













ويسبر إيه هو نموذج متقدم للتعرف التلقائي على الكلام (ASR) تم تطويره بواسطة OpenAI والذي يمكنه تحويل الصوت إلى نص بدقة ملحوظة ويدعم عدة لغات. بينما يتم تصميم ويسبر إيه بشكل أساسي لمعالجة الدفعات، يمكن تكوينه لتحويل الكلام إلى نص في الوقت الحقيقي على نظام Linux.
في هذا الدليل، سنتابع عملية التثبيت والتكوين، وتشغيل ويسبر إيه للتحويل المباشر على نظام Linux خطوة بخطوة.
ما هو ويسبر إيه؟
ويسبر إيه هو نموذج للتعرف على الكلام مفتوح المصدر تم تدريبه على مجموعة ضخمة من تسجيلات الصوت ويعتمد على بنية تعلم عميق تمكنه من:
- تحويل الكلام إلى نص بعدة لغات.
- التعامل مع اللهجات وضوضاء الخلفية بكفاءة.
- أداء ترجمة اللغة المنطوقة إلى الإنجليزية.
نظرًا لأنه مصمم لتحقيق دقة عالية في التحويل، يستخدم على نطاق واسع في:
- خدمات التحويل المباشر (مثل لضمان الإمكانية).
- المساعدين الصوتيين والتلقائيات.
- تحويل ملفات الصوت المسجلة.
بشكل افتراضي، ويسبر إيه غير مُحسَّن لمعالجة الوقت الحقيقي. ومع ذلك، باستخدام بعض الأدوات الإضافية، يمكنه معالجة تيارات الصوت المباشرة للتحويل الفوري.
متطلبات نظام ويسبر إيه
قبل تشغيل Whisper AI على Linux، تأكد من أن نظامك يلبي الشروط التالية:
متطلبات الأجهزة:
- وحدة المعالجة المركزية (CPU): معالج متعدد النوى (إنتل/إيه إم دي).
- الذاكرة (RAM): على الأقل 8 جيجابايت (يوصى بـ 16 جيجابايت أو أكثر).
- بطاقة الرسومات (GPU): بطاقة رسومات NVIDIA مع CUDA (اختياري ولكن يسرع عملية المعالجة بشكل كبير).
- التخزين: على الأقل 10 جيجابايت من المساحة الحرة على القرص للنماذج والتبعيات.
متطلبات البرمجيات:
- توزيعة Linux مثل Ubuntu، Debian، Arch، Fedora، إلخ.
- Python الإصدار 3.8 أو الأحدث.
- مدير الحزم Pip لتثبيت حزم Python.
- FFmpeg لمعالجة ملفات الصوت والتيارات.
الخطوة 1: تثبيت التبعيات المطلوبة
قبل تثبيت Whisper AI، قم بتحديث قائمة الحزم وترقية الحزم الحالية.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
بعد ذلك، ستحتاج إلى تثبيت Python 3.8 أو أحدث ومدير الحزم Pip كما هو موضح.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
وأخيرًا، ستحتاج إلى تثبيت FFmpeg، وهو إطار وسائط مستخدم لمعالجة ملفات الصوت والفيديو.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
الخطوة 2: تثبيت Whisper AI في Linux
بمجرد تثبيت التبعيات المطلوبة، يمكنك المتابعة في تثبيت Whisper AI في بيئة افتراضية تتيح لك تثبيت حزم Python دون التأثير على حزم النظام.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
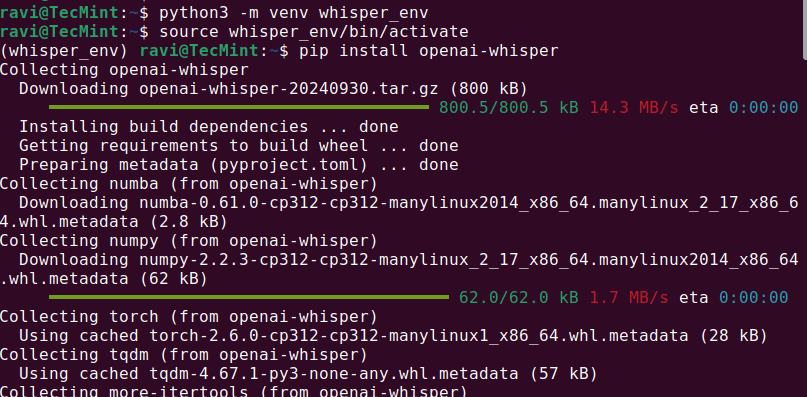
بمجرد اكتمال التثبيت، تحقق مما إذا كان Whisper AI قد تم تثبيته بشكل صحيح عن طريق التشغيل.
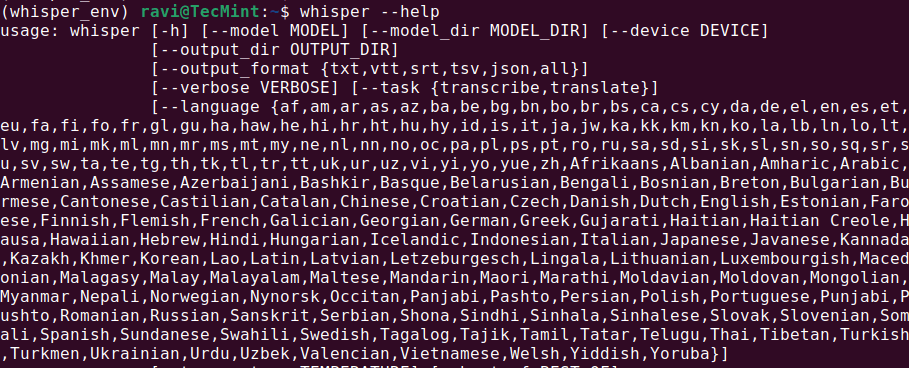
whisper --help
يجب أن يعرض هذا قائمة المساعدة بالأوامر المتاحة والخيارات، مما يعني أن Whisper AI تم تثبيته وجاهز للاستخدام.
الخطوة 3: تشغيل Whisper AI في لينكس
بمجرد تثبيت Whisper AI، يمكنك بدء نقل ملفات الصوت إلى نص باستخدام أوامر مختلفة.
نقل ملف صوتي
لنقل ملف صوتي (audio.mp3)، قم بتشغيل:
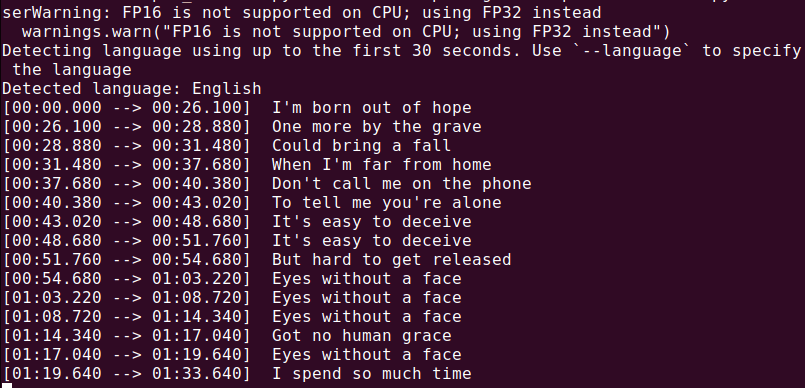
whisper audio.mp3
سيقوم Whisper بمعالجة الملف وإنشاء نص محول في شكل نصي.
الآن بعد أن تم تثبيت كل شيء، دعنا ننشئ سكريبت Python لالتقاط الصوت من الميكروفون الخاص بك وتحويله إلى نص في الوقت الحقيقي.
nano real_time_transcription.py
انسخ والصق الكود التالي في الملف.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
قم بتنفيذ السكريبت باستخدام Python، الذي سيبدأ في الاستماع إلى إدخال ميكروفونك وعرض النص المحول في الوقت الحقيقي. تحدث بوضوح إلى الميكروفون الخاص بك، ويجب أن ترى النتائج مطبوعة على الطرفية.
python3 real_time_transcription.py
الختام
Whisper AI هو أداة قوية لتحويل الكلام إلى نص يمكن تكييفها للنقل في الوقت الحقيقي على نظام Linux. للحصول على أفضل النتائج، استخدم وحدة معالجة الرسوميات وقم بتحسين نظامك لمعالجة الوقت الحقيقي.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/