













هذا جزء من التحول الرقمي لشركة عقارية كبرى. من أجل السرية، لن أكشف عن أي بيانات تجارية، لكنك ستحصل على نظرة مفصلة عن مستودع بياناتنا واستراتيجيات التحسين لدينا.
هيا بنا نبدأ.
الهيكل المعماري
من الناحية المنطقية، يمكن تقسيم هيكل بياناتنا إلى أربعة أجزاء.
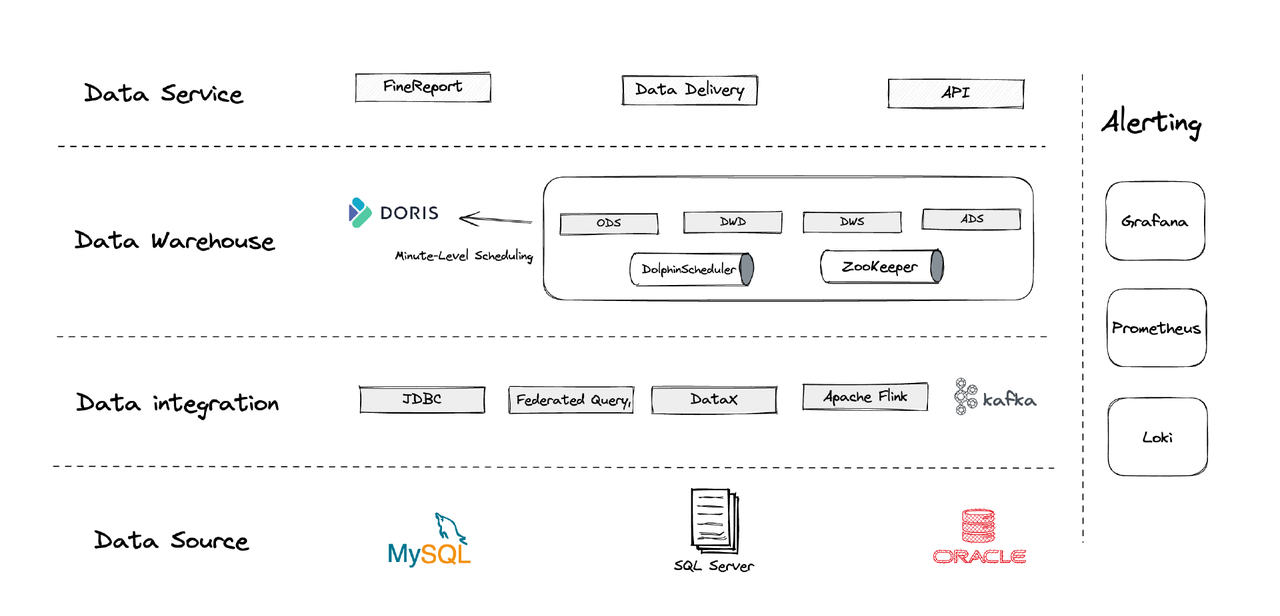
- تكامل البيانات: يتم دعم هذا بواسطة Flink CDC، DataX، وميزة Multi-Catalog في Apache Doris.
- إدارة البيانات: نستخدم Apache Dolphinscheduler لإدارة دورة الحياة للسكريبتات، الأذونات في إدارة العدد الكبير من المستخدمين، ومراقبة جودة البيانات.
- التنبيه: نستخدم Grafana، Prometheus، وLoki لمراقبة إمدادات المكونات والسجلات.
- خدمات البيانات: هنا تدخل أدوات BI للتفاعل المستخدم، مثل استعلامات البيانات والتحليل.
1. الجداول
نقوم بإنشاء جداول الأبعاد وجداول الحقائق بالتركيز على كل كيان تشغيلي في العمل، بما في ذلك العملاء، المنازل، إلخ. إذا كانت هناك سلسلة من الأنشطة تتعلق بنفس الكيان التشغيلي، يجب تسجيلها بحقل واحد. (هذا درس تعلمناه من نظام إدارة بياناتنا السابق الفوضوي.)
2. الطبقات
مستودع البيانات لدينا مقسم إلى خمسة طبقات مفهومة. نستخدم Apache Doris وApache DolphinScheduler لجدولة السكريبتات DAG بين هذه الطبقات.

يمر كل يوم الطبقات بتحديث شامل إلى جانب التحديثات التزايدية عند وجود تغييرات في حقول الحالة التاريخية أو عدم sychronization تامة للجداول ODS.
3. استراتيجيات التحديث التزايدي
(1) تعيين where >= "activity time -1 day or -1 hour" بدلاً من where >= "activity time
السبب في القيام بذلك هو منع انزلاق البيانات الناتج عن فجوة الوقت في إعداد البرامج النصية. لنفترض، مع فترة التنفيذ المحددة إلى 10 دقائق، أن البرنامج النصي يتم تنفيذه في 23:58:00 ويصل قطعة من البيانات الجديدة في 23:59:00. إذا قمنا بتعيين where >= "activity time، ستغادر تلك القطعة من البيانات اليومية.
(2) استلام معرف المفتاح الأساسي الأكبر للجدول قبل كل تنفيذ للبرنامج النصي، وتخزين المعرف في الجدول التابع، وتعيين where >= "ID in auxiliary table"
هذا لتجنب تكرار البيانات. قد يحدث تكرار البيانات إذا كنت تستخدم نموذج المفتاح الفريد في Apache Doris وتعيين مجموعة من المفاتيح الأساسية حيث إذا كانت هناك أي تغييرات في المفاتيح الأساسية في الجدول المصدر، ستُسجل التغييرات وستتم تحميل البيانات ذات الصلة. يمكن لهذه الطريقة إصلاح ذلك، لكنها فقط صالحة عندما تكون لدى الجداول المصدر مفاتيح أساسية تلقائية الزيادة.
(3) تقسيم الجداول
بالنسبة للبيانات التلقائية المتزايدة بناءً على الوقت مثل جداول السجلات، قد يكون هناك تغييرات أقل في البيانات والحالة التاريخية، لكن حجم البيانات كبير، لذا قد يكون هناك ضغط حسابي كبير على التحديثات الشاملة وإنشاء اللقطات. ولذلك، من الأفضل تقسيم مثل هذه الجداول بحيث لكل تحديث تلقائي، نحتاج فقط لاستبدال قسم واحد. (قد تحتاج أيضًا للانتباه لانزلاق البيانات أيضًا.)
4. استراتيجيات التحديث الشامل
(1) تهجير الجدول
مسح الجدول ثم إدخال جميع البيانات من الجدول المصدر إليه. هذا قابل للتطبيق للجداول الصغيرة والسيناريوهات التي لا يوجد فيها نشاط مستخدم في الساعات الصغيرة.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
هذه عملية أتوماتيكية، ومن المستحسن استخدامها للجداول الكبيرة. قبل تنفيذ البرنامج النصي في كل مرة، ننشئ جدول مؤقت بنفس البنية، نحمل جميع البيانات إليه، ونستبدل الجدول الأصلي به.
تطبيق
- مهمة ETL: كل دقيقة
- التهيئة للنشر الأولي: 8 عقد، 2 خلفيات أمامية، 8 خلفيات خلفية، نشر ترابطي
- تكوين العقد: 32C * 60GB * 2TB SSD
هذا هو تكويننا لعدة تيرابايت من البيانات القديمة وجيجابايت من البيانات التزايدية. يمكنك استخدامه كمرجع وتكبير الكوكبة مبنيًا على هذا الأساس. إن النشر لـ Apache Doris بسيط. لا تحتاج إلى مكونات أخرى.
1. لدمج البيانات عند الاتصال وبيانات السجل، نستخدم DataX الذي يدعم تنسيق CSV وقراءات قواعد البيانات العلائقية المتعددة، ويوفر Apache Doris DataX-Doris-Writer.

2. نستخدم Flink CDC لمزامنة بيانات من الجداول المصدر. ثم نجمع المقاييس الحقيقية الزمنية باستخدام Materialized View أو نموذج التجميع في Apache Doris. نظرًا لأننا نعالج جزءًا من المقاييس بشكل فوري ولا نرغب في توليد الكثير من اتصالات قاعدة البيانات، نستخدم مهمة Flink واحدة لصيانة العديد من الجداول المصدر CDC. يتم تحقيق ذلك عن طريق ميزة الدمج المتعدد للمصادر ومزامنة قاعدة البيانات الكاملة في Dinky، أو يمكنك تنفيذ مهمة Flink DataStream المتعددة للمصادر بنفسك. من الجدير بالذكر أن Flink CDC وApache Doris يدعمان تغيير المخطط.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. نستخدم سكربتات SQL أو “Shell + SQL”، ونجري إدارة العمر الأفرادي للسكربتات. في طبقة ODS، نكتب ملف DataX عام للمهمة ونمرر المعلمات لكل جدول مصدر للاستيراد بدلاً من كتابة مهمة DataX لكل جدول مصدر. بهذه الطريقة، نجعل الأمور أسهل بكثير في الصيانة. نحن ندير سكربتات ETL لـ Apache Doris على DolphinScheduler، حيث نجري أيضًا تحكمًا بالإصدار. في حالة حدوث أي أخطاء في بيئة الإنتاج، يمكننا دائمًا التراجع.
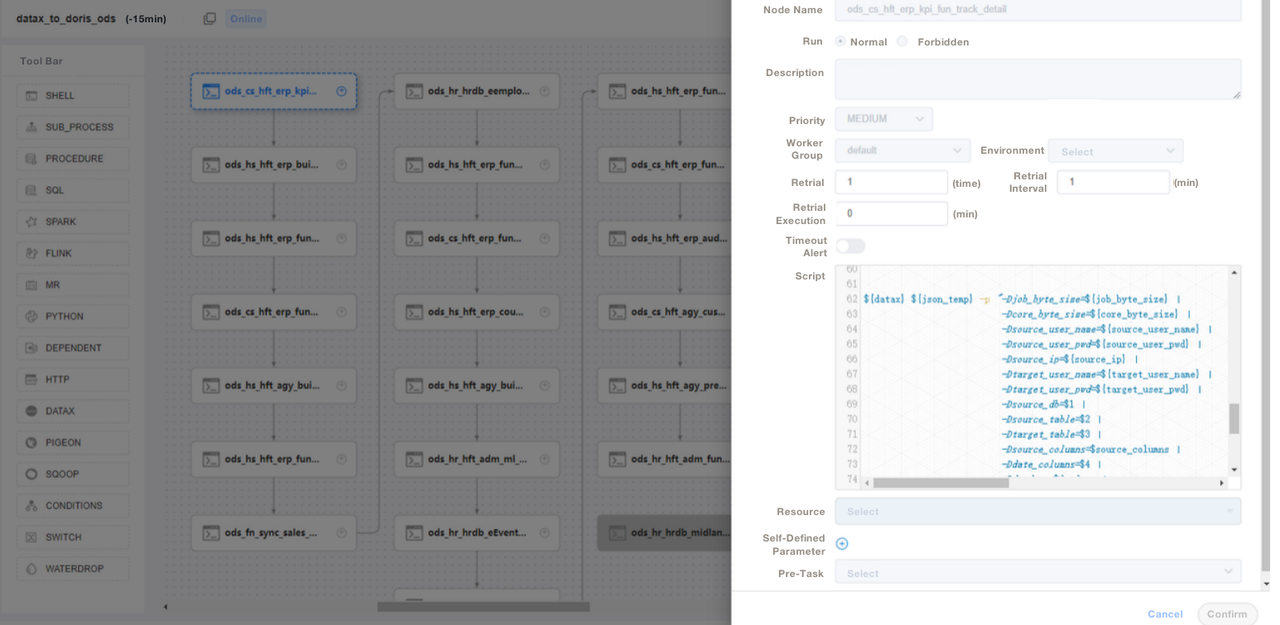
4. بعد استيراد البيانات باستخدام سكربتات ETL، نقوم بإنشاء صفحة في أداة تقاريرنا. نقوم بتخصيص امتيازات مختلفة لحسابات مختلفة باستخدام SQL، بما في ذلك امتياز تعديل الصفوف والحقول والقواميس العالمية. يدعم Apache Doris التحكم في الامتيازات على الحسابات، وهو يعمل بنفس طريقة MySQL.
نستخدم أيضًا نسخة إحتياطية لبيانات أباتشي دوريس لاستعادة الأمان من الكوارث، وسجلات تدقيق أباتشي دوريس لمراقبة كفاءة تنفيذ SQL، وGrafana+Loki لتنبيهات المقاييس المجمعة، وSupervisor لمراقبة عمليات التيار الثابت لعناصر العقد.
التحسين
استيراد البيانات
نستخدم DataX لتحميل البيانات خارج الخط عبر Stream Load. يتيح لنا تعديل حجم كل دفعة. طريقة Stream Load تعيد النتائج بشكل متزامن، مما يلبي احتياجات هيكلتنا. إذا قمنا بتنفيذ استيراد البيانات غير المتزامن باستخدام DolphinScheduler، قد يفترض النظام أن ال스크ربت قد تم تنفيذه، وهذا يمكن أن يسبب فوضى. إذا كنت تستخدم طريقة مختلفة، نوصي بأن تنفذ show load في البرنامج النصي، وتفحص حالة التصفية العادية لمعرفة ما إذا كان الاستيراد ناجحًا.
نموذج البيانات
نتبنى نموذج Unique Key في أباتشي دوريس لمعظم جداولنا. يضمن نموذج Unique Key تطابق بيانات البرنامج النصي ويجتنب بشكل فعال تكرار البيانات من الأعلى.
قراءة البيانات الخارجية
نستخدم ميزة Multi-Catalog في أباتشي دوريس للاتصال بمصادر البيانات الخارجية. يتيح لنا إنشاء توافقات للبيانات الخارجية في مستوى الكتالوج.
تحسين الاستعلام
نقترح أن تضع أكثر الحقول استخدامًا بشكل متكرر من أنواع غير حرفية (مثل int وكلمات البحث) في البايتات الثلاثة والثلاثين الأولى، لتتمكن من تصفية هذه الحقول في مللي ثانية في الاستعلامات النقطية.
قاموس البيانات
بالنسبة لنا، من المهم إنشاء قاموس بيانات لأنه يقلل بشكل كبير من تكاليف التواصل البشري، والتي قد تكون مؤلمة عندما يكون لديك فريق كبير. نستخدم information_schema في أباتشي دوريس لإنشاء قاموس بيانات. بهذا، يمكننا التقاط صورة كاملة للجداول والحقول بسرعة وبالتالي زيادة كفاءة التطوير.
الأداء
مدة استيعاب البيانات التحفيزية: في دقائق
مدة الاستجابة للاستعلامات: بالنسبة للجداول التي تحتوي على أكثر من 100 مليون سطر، يستجيب أباتشي دوريس للاستعلامات العشوائية خلال ثانية واحدة والاستعلامات المعقدة خلال خمس ثوان.
استهلاك الموارد: يتطلب الأمر عددًا قليلًا من الخوادم لبناء هذا المستودع البيانات. نسبة الضغط 70% في أباتشي دوريس توفر لنا الكثير من موارد التخزين.
التجربة والاستنتاج
في الواقع، قبل أن نتطور إلى بنيتنا البياناتية الحالية، جربنا هايف، سبارك، وهادوب لبناء مستودع بيانات تحفيزي. اتضح أن هادوب كان زيادة عن الحاجة لشركة تقليدية مثلنا لأننا لم نمتلك الكثير من البيانات لمعالجتها. من المهم إيجاد المكون الذي يناسبك بشكل أفضل.
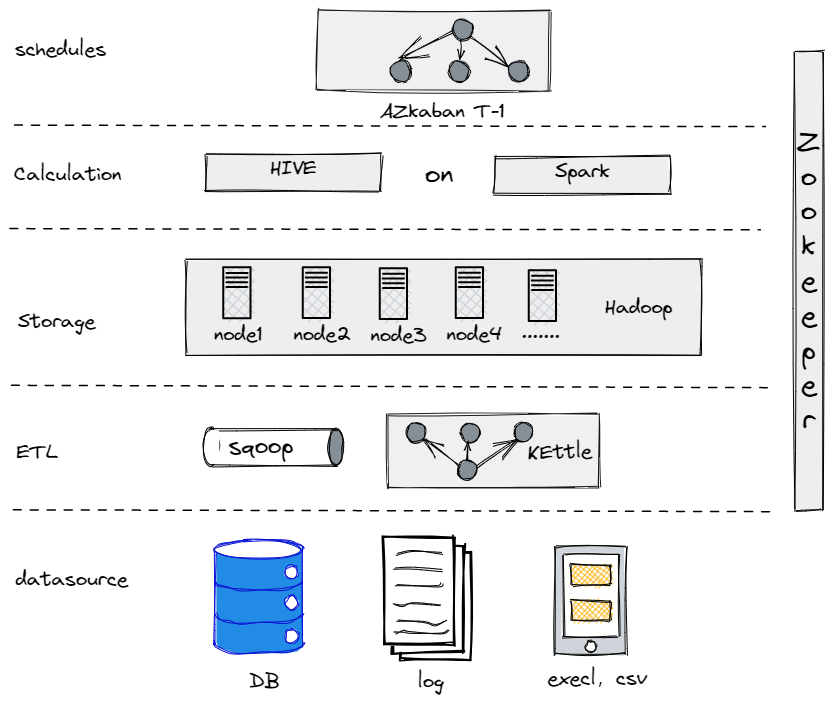
مستودع البيانات التحفيزي القديم لدينا
من ناحية أخرى، لتخفيف عملية الانتقال لبياناتنا الكبيرة، نحتاج إلى تبسيط منصة بياناتنا قدر الإمكان من حيث الاستخدام والصيانة. لهذا السبب اخترنا أباتشي دوريس. إنها متوافقة مع بروتوكول MySQL وتوفر مجموعة واسعة من الوظائف، لذا لسنا بحاجة إلى تطوير UDFs خاصة بنا. أيضًا، تتكون من نوعين فقط من العمليات: الأمامية والخلفية، مما يجعلها سهلة التوسع والتتبع.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry