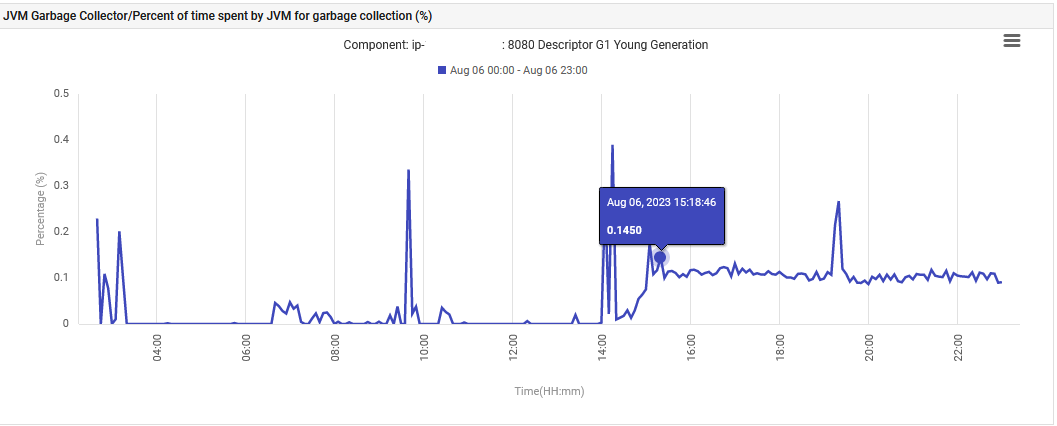
أخيرًا ، ارتفع وقت JVM الذي قضى على مجموعة غارباج جافا الشباب التراكمي من 0٪ إلى 0.1٪ وظل عند هذا المستوى.
التطبيق، في مرحلة الاختبار الافتراضي، يطلق بشكل غير طبيعي 300 استعلامًا في الثانية، وهو أمر يتجاوز بكثير ما كان مصممًا للقيام به. الميزة الجديدة أدى إلى زيادة في اتصالات قاعدة البيانات، ولهذا السبب كانت الزيادة في الاستعلامات كبيرة للغاية. ومع ذلك، أظهرت لوحة المراقبة أن القياسات المشكوك فيها كانت طبيعية قبل نشر الإصدار الجديد.
الحل
إنه تطبيق Spring Boot يستخدم JPA لاستعلام قاعدة بيانات MariaDB. مصمم لتشغيل محتوى مكونين للحد من الحمل ولكن متوقع توسيعه إلى عشرة.
إذا كان محتوى مكون واحد قادرًا على توليد 300 استعلام في الثانية، هل يمكن أن يتعامل مع 3000 استعلام في الثانية إذا كانت جميع المكونات العشرة قيد التشغيل؟ هل يمكن لقاعدة البيانات أن تمتلك عدد كافٍ من الاتصالات لتلبية احتياجات الأجزاء الأخرى من التطبيق؟
لم يكن لدينا خيار آخر سوى العودة إلى طاولة المطور لفحص التغييرات في Git.
التغيير الجديد سيأخذ عدد قليل من السجلات من جدول ويعالجها. هذا ما لاحظناه في فئة الخدمة.
List<X> findAll = this.xRepository.findAll();
لا, استخدام طريقة findAll() بدون ت pagination في CrudRepository من Spring ليس فعالاً. الت pagination تساعد على تقليل الوقت الذي يستغرقه استرداد البيانات من قاعدة البيانات عن طريق تحديد كمية البيانات المستردة. هذا ما علمناه من جديد في تعليمنا عن قواعد البيانات الرئيسية. علاوة على ذلك, الت pagination تساعد على إبقاء استخدام الذاكرة منخفضاً لمنع تعطل التطبيق بسبب فرط البيانات, وكذلك تقليل جهد جافا فيرت المتكامل الذي ذكر في بيان المشكلة أعلاه.
تم هذا الاختبار باستخدام 2000 سجل فقط في حاوية واحدة. إذا تم نقل هذا الكود إلى الإنتاج, حيث يوجد حوالي 200,000 سجل في ما يصل إلى 10 حاويات, كان ذلك قد يسبب الكثير من التوتر والقلق للفريق في ذلك اليوم.
تم إعادة بناء التطبيق بإضافة فصل WHERE إلى الطريقة.
List<X> findAll = this.xRepository.findAllByY(Y);
تم استعادة العمل الطبيعي. تم تخفيض عدد الاستعلامات في الثانية من 300 إلى 30, وعود جهد التحكم في المهملات إلى مستواه الأصلي. علاوة على ذلك, استخدام معالج النظام المركزي تراجع.
التعلم والملخص
أي شخص يعمل في هندسة موارد الموقع الموثوق به (SRE) سيقدر أهمية هذا الاكتشاف. تمكنا من التصرف بناءً عليه دون الحاجة لرفع علم خطأ من الدرجة 1. إذا تم نشر هذه الحزمة الخاطئة في الإنتاج، فقد يتم إثارة عتبة التوسيع التلقائي للعميل، مما يؤدي إلى إطلاق حاويات جديدة حتى بدون زيادة في حمل المستخدم.
هناك ثلاث نقاط رئيسية يجب استخلاصها من هذه القصة.
أولاً، من الأفضل ممارسة التشغيل بتكامل حلول الرؤية من البداية، حيث يمكن أن توفر تاريخ الأحداث التي يمكن استخدامها لتحديد القضايا المحتملة. بدون هذا التاريخ، قد لا أأخذ نسبة الترابط 0.1٪ واستهلاك CPU بنسبة 6٪ بجدية، وكان من الممكن إصدار الكود في الإنتاج بنتائج كارثية. توسيع نطاق حلول المراقبة إلى خوادم UAT ساعد الفريق على تحديد الأسباب الجذرية المحتملة ومنع المشاكل قبل أن تحدث.
ثانياً، يجب وجود حالات اختبار متعلقة بالأداء في عملية الاختبار، ويجب مراجعتها من قبل شخص ذو خبرة في الرؤية. سيضمن هذا اختبار وظائف الكود، بالإضافة إلى أدائه.
ثالثاً، تقنيات تتبع الأداء المبنية على الأشباه الجاود هي جيدة لتلقي تنبيهات حول الاستخدام العالي، التوفر، إلخ. لتحقيق الرؤية، قد تحتاج إلى وجود الأدوات والخبرة المناسبتين. تحياتي للبرمجة!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c