













خدمة Amazon Simple Storage Service (S3) هي خدمة تخزين الكائنات عالية القابلية للتوسع والدعم والأمان التي تقدمها Amazon Web Services (AWS). تسمح S3 للشركات بتخزين واسترداد أي كمية من البيانات من أي مكان على شبكة الويب عن طريق استخدام خدماتها عالية المستوى. تم تصميم S3 لتكون عالية التوافق وتتماشى بسلاسة مع الأدوات والتقنيات الأخرى من Amazon Web Services (AWS) ومن جهات ثالثة لمعالجة البيانات المخزنة في Amazon S3. ومن ضمنها Amazon EMR (Elastic MapReduce) الذي يتيح لك معالجة كميات كبيرة من البيانات باستخدام أدوات المفتوح المصدر مثل Spark.
Apache Spark هو نظام معالجة البيانات الموزعة عالية المستوى مفتوح المصدر المستخدم لمعالجة البيانات على نطاق واسع. تم تصميم Spark لتمكين السرعة ويدعم أنواعًا مختلفة من مصادر البيانات، بما في ذلك Amazon S3. يوفر Spark طريقة فعالة لمعالجة كميات كبيرة من البيانات وإجراء حسابات معقدة في وقت قصير جدًا.
Memphis.dev هو بديل الجيل التالي للمزرعات التقليدية. مزرعة رسائل السحابة الموجهة البسيطة والقوية والدائمة ملفقة بنظام كامل يمكنك من تطوير استخدامات قائمة على الطوابير الحديثة بشكل موفر للتكلفة وسريع وموثوق به.
النمط الشائع للمزرعات هو حذف الرسائل بعد تجاوز السياسة الاحتفاظ المحددة، مثل الوقت/الحجم/عدد الرسائل. تقدم ممفيس بروتوكول إضافي للاحتفاظ طويل الأمد، وربما لا نهائي للرسائل المخزنة. كل رسالة تتخلف عن المحطة ستنتقل تلقائيًا إلى البروتوكول الإضافي، وفي هذه الحالة هو AWS S3.
في هذا البرنامج التعليمي، ستُوجه خلال عملية إعداد محطة Memphis بفئة تخزين ثانية متصلة بـ AWS S3. بيئة على AWS. تليها إنشاء سلطح S3، إعداد مجموعة EMR، تثبيت وتكوين Apache Spark على المجموعة، تحضير البيانات في S3 للمعالجة، معالجة البيانات باستخدام Apache Spark، أفضل الممارسات، وضبط الأداء.
إعداد البيئة
ممفيس
- للبدء، أولاً تثبيت ممفيس.
- تمكين تكامل AWS S3 عبر مركز التكامل الخاص بـ Memphis.
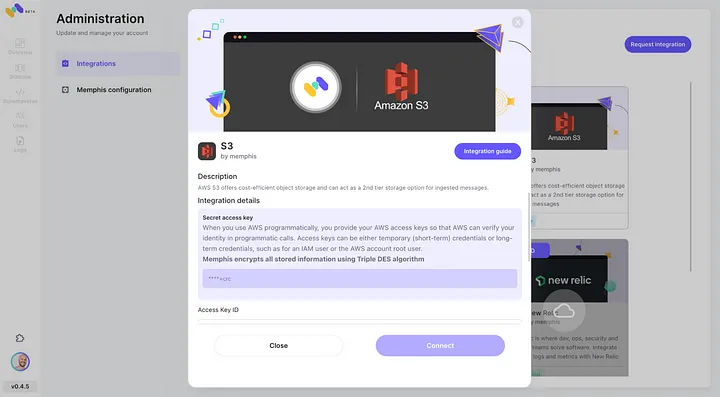
3. إنشاء محطة (موضوع)، واختيار سياسة الاحتفاظ.
4. كل رسالة تجتاز سياسة الاحتفاظ المؤهلة ستُنقل إلى سلطح S3.
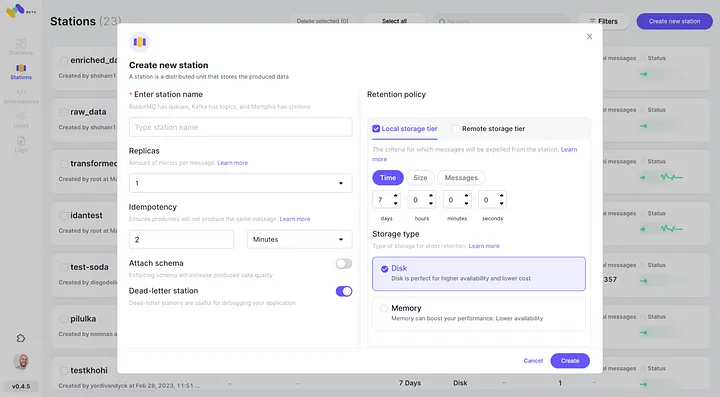
5. تحقق من التكامل الجديد مع AWS S3 كفئة تخزين ثانية عن طريق النقر فوق “الاتصال”.
6. بدء إنتاج الأحداث لمحطة Memphis الجديدة التي أنشأتها.
إنشاء سلطح AWS S3
إذا لم تقم بذلك بالفعل، أولاً، تحتاج إلى إنشاء حساب AWS حساب. بعد ذلك، قم بإنشاء سلة من S3 حيث يمكنك تخزين بياناتك. يمكنك استخدام وحدة تحكم AWS، وحدة تحكم الواجهة الأوتوماتيكية لـ AWS، أو SDK لإنشاء سلة. في هذا البرنامج التعليمي، ستستخدم وحدة تحكم AWS وحدة تحكم.
انقر على “إنشاء سلة.”
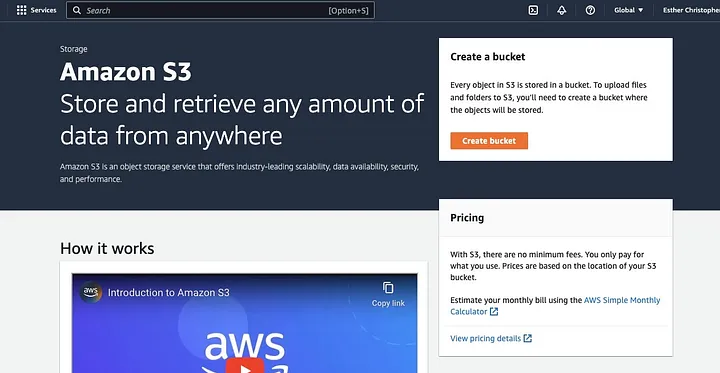
ثم انتقل لإنشاء اسم سلة يتوافق مع اتفاقية التسمية واختر المنطقة التي ترغب في توجيه السلة لها. قم بتكوين “ملكية الكائن” و”حجب كافة الوصول العام” وفقًا لحالة الاستخدام الخاصة بك.
تأكد من تكوين الأذونات الأخرى للسلة للسماح لتطبيق Spark الخاص بك بالوصول إلى البيانات. أخيرًا، انقر على زر “إنشاء سلة” لإنشاء السلة.
إعداد مجموعة EMR بتثبيت Spark
Amazon Elastic MapReduce (EMR) هو خدمة ويب تعتمد على Apache Hadoop تسمح للمستخدمين بمعالجة كميات هائلة من البيانات بشكل عملاق باستخدام تقنيات البيانات الكبيرة، بما في ذلك Apache Spark. لإنشاء مجموعة EMR بتثبيت Spark، افتح وحدة تحكم EMR وحدد “المجموعات” تحت “EMR on EC2” على الجانب الأيسر من الصفحة.
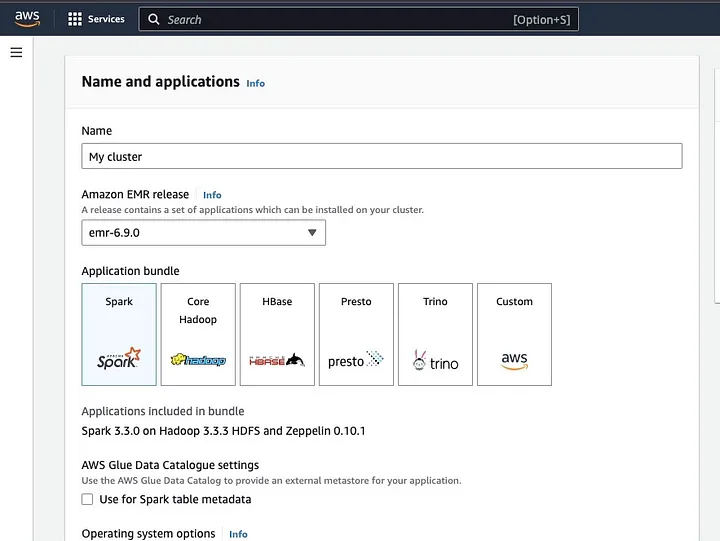
انقر على “إنشاء مجموعة” وأعط المجموعة اسمًا وصفيًا. تحت “حزمة التطبيقات”، حدد Spark لتثبيته على مجموعتك.
انتقل لأسفل إلى قسم “سجلات الكتلة” وحدد خانة الاختيار لنشر سجلات محددة للكتلة إلى أمازون S3.
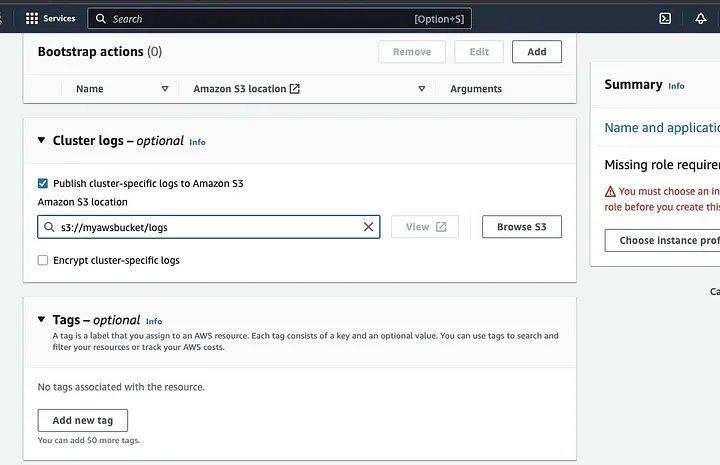
سيؤدي هذا إلى إنشاء موجه لإدخال موقع أمازون S3 باستخدام اسم دليل S3 الذي أنشأته في الخطوة السابقة، متبوعًا بـ /logs، على سبيل المثال، s3://myawsbucket/logs. /logs ضرورية من قبل أمازون لإنشاء مجلد جديد في دليلك حيث يمكن لأمازون EMR نسخ ملفات سجل الكتلة الخاصة بك.
انتقل إلى قسم “تهيئة الأمان والأذونات” وأدخل مفتاح EC2 الخاص بك أو استمر بخيار إنشاء واحد.
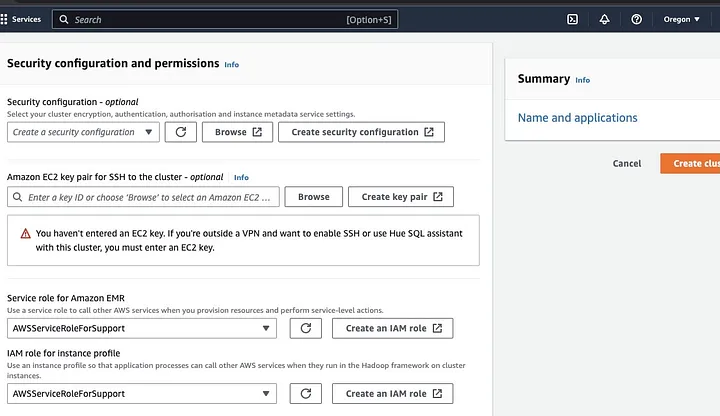
ثم انقر فوق خيارات المنسدلة لـ “دور الخدمة لأمازون EMR” واختر AWSServiceRoleForSupport. اختر نفس خيار المنسدلة لـ “دور IAM لملف تعريف المثيل”. تحديث رمز التحديث إن لزم الأمر للحصول على خيارات المنسدلة هذه.
أخيرًا، انقر فوق زر “إنشاء كتلة” لبدء الكتلة ومراقبة حالة الكتلة للتحقق من أنها تم إنشاؤها.
تثبيت وتهيئة أباتشي سبارك على كتلة EMR
بعد نجاح إنشاء كتلة EMR، ستأتي الخطوة التالية هي تهيئة أباتشي سبارك على كتلة EMR. توفر كتل EMR بيئة مدارة تلقائيًا لتشغيل تطبيقات سبارك على بنية AWS، مما يجعل من السهل بدء وإدارة كتل سبارك في السحابة. يقوم بتهيئة سبارك للعمل مع بياناتك واحتياجات المعالجة ومن ثم يقوم بتقديم عمليات سبارك إلى الكتلة لمعالجة بياناتك.
يمكنك تكوين Apache Spark للكومة باستخدام بروتوكول Secure Shell (SSH). ولكن أولاً، تحتاج إلى تفعيل اتصالات الأمان الخاصة بـ SSH للكومة التي قد تم تعيينها افتراضيًا عند إنشاء كومة EMR. يمكن العثور على دليل حول كيفية تفعيل اتصالات SSH هنا.
لإنشاء اتصال SSH، تحتاج إلى تحديد زوج المفاتيح EC2 الذي اخترته عند إنشاء الكومة. ثم اتصل بكومة EMR باستخدام جهاز Spark بتوصيل العقدة الأساسية أولاً. تحتاج أولاً إلى استيراد الإحداثيات العامة للعقدة الأساسية من القائمة اليسرى في واجهة برمجة التطبيقات AWS، تحت EMR on EC2، اختر Clusters، ثم حدد الكومة التي تريد الحصول على اسم الإحداثيات العام لها.
في المحطة النظام الخاصة بك، أدخل الأمر التالي.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemاستبدل ec2-###-##-##-###.compute-1.amazonaws.com باسم الإحداثيات العام الخاصة بك و~/mykeypair.pem باسم ملف ومسار الملف .pem الخاص بك (اتبع هذا الدليل للحصول على الملف .pemملف). سيظهر رسالة فورية تتطلب منك الرد بنعم — اكتب exit لإغلاق أمر SSH.
تحضير البيانات للمعالجة مع Spark ورفعها إلى س
يتطلب معالجة البيانات التحضير قبل التحميل لتقديم البيانات بتنسيق يمكن لـ Spark معالجته بسهولة. يتم توجيه التنسيق بناءً على نوع البيانات الذي تمتلكه والتحليل الذي تعتزم إجراؤه. تشمل بعض التنسيقات المستخدمة CSV و JSON و Parquet.
قم بإنشاء جلسة Spark جديدة وقم بتحميل بياناتك إلى Spark باستخدام الواجهة المناسبة. على سبيل المثال، استخدم طريقة spark.read.csv() لقراءة ملفات CSV إلى فئة DataFrame في Spark.
يمكن استخدام Amazon EMR، وهي خدمة مدارة بالنسبة لأكواد النظام Hadoop، لمعالجة البيانات. يقلل من الحاجة إلى إعداد وضبط وصيانة الأكواد. كما تتميز بتكاملات أخرى مع Amazon SageMaker، على سبيل المثال، لبدء مهمة تدريب نموذج SageMaker من خطة Spark في Amazon EMR.
بمجرد إعداد بياناتك، باستخدام طريقة DataFrame.write.format("s3")، يمكنك قراءة ملف CSV من خزنة Amazon S3 إلى فئة DataFrame في Spark. يجب أن يكون لديك مصادقات AWS المهيأة وأذونات كتابة للوصول إلى خزنة S3.
حدد خزنة S3 ومسار حيث تريد حفظ البيانات. على سبيل المثال، يمكنك استخدام طريقة df.write.format("s3").save("s3://my-bucket/path/to/data") لحفظ البيانات في الخزنة المحددة.
بمجرد حفظ البيانات في خزنة S3، يمكنك الوصول إليها من تطبيقات Spark أخرى أو أدوات، أو يمكنك تنزيلها لإجراء تحليل أو معالجة إضافية. لتحميل الخزنة، قم بإنشاء مجلد واختر الخزنة التي أنشأتها في البداية. اختر زر الإجراءات، وانقر على “إنشاء مجلد” في العناصر المنسدلة. يمكنك الآن تسمية المجلد الجديد.
لتحميل ملفات البيانات إلى الحاوية، اختر اسم مجلد البيانات.
في التحميل — اختر “خريطة الملفات” واختر إضافة ملفات.
اتبع توجيهات واجهة سطح المكتب Amazon S3 لتحميل الملفات واختر “ابدأ التحميل”.
من المهم التأكد من اتباع أفضل الممارسات لتأمين بياناتك قبل تحميل بياناتك إلى حاوية S3.
فهم تنسيقات البيانات والمخططات
تنسيقات البيانات والمخططات هي مفاهيم متعلقة جداً ولكن مختلفة تماماً ومهمة في إدارة البيانات. تنسيق البيانات يشير إلى تنظيم وبنية البيانات داخل قاعدة البيانات. هناك تنسيقات مختلفة لتخزين البيانات، أي CSV، JSON، XML، YAML، إلخ. تعرف هذه التنسيقات كيف يجب تنظيم البيانات جنباً إلى جنب مع أنواع البيانات والتطبيقات المختلفة المطبقة عليها. في الوقت نفسه، المخططات البيانات هي بنية قاعدة البيانات نفسها. يحدد تخطيط قاعدة البيانات تخطيط قاعدة البيانات ويضمن حفظ البيانات بشكل مناسب. يحدد مخطط قاعدة البيانات العروض، الجداول، الفهارس، الأنواع، والعناصر الأخرى. هذه المفاهيم مهمة في التحليلات وتصور قاعدة البيانات.
تنظيف ومعالجة البيانات في S3
من الضروري التأكد من أخذ الأخطاء في بياناتك بعين الاعتبار قبل معالجتها. للبدء، قم بالوصول إلى مجلد البيانات الذي قمت بحفظ ملف البيانات في حاوية S3 الخاصة بك، وتنزيله إلى جهاز الكمبيوتر المحلي. بعد ذلك، ستقوم بتحميل البيانات إلى أداة معالجة البيانات، والتي ستستخدم لتنظيف ومعالجة البيانات. في هذا البرنامج التعليمي، تم استخدام أداة المعالجة المستخدمة هي Amazon Athena التي تساعد على تحليل البيانات غير المنظمة والمنظمة المخزنة في Amazon S3
اذهب إلى أمازون أثينا في واجهة AWS Console.
انقر على “إنشاء” لإنشاء جدول جديد ثم “إنشاء جدول”.
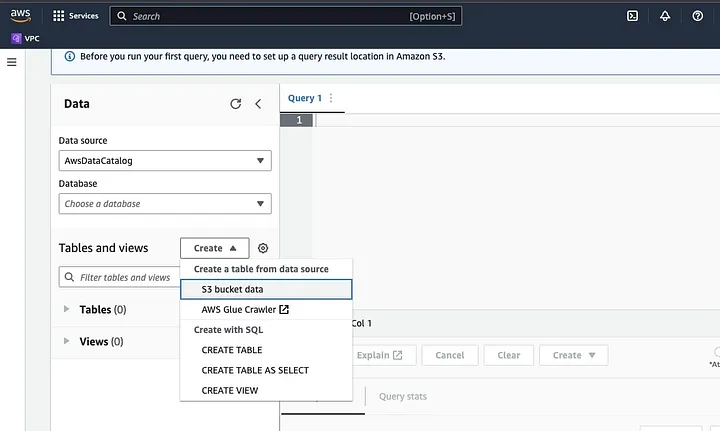
اكتب مسار ملف بياناتك في الجزء المظلل بـ LOCATION.
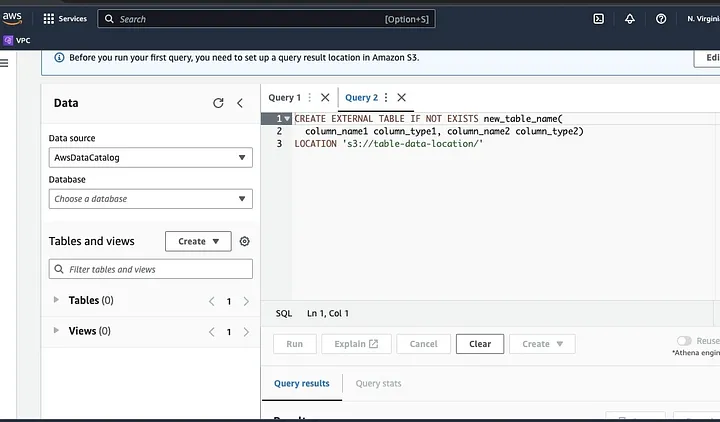
اتبع المطالب لتعريف الشيمات للبيانات وحفظ الجدول. الآن، يمكنك تشغيل عملية استعلام للتحقق من صحة التحميل ومن ثم تنظيف ومعالجة البيانات
مثال:
هذا الاستعلام يحدد التكرارات الموجودة في البيانات.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;هذا المثال يخلق جدولًا جديدًا بدون التكرارات:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;أخيرًا، استيراد البيانات المنظفة إلى S3 من خلال التنقل إلى سلة التخزين S3 والمجلد لتحميل الملف.
فهم إطار العمل Spark
إطار العمل Spark هو نظام حوسبة الكتل المفتوح المصدر، بسيط، ومعبر عنه بشكل كبير الذي تم بناؤه للتطوير السريع. يعتمد على لغة البرمجة Java ويعمل كبديل لإطارات Java الأخرى. الميزة الأساسية لـ Spark هي قدرتها على حساب البيانات في الذاكرة التي تسرع معالجة مجموعات البيانات الكبيرة.
تكوين Spark للعمل مع S3
لتكوين Spark للعمل مع S3، ابدأ من خلال إضافة الاعتماد Hadoop AWS إلى تطبيق Spark الخاص بك. افعل ذلك من خلال إضافة السطر التالي إلى ملف بنائك (على سبيل المثال، build.sbt لـ Scala أو pom.xml لـ Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"أدخل مفتاح الوكالة ID المصرح به ومفتاح الوكالة السرية في تطبيق Spark الخاص بك عن طريق تعيين الخصائص التالية:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>قم بتعيين الخصائص التالية باستخدام كائن SparkConf في الكود الخاص بك:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")قم بتعيين عنوان URL نقطة التواصل S3 في تطبيق Spark الخاص بك عن طريق تعيين الخاصية التكوينية التالية:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comاستبدل <REGION> بمنطقة AWS التي توجد بها سلة المحفظة S3 الخاصة بك (على سبيل المثال، us-east-1).
يلزم إسم سلة المحفظة التوافقية مع DNS لمنح عميل S3 في Hadoop الوصول لطلبات S3. إذا كان إسم سلة المحفظة الخاصة بك يحتوي على نقاط أو خطوط أفقية، قد تحتاج لتمكين الوصول بأسلوب الطريق لأجل عميل S3 في Hadoop، الذي يستخدم أسلوب الموقع الافتراضي. قم بتعيين الخاصية التكوينية التالية لتمكين الوصول بطريقة طريق المسار:
spark.hadoop.fs.s3a.path.style.access trueأخيرًا، قم بإنشاء جلسة Spark بتكوين S3 عن طريق تعيين سابقة spark.hadoop في تكوين Spark:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()استبدل حقول <ACCESS_KEY_ID>، <SECRET_ACCESS_KEY>، و <REGION> ببيانات الوصول ومنطقة S3 الخاصة بك.
لقراءة البيانات من S3 في Spark، سيتم استخدام طريقة spark.read، ثم تحديد مسار S3 لبياناتك كمصدر إدخال.
مثال على رمز يوضح كيفية قراءة ملف CSV من S3 إلى DataFrame في Spark:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")في هذا المثال، استبدل <BUCKET_NAME> باسم سلة المحفظة S3 الخاصة بك و <FILE_PATH> بمسار ملف CSV الخاص بك داخل السلة.
تحويل البيانات باستخدام Spark
تحويل البيانات باستخدام Spark عادة ما يشير إلى العمليات على البيانات لتنظيفها، تصفيتها، تجميعها، وربط البيانات. يتيح Spark مجموعة واسعة من واجهات برمجة التطبيقات (APIs) لتحويل البيانات. تشمل هذه واجهة DataFrame، Dataset، و RDD. تشمل بعض العمليات الشائعة لتحويل البيانات في Spark التصفية، اختيار الأعمدة، تجميع البيانات، ضم البيانات، وفرز البيانات.
فيما يلي مثال على عمليات تحويل البيانات:
فرز البيانات: تتضمن هذه العملية فرز البيانات حسب عمود أو أكثر. يتم استخدام طريقة orderBy أو sort على DataFrame أو Dataset لفرز البيانات حسب عمود أو أكثر. على سبيل المثال:
val sortedData = df.orderBy(col("age").desc)أخيرًا، قد تحتاج إلى كتابة النتيجة مرة أخرى إلى S3 لتخزين النتائج.
يوفر Spark واجهات برمجة التطبيقات مختلفة لكتابة البيانات إلى S3، مثل DataFrameWriter، DatasetWriter، و RDD.saveAsTextFile.
الآتي مثال على الكود يوضح كيفية كتابة DataFrame إلى S3 بتنسيق Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)استبدل حقل المدخلات <BUCKET_NAME> باسم خزانة S3 الخاصة بك و <OUTPUT_DIRECTORY> بالمسار إلى الدليل المخرج في الخزانة.
تحدد طريقة mode نمط الكتابة، والذي يمكن أن يكون Overwrite، Append، Ignore، أو ErrorIfExists. يمكن استخدام طريقة option لتحديد خيارات مختلفة لتنسيق المخرج، مثل ترميز ضغط الطرد المركزي.
يمكنك أيضًا كتابة البيانات إلى S3 بتنسيقات أخرى، مثل CSV، JSON، و Avro، من خلال تغيير تنسيق المخرج وتحديد الخيارات المناسبة.
فهم تقسيم البيانات في سبارك
ببساطة، يشير تقسيم البيانات في سبارك إلى تقسيم مجموعة البيانات إلى أجزاء أصغر وأسهل في الإدارة عبر المجموعة. الهدف من هذا هو تحسين الأداء وتقليل القابلية للتوسع وتحسين في نهاية المطاف إدارة قواعد البيانات. في سبارك، يتم معالجة البيانات بشكل متوازي على عدة مجموعات. يتم إجراء هذا بفضل مجموعات البيانات الموزعة بصدق (RDD)، وهي مجموعة من البيانات الكبيرة والمعقدة. بشكل افتراضي، يتم تقسيم RDD عبر عقد مختلفة بسبب حجمها.
لأداء الأمر بشكل مثالي، هناك طرق لتكوين سبارك للتأكد من تنفيذ المهام بسرعة وإدارة الموارد بشكل فعال. تشمل بعض هذه الأمور التخزين المؤقت وإدارة الذاكرة وترميز البيانات واستخدام mapPartitions() على map().
واجهة برمجة تطبيقات سبارك (Spark UI) هي واجهة رسومية مبوبة تعرض معلومات شاملة حول أداء تطبيق سبارك واستخدام الموارد. تشمل عدة صفحات، مثل النظرة العامة والمُعالجين والمراحل والمهام، والتي توفر معلومات حول جوانب مختلفة من وظيفة سبارك. واجهة برمجة تطبيقات سبارك هي أداة هامة لمراقبة وتصحيح تطبيقات سبارك، حيث تساعد على تحديد نقاط ضعف الأداء وقيود الموارد وإصلاح الأخطاء. من خلال الفحص المقاييس مثل عدد المهام المكتملة، ومدة الوظيفة، واستخدام CPU والذاكرة، والبيانات المنجمعة المكتوبة والمقروء، يمكن للمستخدمين تحسين وظائف سبارك الخاصة بهم والتأكد من أنها تعمل بكفاءة.
الخاتمة
في المجمل، تحليل بياناتك على AWS S3 باستخدام أباتشي سبارك هو طريقة فعالة وقابلة للتوسع لتحليل مجموعات بيانات كبيرة. من خلال استخدام خزنة البيانات والموارد الحسابية المستندة إلى الغالبية لـ AWS S3 وأباتشي سبارك، يمكن للمستخدمين معالجة بياناتهم بسرور وفعالية دون الحاجة إلى القلق بشأن إدارة الهيكل التكنولوجي.
في هذا البرنامج التعليمي، تعرفنا على إعداد سلة الـ S3 ومجموعة أباتشي سبارك على AWS EMR، وتكوين سبارك للعمل مع AWS S3، وكتابة وتشغيل تطبيقات سبارك لمعالجة البيانات. كما تناولنا توزيع البيانات في سبارك، وواجهة برنامج التشغيل المتقدم في سبارك، وتحسين الأداء في سبارك.
مرجع
لمزيد من التفاصيل حول تكوين سبارك للحصول على أداء مثالي، انظر هنا.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark