













VAR-As-A-Service هو نهج MLOps لتوحيد وإعادة استخدام نماذج إحصائية ونماذج تعلم الآلة لخطوط التوجيه. هذه المقالة هي الثانية في سلسلة من المقالات تبني على هذا المشروع، تمثل تجارب مع نماذج إحصائية ونماذج تعلم الآلة مختلفة، وخطوط البيانات التي تم تنفيذها باستخدام أدوات DAG موجودة، وخدمات التخزين، سواء كانت مستندة إلى الأشباه السحابية أو الحلول المحلية البديلة. يركز هذا المقال على تخزين ملفات النموذج باستخدام نهج يمكن تطبيقه واستخدامه لنماذج تعلم الآلة أيضًا. تم تنفيذ التخزين على أساس MinIO كخدمة تخزين شبه الكائن متوافقة مع AWS S3. علاوة على ذلك، يقدم المقال نظرة عامة على الحلول البديلة للتخزين ويوضح مزايا التخزين المستند إلى الكائن.
المقالة الأولى في السلسلة (تحليل السلاسل الزمنية: VARMAX-As-A-Service) تقارن بين النماذج الإحصائية ونماذج تعلم الآلة كجميعها نماذج رياضية ويوفر تنفيذًا شاملًا لنموذج إحصائي يعتمد على VARMAX للتوقعات الاقتصادية الكلية باستخدام مكتبة Python تُعرف بـ statsmodels. تم نشر النموذج كخدمة REST باستخدام Python Flask وويب خادم أباتشي، مغلف في حاوية دوكر. تم تصوير البُنية العالية للتطبيق في الصورة التالية:
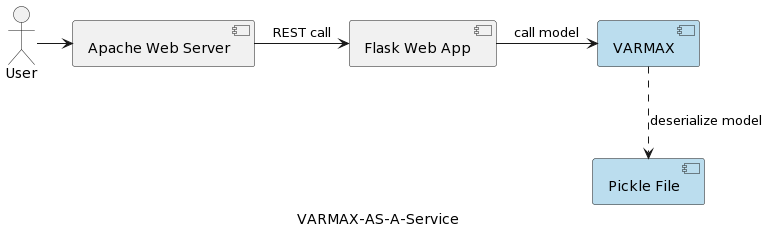
تم تجميع النموذج كملف بيكل وتم نشره على خادم الويب كجزء من حزمة الخدمة التطبيقية REST. ومع ذلك، في المشاريع الحقيقية، يتم تسجيل إصدارات النماذج ويرافقها معلومات حول البيانات ويتم حمايتها، وتحتاج تجارب التدريب إلى تسجيلها والحفاظ على قابليتها لإعادة الإنتاج. علاوة على ذلك، من وجهة نظر الهيكلة المعمارية، تخزين النموذج في نظام الملفات بجانب التطبيق يتناقض مع مبدأ المسؤولية الواحدة. مثال جيد هو الهيكلة القائمة على الخدمات المجزأة. توسيع خدمة النموذج أفقيًا يعني أن كل مثيل من مثيلات الخدمة المجزأة سيمتلك نسخة من الملف المادي المحفوظ بيكل من نفس الإصدار في جميع مثيلات الخدمة. وهذا يعني أيضًا أن دعم إصدارات متعددة من النماذج سيتطلب إصدارًا جديدًا وإعادة توزيع الخدمة التطبيقية REST وبنيتها التحتية. الهدف من هذه المقالة هو فصل النماذج عن بنية خدمة الويب وتمكين إعادة استخدام منطق خدمة الويب مع إصدارات مختلفة من النماذج.
قبل الغوص في التنفيذ، دعونا نتحدث قليلاً عن النماذج الإحصائية ونموذج VAR المستخدم في هذا المشروع. النماذج الإحصائية هي نماذج رياضية، وكذلك نماذج التعلم الآلي. المزيد عن الفرق بين الاثنين يمكن العثور عليه في المقالة الأولى من السلسلة. النموذج الإحصائي عادةً ما يحدد كعلاقة رياضية بين متغير عشوائي واحد أو أكثر والمتغيرات غير العشوائية. نموذج الاستقلاب الذاتي المتجه (VAR) هو نموذج إحصائي يُستخدم للتقاط العلاقة بين عدد متعدد من الكميات كما تتغير عبر الزمن. تعميم نماذج VAR النموذج الاستقلابي الذاتي للمتغير الفردي (AR) عن طريق السماح بسلاسل زمنية متعددة الأبعاد. في المشروع المقدم، يتم تدريب النموذج للقيام بالتوقعات لمتغيرين. غالباً ما يستخدم نماذج VAR في الاقتصاد والعلوم الطبيعية. بشكل عام، يتم تمثيل النموذج بواسطة نظام من المعادلات، والتي في المشروع تكمن وراء مكتبة Python statsmodels.
تم تصوير بنية وظيفة التطبيق نموذج VAR في الصورة التالية:
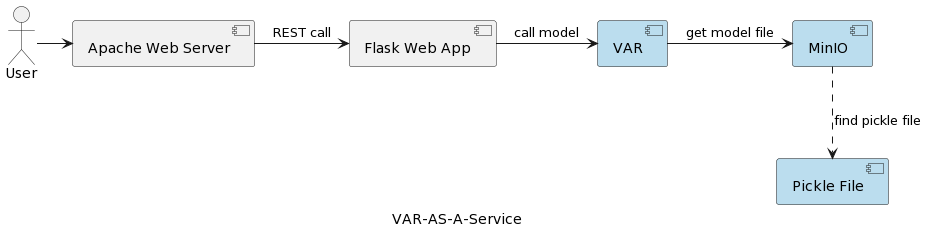
المكون التشغيلي VAR يمثل تنفيذ النموذج الفعلي على أساس المعلمات التي يرسلها المستخدم. يتصل بخدمة MinIO عبر واجهة REST، ويحمل النموذج، ويعمل على التنبؤ. بالمقارنة مع الحل في المقالة الأولى، حيث يتم تحميل وتحليل النموذج VARMAX عند بدء تشغيل التطبيق، يتم قراءة النموذج VAR من خادم MinIO في كل مرة يتم فيها تشذيب التنبؤ. ويأتي هذا بتكلفة إضافية في وقت التحميل والتحليل ولكن أيضًا بميزة امتلاك أحدث إصدار من النموذج المنشور في كل تشغيل. علاوة على ذلك، يمكّن من تصنيف الإصدارات الديناميكية للنماذج، مما يجعلها قابلة للوصول تلقائيًا للأنظمة الخارجية والمستخدمين النهائيين، كما سيظهر لاحقًا في المقالة. لاحظ أنه بسبب تكلفة التحميل هذه، فإن أداء الخدمة التخزينية المختارة مهم للغاية.
ولكن لماذا MinIO والتخزين على شكل كائن بشكل عام؟
MinIO هو حل تخزين الكائنات عالي الأداء يوفر دعمًا مباشرًا لنشرات Kubernetes ويقدم واجهة برمجة تطبيقات (API) متوافقة مع خدمة أمازون ويب سيرفرز S3 ويدعم جميع ميزات S3 الأساسية. في المشروع المقدم، يعمل MinIO بوضع الوحدة المنفردة، وهو يتألف من خادم MinIO واحد ومحور أو حجرة تخزين واحدة على نظام التشغيل لينكس باستخدام Docker Compose. للبيئات التطويرية الموسعة أو الإنتاجية، يوجد خيار وضع التوزيع الموصى به في المقال الموجود نشر MinIO بوضع التوزيع.
دعونا نلقي نظرة سريعة على بعض البدائل للتخزين بينما يمكن العثور على وصف شامل هنا وهنا:
- تخزين الملفات المحلي/الموزع: تشمل حلول تخزين الملفات المحلية المستخدمة في المقالة الأولى، حيث تعتبر الخيار الأبسط. يتم إجراء الحساب والتخزين على نفس النظام. يمكن اعتبارها مقبولة خلال مرحلة البرهان على المفهوم أو لنماذج بسيطة جدًا تدعم نسخة واحدة فقط من النموذج. تتصل أنظمة تخزين الملفات المحلية بقدرات تخزين محدودة ولا تكون مناسبة لمجموعات بيانات أكبر في حالة الرغبة في تخزين بيانات معلومات إضافية مثل مجموعة التدريب المستخدمة. نظرًا لإمكانية تكرار أو توسيع تلقائي غير متاحة، لا يمكن أن تعمل أنظمة تخزين الملفات المحلية بطريقة متاحة وموثوق بها وقابلة للتوسع. يتم نشر كل خدمة موزعة أفقيًا بنسختها الخاصة من النموذج. علاوة على ذلك، يكون التخزين المحلي آمنًا بقدر أمان النظام الضام. بديلات تخزين الملفات المحلية تشمل ذاكرة الوصول الشبكي (NAS) وشبكة التخزين المحدود (SAN) وأنظمة الملفات الموزعة (نظام الملفات الموزع Hadoop (HDFS) ونظام الملفات Google (GFS) ونظام الملفات المرن Amazon (EFS) وملفات Azure). بالمقارنة مع أنظمة تخزين الملفات المحلية، تتميز هذه الحلول بالتوفر والقابلية للتوسع والمرونة ولكنها تأتي مع تعقيد زيادة بتكلفة.
- قواعد البيانات العلائقية: نظرًا لتجميعة النماذج الثنائية، توفر قواعد البيانات العلائقية الخيار لتخزين BLOB أو بيانات ثنائية في أعمدة الجداول. يعرف مطورو البرامج والعديد من علماء البيانات بقواعد البيانات العلائقية، مما يجعل هذا الحل بديهيًا. يمكن تخزين إصدارات النماذج كصفوف جداول منفصلة مع بيانات استدعاء إضافية، وهو أمر سهل للقراءة من القاعدة البيانات أيضًا. تكمن المشكلة في أن القاعدة البيانات ستتطلب مساحة تخزين أكبر، وهذا سيؤثر على النسخ الاحتياطية. وجود كميات كبيرة من البيانات الثنائية في قاعدة بيانات يمكن أن يكون لها أيضًا تأثير على الأداء. علاوة على ذلك، تفرض قواعد البيانات العلائقية بعض القيود على هياكل البيانات، مما قد يعقد تخزين بيانات متنوعة مثل ملفات CSV وصور وملفات JSON كبيانات استدعاء للنماذج.
- تخزين الكائنات: تواجد تخزين الكائنات منذ فترة طويلة لكنه تطور عندما جعلته أمازون أول خدمة AWS في عام 2006 بخدمة التخزين البسيط (S3). التخزين الكائني الحديث هو أصلي للغرض المتعلق بالسحابة، وبدأت السحب الأخرى بسرعة في تقديم خدماتها أيضًا. تقدم مايكروسوفت خزّنة أزير Blob Storage، ولدى جوجل خدمة Google Cloud Storage. واجهة S3 هي المعيار الوافد من المعتاد للمطورين للتفاعل مع التخزين في السحابة، وهناك العديد من الشركات التي تقدم تخزين متوافق مع S3 للسحابة العامة، السحابة الخاصة، والحلول الخاصة على الأجهزة. بغض النظر عن مكان وجود مخزن الكائن، يتم الوصول إليه عبر واجهة RESTful. على الرغم من أن تخزين الكائن يلغي الحاجة إلى الدلائل والمجلدات والتنظيم الهرمي المعقد الآخر، إلا أنه ليس حلًا جيدًا للبيانات الديناميكية التي تتغير باستمرار حيث تحتاج لإعادة كتابة الكائن بالكامل لتعديله، لكنه خيار جيد لتخزين النماذج المتسلسلة وأوصاف النموذج.
A summary of the main benefits of object storage are:
- القابلية الكبيرة للتوسع: حجم تخزين الكائنات غير محدود أساسًا، لذا يمكن للبيانات أن تتسع إلى إكسابايت ببساطة عن طريق إضافة أجهزة جديدة. أيضًا، تعمل حلول تخزين الكائنات بشكل أفضل عند تشغيلها كمجموعة موزعة.
- التبسيط: يتم تخزين البيانات في بنية ثابتة. نظرًا لعدم وجود أشجار أو تجزئة معقدة (لا مجلدات أو دلائل) يقلل من تعقيد استرداد الملفات حيث لا يحتاج المرء إلى معرفة المكان الدقيق.
- قابلية البحث: يعتبر البيانات الوصفية جزءًا من الكائنات، مما يجعل البحث والتنقل سهلًا دون الحاجة إلى تطبيق إضافي. يمكن تصنيف الكائنات بوصفات ومعلومات، مثل الاستهلاك والتكلفة وسياسات الحذف التلقائي والاحتفاظ والطبقات. نظرًا للفضاء المسمى المسطح للتخزين الأساسي (كل كائن في سلة واحدة ولا توجد سلال داخل سلال)، يمكن لمخازن الكائنات العثور على كائن من بين حتمًا مليارات الكائنات بسرور.
- المرونة: يمكن لتخزين الكائنات تكرار البيانات تلقائيًا وتخزينها عبر أجهزة ومواقع جغرافية متعددة. يمكن أن يساعد هذا في حماية من الانقطاعات والحماية من فقدان البيانات ودعم استراتيجيات استعادة الكوارث.
- البساطة: استخدام واجهة REST API لتخزين واسترداد النماذج يعني تقريبًا عدم وجود منحنى تعلم ويجعل التكاملات في التطبيقات القائمة على الميكروخدمات خيارًا طبيعيًا.
حان الوقت للنظر في تطبيق نموذج VAR كخدمة والتكامل مع MinIO. تتم النشر في الحل المقترح باستخدام Docker وDocker Compose، مما يبسط تنظيم المشروع ككل على النحو التالي:

كما في المقالة الأولى، تتألف تحضير النموذج من عدد قليل من الخطوات المكتوبة في سكربت بايثون يسمى var_model.py وهو موجود في مستودع مخصص GitHub repository :
- تحميل البيانات
- تقسيم البيانات إلى مجموعة التدريب ومجموعة الاختبار
- تحضير المتغيرات الداخلية
- العثور على المعلمة المثلى p (أول p تأخير لكل متغير مستخدمة كمتنبئات للانحدار)
- تهيئة النموذج بالمعلمات المثلى المحددة
- تحويل النموذج المهيئ إلى ملف بيكل
- تخزين ملف بيكل ككائن محدد الإصدار في دليل MinIO
يمكن تنفيذ هذه الخطوات أيضًا كمهام في محرك سير عمل (مثل أباتشي إيرفلو) تحفزه الحاجة إلى تدريب نسخة جديدة من النموذج ببيانات أحدث. DAGs وتطبيقاتها في MLOps ستكون محور مقال آخر.
آخر خطوة مُنفذة في var_model.py هي تخزين النموذج المحفوظ كملف بيكل في دليل في S3. بسبب تركيبة التخزين الأبسط، التنسيق المختار هو:
<اسم الدليل>/<اسم الملف>
ومع ذلك، بالنسبة لأسماء الملفات، يُسمح باستخدام الشريط الأفقي لتقليد البنية الهرمية، مع الحفاظ على ميزة البحث الخطي السريع. الاتفاقية لتخزين نماذج VAR كما يلي:
models/var/0_0_1/model.pkl
حيث أسم الحزمة هو models, وأسم الملف هو var/0_0_1/model.pkl وفي واجهة MinIO، يبدو كما يلي:

هذه طريقة مريحة لتنظيم أنواع وإصدارات مختلفة من النماذج مع الحفاظ على أداء وبساطة التخزين المسطح للملفات.
لاحظ أن تنفيذ تحديث الإصدارات هو جزء من اسم النموذج. MinIO يوفر تحديث الملفات أيضًا، لكن الطريقة المختارة هنا لها بعض الفوائد:
- دعم إصدارات اللقطات والتجاوز
- استخدام تحديث الإصدارات الدلالية (النقاط تم استبدالها بـ ‘_’ بسبب القيود)
- تحكم أكبر في استراتيجية تحديث الإصدارات
- فصل الآلية التخزين الأساسية من حيث ميزات تحديث الإصدارات المحددة
بمجرد نشر النموذج، يحين الوقت لتعريضه كخدمة REST باستخدام Flask ونشره باستخدام docker-compose يعمل MinIO وخادم ويب أباتشي. يمكن العثور على صورة Docker، وكذلك رمز النموذج، في مستودع GitHub المخصص.
وأخيرًا، الخطوات اللازمة لتشغيل التطبيق هي:
- نشر التطبيق:
docker-compose up -d - اجراء خوارزمية تحضير النموذج:
python var_model.py(تتطلب خدمة MinIO مشغولة) - تحقق مما إذا كان النموذج قد تم نشره: http://127.0.0.1:9101/browser
- اختبر النموذج:
http://127.0.0.1:80/apidocs
بعد نشر المشروع، يمكن الوصول إلى واجهة برمجة التطبيقات Swagger عبر <host>:<port>/apidocs (على سبيل المثال، 127.0.0.1:80/apidocs). يوجد نقطة نهاية واحدة لنموذج VAR تظهر بجانب الاثنين الآخرين التي تعرض نموذج VARMAX:
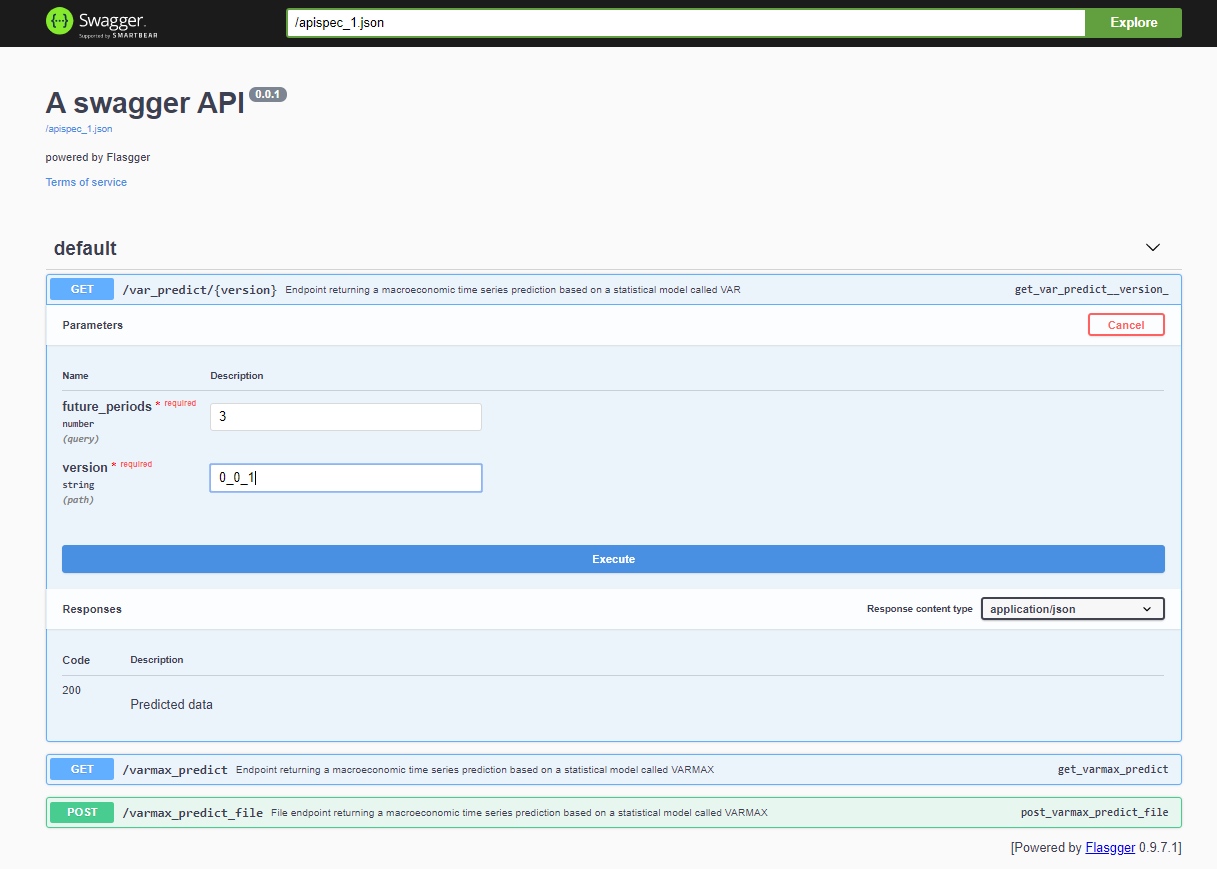
داخليًا، تستخدم الخدمة ملف pickle للنموذج المتحصل عليه من خدمة MinIO:
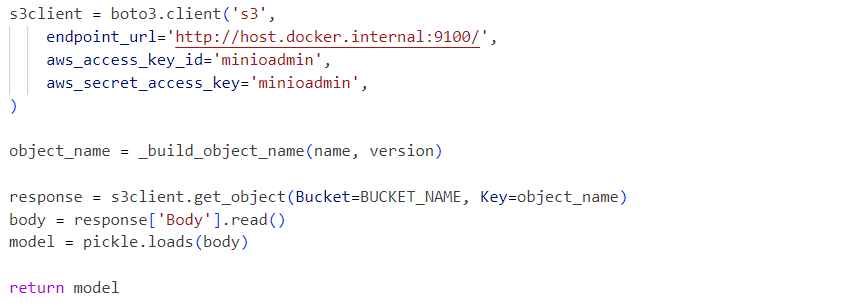
يتم إرسال الطلبات إلى النموذج المبدئي على النحو التالي:

المشروع المقدم هو دورة عمل نموذج VAR مبسطة يمكن توسيعها خطوة بخطوة مع وظائف إضافية مثل:
- استكشف تنسيقات التجميع القياسية واستبدل pickle بحل آخر
- تكامل أدوات تصور بيانات السلاسل الزمنية مثل Kibana أو Apache Superset
- تخزين بيانات السلاسل الزمنية في قاعدة بيانات السلاسل الزمنية مثل Prometheus, TimescaleDB, InfluxDB, أو تخزين الكائنات مثل S3
- توسيع الخريطة بخطوات تحميل البيانات ومعالجة البيانات
- تضمين تقارير المقاييس كجزء من الخرائط
- تنفيذ الخرائط باستخدام أدوات محددة مثل Apache Airflow أو AWS Step Functions أو أدوات قياسية أكثر مثل Gitlab أو GitHub
- قارن أداء ودقة نماذج الإحصاء مع نماذج التعلم الآلي
- تنفيذ حلول متكاملة بالسحابة من النهاية إلى النهاية، بما في ذلك خدمات البنية التحتية-كود
- تعريض نماذج إحصائية أخرى ونماذج ML كخدمات
- تنفيذ واجهة برمجة التطبيقات لتخزين النماذج تجاهل الآلية الفعلية للتخزين وتسجيل إصدارات النموذج، وتخزين بيانات معالجة النموذج والبيانات التدريبية
ستكون هذه التحسينات المستقبلية هدفًا للمقالات والمشاريع القادمة. الهدف من هذا المقال هو دمج واجهة تخزين متوافقة مع S3 وتمكين تخزين النماذج المسجلة. سيتم استخراج هذه الوظيفة في مكتبة منفصلة قريبًا. يمكن نشر الحل التكاملي الأساسي المقدم في الإنتاج وتحسينه كجزء من عملية التوسيع المستمر والتيار المستمر بمرور الوقت، كما يمكن استخدام خيارات التوزيع الموزعة لـ MinIO أو استبدالها بـ AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service