













تطورت البيانات الضخمة بشكل كبير منذ بدايتها في أواخر العقد الأول من الألفية الثالثة. قامت العديد من المنظمات بسرعة بالتكيف مع الاتجاه وبناء منصات البيانات الضخمة الخاصة بها باستخدام أدوات مفتوحة المصدر مثل Apache Hadoop. في وقت لاحق، بدأت هذه الشركات تواجه مشاكل في إدارة احتياجات معالجة البيانات المتطورة بسرعة. لقد واجهوا تحديات في التعامل مع تغييرات مستوى المخطط، وتطور نظام التقسيم، والعودة بالزمن للنظر في البيانات.
واجهت تحديات مماثلة أثناء تصميم الأنظمة الموزعة واسعة النطاق في العقد 2010 لشركة تقنية كبيرة وعميل في مجال الرعاية الصحية. تحتاج بعض الصناعات إلى هذه القدرات للامتثال للوائح المصرفية والمالية والصحية. واجهت الشركات الثقيلة المعتمدة على البيانات مثل Netflix تحديات مماثلة أيضًا. لقد اخترعوا تنسيق جدول يسمى “Iceberg”، والذي يقع فوق الملفات البيانية الموجودة ويوفر ميزات رئيسية بالاستفادة من بنيته. وقد أصبح هذا بسرعة المشروع الأهم في ASF حيث اكتسب اهتمامًا سريعًا في مجتمع البيانات. سأستكشف في هذه المقالة أهم 5 ميزات لـ Apache Iceberg مع أمثلة ورسوم بيانية.
1. السفر عبر الزمن

الشكل 1: السفر عبر الزمن في تنسيق جدول Apache Iceberg (الصورة من إنشاء المؤلف)
تتيح لك هذه الميزة استعلام بياناتك كما توجد في أي نقطة زمنية. سيفتح هذا إمكانيات جديدة لمحللي البيانات والأعمال لفهم الاتجاهات وكيف تطورت البيانات مع مرور الوقت. يمكنك بسهولة الرجوع إلى حالة سابقة في حالة حدوث أي أخطاء. تسهل هذه الميزة أيضًا عمليات التدقيق من خلال السماح لك بتحليل البيانات في نقطة زمنية محددة.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. تطور المخطط
يسمح تطور مخطط Apache Iceberg بإجراء تغييرات على مخططك دون أي جهد كبير أو عمليات ترحيل مكلفة. مع تطور احتياجات عملك، يمكنك:
- إضافة وإزالة الأعمدة دون أي توقف أو إعادة كتابة للجداول.
- تحديث العمود (التوسيع).
- تغيير ترتيب الأعمدة.
- إعادة تسمية عمود موجود.
تتم معالجة هذه التغييرات على مستوى البيانات الوصفية دون الحاجة إلى إعادة كتابة البيانات الأساسية.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. تطور التقسيم
باستخدام تنسيق جدول Apache Iceberg، يمكنك تغيير استراتيجية تقسيم الجدول دون إعادة كتابة الجدول الأساسي أو نقل البيانات إلى جدول جديد. يتم تحقيق ذلك حيث أن الاستعلامات لا تشير مباشرة إلى قيم التقسيم كما في Apache Hadoop. يحافظ Iceberg على معلومات البيانات الوصفية لكل إصدار من التقسيم بشكل منفصل. يسهل هذا الحصول على الأجزاء أثناء استعلام البيانات. على سبيل المثال، استعلام جدول بناءً على نطاق زمني، بينما كان الجدول يستخدم الشهر كعمود تقسيم (قبل) كجزء واحد واليوم كعمود تقسيم جديد (بعد) كجزء آخر. يُطلق على هذا التخطيط الجزئي. انظر المثال أدناه.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. معاملات ACID
يوفر Iceberg دعمًا قويًا للمعاملات من حيث الذرية، التناسق، العزل، والدوام (ACID). يسمح بعمليات كتابة متزامنة متعددة، مما يمكّن من تحقيق إنتاجية عالية في الوظائف المكثفة بالبيانات دون المساس بتناسق البيانات.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
جميع العمليات في Iceberg تكون معاملاتية، مما يعني أن البيانات تظل متسقة بغض النظر عن الفشل أو التعديلات المتزامنة على البيانات.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
كما يدعم مستويات عزل مختلفة، مما يسمح لك بتوازن الأداء والتناسق بناءً على المتطلبات.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
إليك ملخص يوضح كيف يتعامل Iceberg مع التحديثات والحذف على مستوى الصفوف.
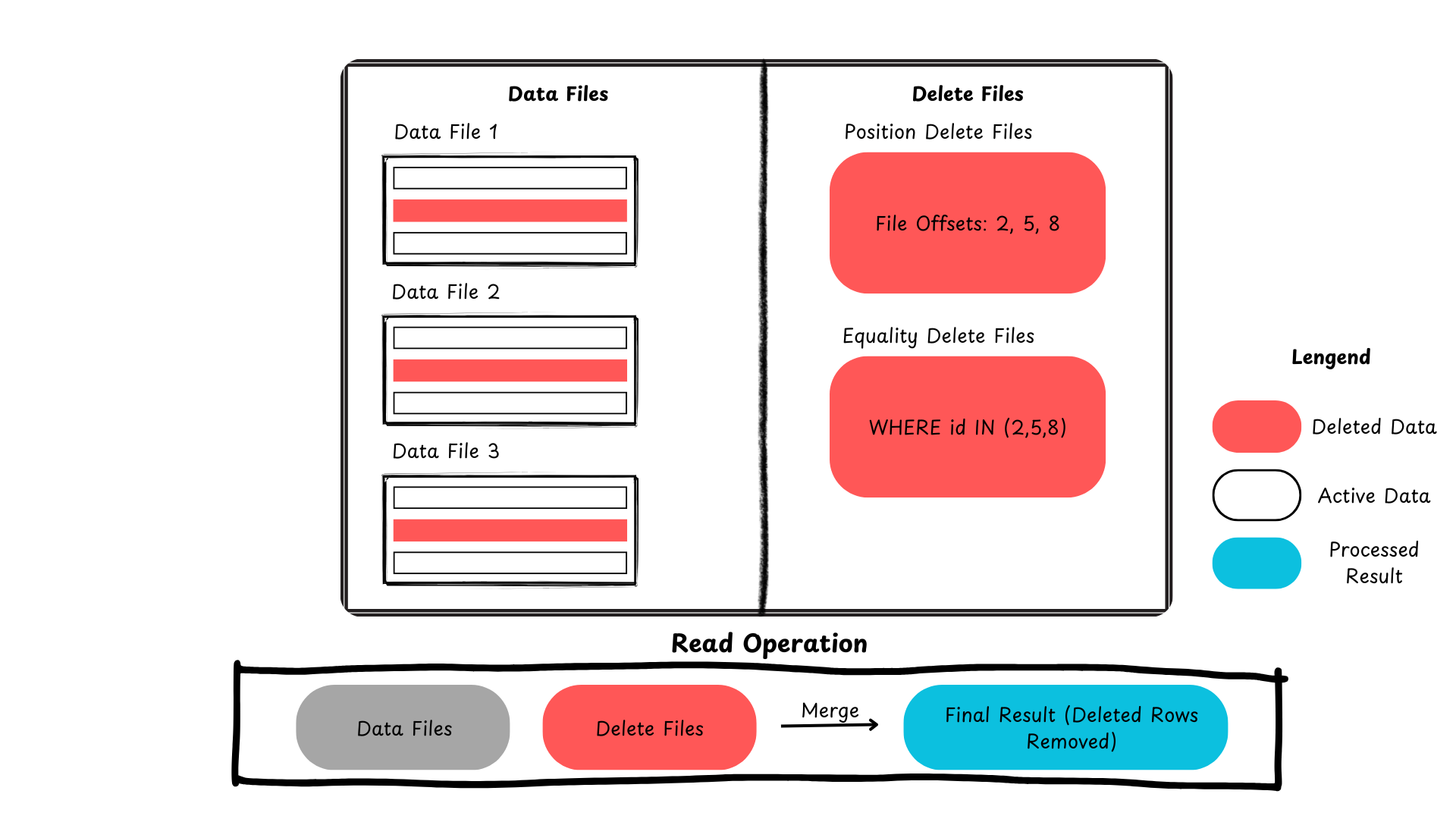
الشكل 2: عملية حذف السجلات في Apache Iceberg (الصورة أنشأها المؤلف)
5. عمليات الجدول المتقدمة
يدعم Iceberg عمليات جدولة متقدمة مثل:
- إنشاء/إدارة لقطات الجدول: هذا يمنحك القدرة على التحكم في الإصدارات بشكل قوي.
- تخطيط وتنفيذ استعلامات سريعة مع بيانات وصفية محسنة للغاية
- أدوات مدمجة لصيانة الجدول، مثل الدمج وتنظيف الملفات اليتيمة
تم تصميم Iceberg للعمل مع جميع تخزين السحابة الرئيسية، مثل AWS S3، GCS، وAzure Blob Storage. كما يتكامل Iceberg بسهولة مع محركات معالجة البيانات مثل Spark، Presto، Trino، وHive.
أفكار نهائية
تسمح هذه الميزات المميزة للشركات ببناء بحيرات بيانات حديثة ومرنة وقابلة للتوسع وفعالة، والتي يمكنها السفر عبر الزمن، والتعامل بسهولة مع تغييرات المخطط، ودعم معاملات ACID، وتطور التقسيم.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes