













اختار الكاتب صندوق البرمجيات الحرة والمفتوحة المصدر ليتلقى تبرعًا كجزء من برنامج الكتابة من أجل التبرعات.
مقدمة
فلاسك هو إطار عمل خفيف للويب بلغة Python يوفر أدوات وميزات مفيدة لإنشاء تطبيقات ويب باستخدام لغة Python. SQLAlchemy هو مجموعة أدوات SQL توفر وصولًا فعّالًا وذو أداء عالٍ إلى قواعد البيانات العلاقية. يوفر طرقًا للتفاعل مع عدة محركات قواعد بيانات مثل SQLite و MySQL و PostgreSQL. يمنحك الوصول إلى وظائف SQL في قاعدة البيانات. ويمنحك أيضًا محول بيانات موضوعية (ORM)، الذي يسمح لك بإجراء الاستعلامات ومعالجة البيانات باستخدام كائنات Python بسيطة وطرق. Flask-SQLAlchemy هو امتداد Flask الذي يجعل استخدام SQLAlchemy مع Flask أسهل، حيث يوفر لك أدوات وطرقًا للتفاعل مع قاعدة البيانات في تطبيقات Flask الخاصة بك من خلال SQLAlchemy.
في هذا البرنامج التعليمي، ستستخدم Flask و Flask-SQLAlchemy لإنشاء نظام إدارة الموظفين مع قاعدة بيانات تحتوي على جدول للموظفين. كل موظف سيمتلك معرفًا فريدًا، واسمًا أولاً، واسمًا أخيرًا، وبريدًا إلكترونيًا فريدًا، وقيمة صحيحة لعمره، وتاريخًا ليوم انضمامه إلى الشركة، وقيمة بوليانية لتحديد ما إذا كان الموظف نشطًا حاليًا أو خارج العمل.
ستستخدم واجهة السطر لـ Flask للاستعلام عن جدول، والحصول على سجلات الجدول استنادًا إلى قيمة العمود (على سبيل المثال، البريد الإلكتروني). ستسترد سجلات الموظفين بشروط معينة، مثل الحصول فقط على الموظفين النشطين أو الحصول على قائمة بالموظفين الخارجين عن العمل. سترتب النتائج حسب قيمة العمود، وتحسب وتحدد نتائج الاستعلام. وأخيرًا، ستستخدم ترقيم الصفحات لعرض عدد معين من الموظفين في كل صفحة في تطبيق ويب.
المتطلبات المسبقة
-
بيئة برمجة Python 3 محلية. اتبع البرنامج التعليمي لتوزيعتك في سلسلة كيفية تثبيت وإعداد بيئة برمجة محلية لـ Python 3. في هذا البرنامج التعليمي، سنطلق على دليل مشروعنا اسم
flask_app. -
فهم مفاهيم Flask الأساسية، مثل المسارات، وظائف العرض، والقوالب. إذا لم تكن ملمًا بـ Flask، تحقق من كيفية إنشاء تطبيق ويب أولي باستخدام Flask و Python و كيفية استخدام القوالب في تطبيق Flask.
-
فهم مفاهيم HTML الأساسية. يمكنك مراجعة سلسلة دروسنا كيفية بناء موقع ويب باستخدام HTML للمعرفة الأساسية.
-
فهم أساسيات مفاهيم Flask-SQLAlchemy، مثل إعداد قاعدة بيانات، وإنشاء نماذج قاعدة البيانات، وإدراج البيانات في قاعدة البيانات. راجع كيفية استخدام Flask-SQLAlchemy للتفاعل مع قواعد البيانات في تطبيق Flask للمعرفة الأساسية.
الخطوة 1 — إعداد قاعدة البيانات والنموذج
في هذه الخطوة، ستقوم بتثبيت الحزم اللازمة، وإعداد تطبيق Flask الخاص بك، وقاعدة بيانات Flask-SQLAlchemy، والنموذج الخاص بالموظفين الذي يمثل جدول الموظفين حيث ستقوم بتخزين بيانات الموظفين الخاصة بك. ستقوم بإدراج عدد قليل من الموظفين في جدول الموظفين، وإضافة مسار وصفحة حيث يتم عرض جميع الموظفين على صفحة الفهرس لتطبيقك.
أولاً، مع تنشيط بيئتك الظاهرية، قم بتثبيت Flask و Flask-SQLAlchemy:
عندما يكتمل التثبيت، ستتلقى إخراجًا يحتوي على السطر التالي في النهاية:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
مع التطبيقات المطلوبة المثبتة، قم بفتح ملف جديد يسمى app.py في دليل flask_app الخاص بك. سيحتوي هذا الملف على الشيفرة لإعداد قاعدة البيانات ومسارات Flask الخاصة بك:
أضف الشيفرة التالية إلى app.py. ستقوم هذه الشيفرة بإعداد قاعدة بيانات SQLite ونموذج قاعدة بيانات للموظف يمثل جدول employee الذي ستستخدمه لتخزين بيانات موظفيك:
احفظ وأغلق الملف.
هنا، تقوم بتوريد موديول os، الذي يمنحك الوصول إلى واجهات نظام التشغيل المتنوعة. ستستخدمه لإنشاء مسار ملف لقاعدة بياناتك database.db.
من حزمة flask، قم بتوريد المساعدين الذين تحتاجهم لتطبيقك: فئة Flask لإنشاء مثيل تطبيق Flask، render_template() لعرض القوالب، كائن request لمعالجة الطلبات، url_for() لإنشاء عناوين URL، ودالة redirect() لتوجيه المستخدمين. لمزيد من المعلومات حول المسارات والقوالب، انظر كيفية استخدام القوالب في تطبيق Flask.
ثم، قم بتوريد فئة SQLAlchemy من امتداد Flask-SQLAlchemy، الذي يمنحك الوصول إلى جميع الوظائف والفئات من SQLAlchemy، بالإضافة إلى المساعدين والوظائف التي تدمج Flask مع SQLAlchemy. ستستخدمه لإنشاء كائن قاعدة بيانات يتصل بتطبيق Flask الخاص بك.
لبناء مسار لملف قاعدة البيانات الخاص بك، يجب عليك تعريف دليل أساسي كدليل حالي. تستخدم دالة os.path.abspath() للحصول على المسار المطلق لدليل ملف الحالي. المتغير الخاص __file__ يحتوي على مسار ملف app.py الحالي. تقوم بتخزين المسار المطلق للدليل الأساسي في متغير يسمى basedir.
ثم تنشئ مثيلًا لتطبيق Flask يُسمى app، الذي تستخدمه لتكوين مفتاحين لتكوين Flask-SQLAlchemy:
-
SQLALCHEMY_DATABASE_URI: هو رابط URI لقاعدة البيانات التي ترغب في إنشاء اتصال بها. في هذه الحالة، يتبع الرابط الشكلsqlite:///المسار/إلى/قاعدة/البيانات.db. تستخدم دالةos.path.join()للانضمام بذكاء إلى الدليل الأساسي الذي قمت ببنائه وتخزينه في المتغيرbasedirمع اسم ملفdatabase.db. سيتم الاتصال بملف قاعدة بياناتdatabase.dbفي دليلflask_appالخاص بك. سيتم إنشاء الملف بمجرد بدء تشغيل قاعدة البيانات. -
SQLALCHEMY_TRACK_MODIFICATIONS: تكوين لتمكين أو تعطيل تتبع التعديلات على الكائنات. يتم تعيينه علىFalseلتعطيل التتبع، مما يستخدم أقل كمية من الذاكرة. لمزيد من المعلومات، انظر صفحة التكوين في توثيق Flask-SQLAlchemy.
بعد تكوين SQLAlchemy عن طريق تحديد عنوان URI لقاعدة البيانات وتعطيل التتبع، يتم إنشاء كائن قاعدة بيانات باستخدام فئة SQLAlchemy، وتمرير نموذج التطبيق لتوصيل تطبيق Flask الخاص بك بـ SQLAlchemy. يتم تخزين كائن قاعدة البيانات في متغير يُسمى db، والذي ستستخدمه للتفاعل مع قاعدة البيانات الخاصة بك.
بعد إعداد مثيل التطبيق وكائن قاعدة البيانات، يتمتع بتركيبك من الفئة db.Model لإنشاء نموذج قاعدة بيانات يُسمى Employee. يمثل هذا النموذج الجدول employee، ويحتوي على الأعمدة التالية:
id: معرف الموظف، وهو مفتاح أساسي صحيح.firstname: اسم الموظف الأول، سلسلة نصية بحد أقصى 100 حرف. تُعنىnullable=Falseبأن هذه العمود يجب ألا يكون فارغاً.lastname: اسم العائلة للموظف، سلسلة نصية بحد أقصى 100 حرف. تُعنىnullable=Falseبأن هذا العمود يجب ألا يكون فارغاً.email: بريد الموظف الإلكتروني، سلسلة نصية بحد أقصى 100 حرف.unique=Trueتُعنى بأن كل بريد إلكتروني يجب أن يكون فريداً.nullable=Falseتُعنى بأن قيمته لا يجب أن تكون فارغة.age: عمر الموظف، قيمة عددية صحيحة.hire_date: تاريخ تعيين الموظف. تقوم بتعيينdb.Dateكنوع للعمود لتعلن عنه كعمود يحتوي على تواريخ.active: عمود يحمل قيمة منطقية للدلالة على ما إذا كان الموظف نشطًا حاليًا أم خارج المكتب.
الدالة __repr__ الخاصة تسمح لك بإعطاء كل كائن تمثيل نصي لتمييزه لأغراض التصحيح. في هذه الحالة، تستخدم الاسم الأول واسم العائلة للموظف لتمثيل كل كائن موظف.
الآن بعد أن قمت بتعيين اتصال قاعدة البيانات ونموذج الموظف، ستقوم بكتابة برنامج Python لإنشاء قاعدة بياناتك وجدول employee وملء الجدول ببعض بيانات الموظفين.
افتح ملفًا جديدًا يسمى init_db.py في دليلك flask_app:
أضف الكود التالي لحذف جداول قاعدة البيانات الحالية للبدء من قاعدة بيانات نظيفة، وإنشاء جدول employee، وإدراج تسعة موظفين فيه:
هنا، تقوم باستيراد فئة date() من وحدة datetime لاستخدامها لتحديد تواريخ تعيين الموظفين.
تقوم باستيراد كائن قاعدة البيانات ونموذج Employee. تقوم بالاتصال بوظيفة db.drop_all() لحذف جميع الجداول الحالية لتجنب فرصة وجود جدول employee ممتلئ بالفعل في قاعدة البيانات، مما قد يسبب مشاكل. يقوم هذا بحذف جميع بيانات قاعدة البيانات كلما قمت بتنفيذ برنامج init_db.py. لمزيد من المعلومات حول إنشاء وتعديل وحذف جداول قاعدة البيانات، انظر كيفية استخدام Flask-SQLAlchemy للتفاعل مع قواعد البيانات في تطبيق Flask.
ثم تقوم بإنشاء عدة مثيلات من نموذج Employee، والتي تمثل الموظفين الذين ستقوم بالاستعلام عنهم في هذا البرنامج التعليمي، وتضيفهم إلى جلسة قاعدة البيانات باستخدام الدالة db.session.add_all(). وأخيرًا، تقوم بتأكيد العملية وتطبيق التغييرات على قاعدة البيانات باستخدام db.session.commit().
احفظ وأغلق الملف.
قم بتنفيذ برنامج init_db.py:
للتحقق من البيانات التي أضفتها إلى قاعدة البيانات الخاصة بك، تأكد من تفعيل البيئة الافتراضية الخاصة بك، وافتح محرر Flask للاستعلام عن جميع الموظفين وعرض بياناتهم:
قم بتشغيل الكود التالي للاستعلام عن جميع الموظفين وعرض بياناتهم:
تستخدم الطريقة all() للوصول إلى جميع الموظفين. تكرر النتائج، وعرض معلومات الموظف. بالنسبة للعمود active، تستخدم عبارة شرطية لعرض الحالة الحالية للموظف، إما 'Active' أو 'Out of Office'.
ستتلقى الناتج التالي:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
يمكنك رؤية أن جميع الموظفين الذين قمت بإضافتهم إلى قاعدة البيانات يتم عرضهم بشكل صحيح.
اخرج من محرر Flask:
بعد ذلك، ستقوم بإنشاء مسار Flask لعرض الموظفين. افتح app.py للتحرير:
أضف المسار التالي في نهاية الملف:
احفظ وأغلق الملف.
يستعلم عن جميع الموظفين، ويقوم بتقديم قالب index.html، ويمرر له الموظفين الذين استرجعتهم.
إنشاء دليل للقوالب وقالب أساسي:قالب القاعدة:
أضف ما يلي إلى base.html:
احفظ وأغلق الملف.
هنا، تستخدم كتلة العنوان وتضيف بعض التنسيق بـ CSS. تضيف شريطًا تنقليًا يحتوي على عنصرين، أحد لصفحة الفهرس، والآخر لصفحة حول غير نشطة. سيتم إعادة استخدام هذا الشريط التنقل في جميع أنحاء التطبيق في القوالب التي ترث من هذا القالب الأساسي. سيتم استبدال كتلة المحتوى بمحتوى كل صفحة. لمزيد من المعلومات حول القوالب، تحقق من كيفية استخدام القوالب في تطبيق Flask.
بعد ذلك، افتح قالب index.html الجديد الذي قمت بتقديمه في app.py:
أضف الكود التالي إلى الملف:
هنا، تكرر عبر الموظفين وتعرض معلومات كل موظف. إذا كان الموظف نشطًا، فستضيف علامة (نشط)، وإلا فستعرض علامة (خارج المكتب).
احفظ وأغلق الملف.
أثناء وجودك في دليل flask_app وتفعيل بيئتك الظاهرية، قم بإخبار Flask بالتطبيق (app.py في هذه الحالة) باستخدام متغير البيئة FLASK_APP. ثم قم بتعيين متغير البيئة FLASK_ENV إلى development لتشغيل التطبيق في وضع التطوير والحصول على الوصول إلى مصحح الأخطاء. لمزيد من المعلومات حول مصحح الأخطاء في Flask، انظر كيفية التعامل مع الأخطاء في تطبيق Flask. استخدم الأوامر التالية للقيام بذلك:
بعد ذلك، قم بتشغيل التطبيق:
بمجرد تشغيل خادم التطوير، افتح الرابط التالي باستخدام متصفحك:
http://127.0.0.1:5000/
سترى الموظفين الذين تمت إضافتهم إلى قاعدة البيانات في صفحة مماثلة للصفحة التالية:
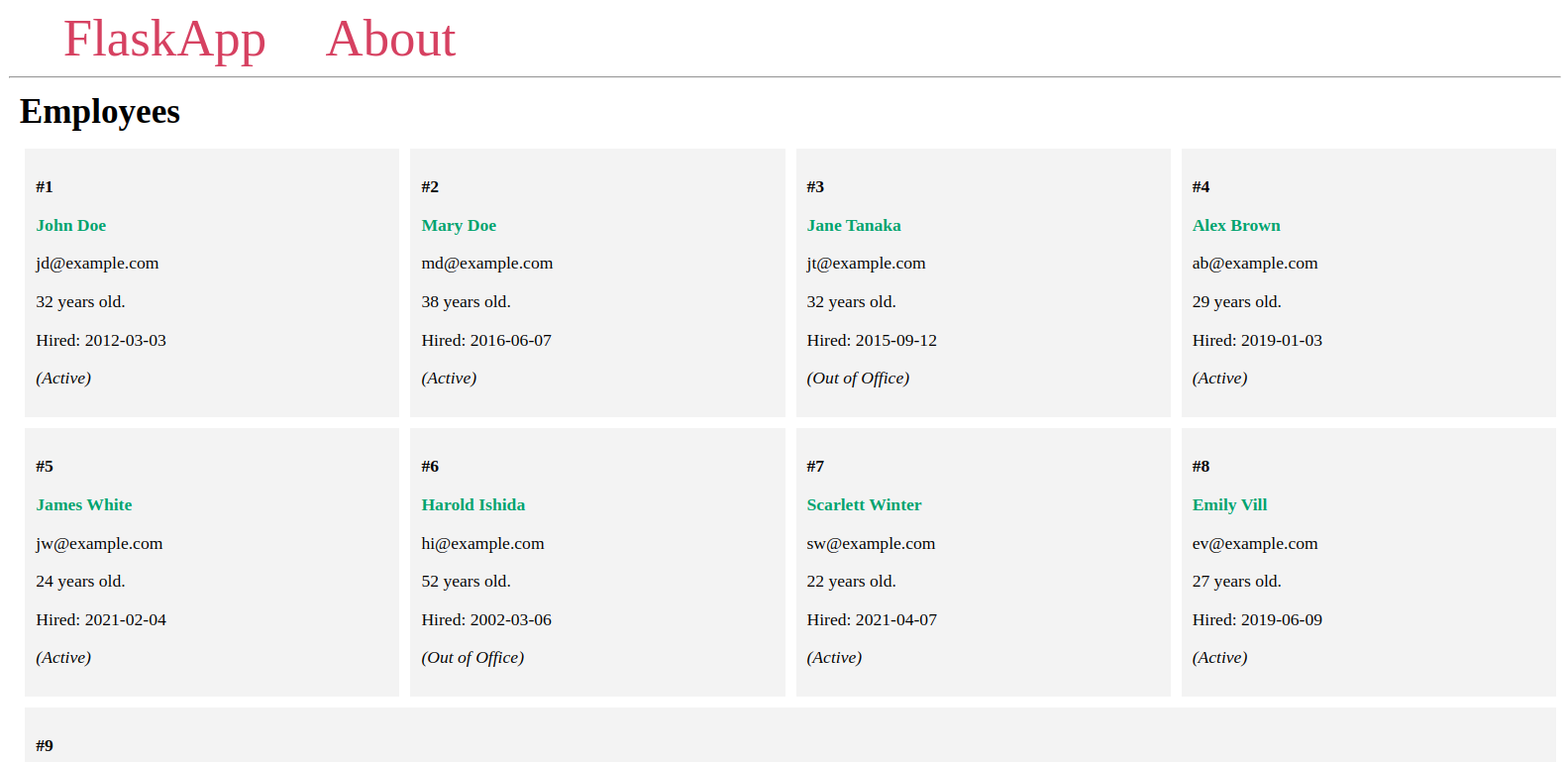
اترك الخادم يعمل، افتح نافذة أوامر جديدة، وتابع إلى الخطوة التالية.
لقد عرضت الموظفين الذين لديك في قاعدة البيانات على الصفحة الرئيسية. في الخطوة التالية، ستستخدم محطة Flask للاستعلام عن الموظفين باستخدام طرق وشروط مختلفة.
الخطوة 2 — الاستعلام عن السجلات
في هذه الخطوة، ستستخدم محطة Flask للاستعلام عن السجلات، وتصفية النتائج واستردادها باستخدام طرق وشروط متعددة.
بعد تنشيط بيئة البرمجة الخاصة بك، قم بتعيين متغيرات FLASK_APP و FLASK_ENV، وافتح محطة Flask:
استيراد كائن db ونموذج Employee:
استرجاع جميع السجلات
كما رأيت في الخطوة السابقة، يمكنك استخدام الطريقة all() على السمة query للحصول على جميع السجلات في جدول:
سيكون الإخراج قائمة من الكائنات تمثل جميع الموظفين:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
استرجاع السجل الأول
بالمثل، يمكنك استخدام الطريقة first() للحصول على السجل الأول:
سيكون الإخراج كائن يحمل بيانات أول موظف:
Output<Employee John Doe>
استرجاع سجل بواسطة معرف
في معظم جداول قواعد البيانات، يتم تحديد السجلات بمعرف فريد. Flask-SQLAlchemy يسمح لك بجلب سجل باستخدام معرفه باستخدام الطريقة get():
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
استرجاع سجل أو سجلات متعددة بواسطة قيمة العمود
للحصول على سجل باستخدام قيمة أحد أعمدته، استخدم الطريقة filter_by(). على سبيل المثال، للحصول على سجل باستخدام قيمة الهوية الخاصة به، بشكل مشابه لطريقة get():
Output<Employee John Doe>
تستخدم first() لأن filter_by() قد تُرجع نتائج متعددة.
ملاحظة: للحصول على سجل بواسطة الهوية، استخدام الطريقة get() هو أفضل.
على سبيل المثال آخر، يمكنك الحصول على موظف باستخدام عمره:
Output<Employee Harold Ishida>
لمثال آخر حيث تحتوي نتيجة الاستعلام على أكثر من سجل مطابق، استخدم العمود firstname والاسم الأول Mary، الذي هو اسم مشترك بين موظفين:
Output[<Employee Mary Doe>, <Employee Mary Park>]
هنا، تستخدم all() للحصول على القائمة الكاملة. يمكنك أيضًا استخدام first() للحصول على النتيجة الأولى فقط:
Output<Employee Mary Doe>
لقد جلبت السجلات من خلال قيم الأعمدة. في الخطوة التالية، ستستعلم الجدول الخاص بك باستخدام شروط منطقية.
الخطوة 3 — تصفية السجلات باستخدام شروط منطقية
في تطبيقات الويب المعقدة والمتكاملة، غالبًا ما تحتاج إلى استعلام السجلات من قاعدة البيانات باستخدام شروط معقدة، مثل استرجاع الموظفين استنادًا إلى مزيج من الشروط التي تأخذ في الاعتبار موقعهم، وتوفرهم، ودورهم، ومسؤولياتهم. في هذه الخطوة، ستحصل على ممارسة باستخدام المشغلات الشرطية. ستستخدم طريقة filter() على السمة query لتصفية نتائج الاستعلام باستخدام شروط منطقية مع مشغلات مختلفة. على سبيل المثال، يمكنك استخدام المشغلات المنطقية لاسترجاع قائمة بالموظفين الذين هم حاليًا خارج المكتب، أو الموظفين المستحقين للترقية، وربما توفير تقويم لأوقات إجازة الموظفين، وما إلى ذلك.
يساوي
أبسط مشغل منطقي يمكنك استخدامه هو مشغل المساواة ==، الذي يتصرف بطريقة مماثلة لـ filter_by(). على سبيل المثال، للحصول على جميع السجلات حيث يكون قيمة العمود firstname هي Mary، يمكنك استخدام طريقة filter() مثل هذا:
هنا تستخدم بنية النموذج.العمود == القيمة كوسيطة لطريقة filter(). طريقة filter_by() هي اختصار لهذه الصيغة.
النتيجة هي نفس النتيجة التي تم الحصول عليها باستخدام طريقة filter_by() بنفس الشرط:
Output[<Employee Mary Doe>, <Employee Mary Park>]
مثل filter_by()، يمكنك أيضًا استخدام طريقة first() للحصول على النتيجة الأولى:
Output<Employee Mary Doe>
لا تساوي
تسمح طريقة filter() لك باستخدام مشغل Python != للحصول على السجلات. على سبيل المثال، للحصول على قائمة بالموظفين الذين غير متواجدين في المكتب، يمكنك استخدام النهج التالي:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
هنا تستخدم شرط Employee.active != True لتصفية النتائج.
أقل من
يمكنك استخدام المشغل < للحصول على سجل حيث قيمة العمود المعطى أقل من القيمة المعطاة. على سبيل المثال، للحصول على قائمة بالموظفين دون سن 32:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
استخدم المشغل <= للسجلات التي تكون أقل من أو تساوي القيمة المعطاة. على سبيل المثال، لتضمين الموظفين البالغين 32 سنة في الاستعلام السابق:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
أكثر من
بالمثل، يحصل المشغل > على سجل حيث قيمة العمود المعطى أكبر من القيمة المعطاة. على سبيل المثال، للحصول على الموظفين الذين تتجاوز أعمارهم 32 سنة:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
والمشغل >= مخصص للسجلات التي تكون أكبر من أو تساوي القيمة المعطاة. على سبيل المثال، يمكنك مرة أخرى تضمين الموظفين البالغين 32 سنة في الاستعلام السابق:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
في
SQLAlchemy توفر أيضًا طريقة للحصول على السجلات التي يتطابق فيها قيمة العمود مع قيمة من قائمة معينة باستخدام الطريقة in_() على العمود مثل هذا:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
هنا، تستخدم شرطًا بالصيغة Model.column.in_(iterable)، حيث أن iterable يمكن أن يكون أي نوع من الكائنات التي يمكنك تكرارها. على سبيل المثال، يمكنك استخدام دالة range() في Python للحصول على الموظفين من نطاق عمر معين. الاستعلام التالي يحصل على جميع الموظفين الذين في عقدهم الثالث.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Not In
بشكل مماثل لطريقة in_()، يمكنك استخدام الطريقة not_in() للحصول على السجلات التي لا تكون قيمة العمود فيها ضمن مجموعة معينة:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
هنا، تحصل على جميع الموظفين ما عدا تلك التي لها اسم أول في القائمة names.
And
يمكنك دمج عدة شروط معًا باستخدام دالة db.and_()، التي تعمل مثل عامل and في Python.
على سبيل المثال، لنفترض أنك ترغب في الحصول على جميع الموظفين البالغين من العمر 32 عامًا والذين يعملون حاليًا. أولاً، يمكنك التحقق ممن هم في السن 32 باستخدام طريقة filter_by() (يمكنك أيضًا استخدام filter() إذا كنت ترغب):
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
هنا، ترى أن جون وجين هم الموظفين البالغين من العمر 32 عامًا. جون نشط، وجين خارج المكتب.
للحصول على الموظفين البالغين من العمر 32 و نشطين، ستستخدم شرطين مع طريقة filter():
Employee.age == 32Employee.active == True
لدمج هاتين الشروطين معًا، استخدم وظيفة db.and_() كالتالي:
Output[<Employee John Doe>]
هنا، تستخدم الصيغة filter(db.and_(condition1, condition2)).
باستخدام all() على الاستعلام، سيتم إرجاع قائمة بجميع السجلات التي تطابق الشرطين. يمكنك استخدام طريقة first() للحصول على النتيجة الأولى:
Output<Employee John Doe>
لمثال أكثر تعقيدًا، يمكنك استخدام db.and_() مع وظيفة date() للحصول على الموظفين الذين تم توظيفهم في نطاق زمني محدد. في هذا المثال، تحصل على جميع الموظفين الذين تم توظيفهم في عام 2019:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
هنا تقوم بإستيراد وظيفة date()، وتصفي النتائج باستخدام وظيفة db.and_() لدمج الشرطين التاليين:
Employee.hire_date >= date(year=2019, month=1, day=1): هذا يكونTrueللموظفين الذين تم توظيفهم في الأول من يناير 2019 أو بعد ذلك.Employee.hire_date < date(year=2020, month=1, day=1): هذا صحيح للموظفين الذين تم توظيفهم قبل الأول من يناير 2020.
من خلال جمع الشرطين يتم الحصول على الموظفين الذين تم توظيفهم من اليوم الأول من عام 2019 وقبل اليوم الأول من عام 2020.
أو
بشكل مشابه لـ db.and_()، تقوم وظيفة db.or_() بجمع شرطين، وتتصرف مثل مشغل or في Python. فهي تحصل على جميع السجلات التي تستوفي أحد الشروطين. على سبيل المثال، للحصول على الموظفين الذين تبلغ أعمارهم 32 أو 52، يمكنك جمع شرطين باستخدام وظيفة db.or_() على النحو التالي:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
يمكنك أيضًا استخدام الأساليب startswith() و endswith() على قيم السلسلة في الشروط التي تمررها إلى الطريقة filter(). على سبيل المثال، للحصول على جميع الموظفين الذين يبدأ اسمهم بالسلسلة 'M' والذين ينتهي اسمهم بالسلسلة 'e':
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
هنا يتم دمج الشرطين التاليين:
Employee.firstname.startswith('M'): يطابق الموظفين الذين لديهم اسم يبدأ بـ'M'.Employee.lastname.endswith('e'): يطابق الموظفين الذين لديهم اسم ينتهي بـ'e'.
يمكنك الآن تصفية نتائج الاستعلام باستخدام الشروط المنطقية في تطبيقات Flask-SQLAlchemy الخاصة بك. فيما يلي، ستقوم بترتيب وتحديد النتائج وعد عددها من قاعدة البيانات.
الخطوة ٤ — ترتيب، تحديد الحدود، وعد النتائج
في تطبيقات الويب، غالبًا ما تحتاج إلى ترتيب السجلات الخاصة بك عند عرضها. على سبيل المثال، قد تكون لديك صفحة لعرض أحدث التوظيفات في كل قسم لإعلام بقية الفريق عن التوظيفات الجديدة، أو يمكنك ترتيب الموظفين عن طريق عرض أقدم التوظيفات أولاً للاعتراف بالموظفين ذوي فترة خدمة طويلة. كما ستحتاج أيضًا إلى تحديد حدود النتائج في حالات معينة، مثل عرض آخر ثلاث توظيفات فقط على شريط جانبي صغير. وغالبًا ما تحتاج أيضًا إلى عد النتائج لاستعراض عدد الموظفين النشطين حاليًا. في هذه الخطوة، ستتعلم كيفية ترتيب وتحديد الحدود وعد النتائج.
ترتيب النتائج
لترتيب النتائج باستخدام قيمة عمود معين، استخدم الطريقة order_by(). على سبيل المثال، لترتيب النتائج حسب اسم الموظف الأول:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
كما يظهر الإخراج، تم ترتيب النتائج ترتيبًا أبجديًا حسب اسم الموظف الأول.
يمكنك أيضًا الترتيب حسب أعمدة أخرى. على سبيل المثال، يمكنك استخدام اسم العائلة لترتيب الموظفين:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
يمكنك أيضًا ترتيب الموظفين حسب تاريخ توظيفهم:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
كما يوضح الناتج، يُرتب النتائج من أقدم توظيف إلى أحدث توظيف. لعكس الترتيب وجعله تنازلياً من آخر توظيف إلى أول توظيف، استخدم الطريقة desc() كما يلي:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
يمكنك أيضًا دمج الطريقة order_by() مع الطريقة filter() لترتيب النتائج المُنقاة. يُظهر المثال التالي جميع الموظفين الذين تم توظيفهم في عام 2021 ويُرتبهم حسب العمر:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
هنا، يُستخدم الدالة db.and_() مع شرطين: Employee.hire_date >= date(year=2021, month=1, day=1) للموظفين الذين تم توظيفهم في اليوم الأول من عام 2021 أو لاحقًا، و Employee.hire_date < date(year=2022, month=1, day=1) للموظفين الذين تم توظيفهم قبل اليوم الأول من عام 2022. بعد ذلك، يتم استخدام الطريقة order_by() لترتيب الموظفين الناتجين حسب أعمارهم.
تقييد النتائج
في معظم الحالات الواقعية، عند استعلام جدول قاعدة البيانات، قد تحصل على ملايين النتائج المُطابقة، ومن الضروري في بعض الأحيان تقييد النتائج إلى عدد معين. لتقييد النتائج في Flask-SQLAlchemy، يمكنك استخدام الطريقة limit(). يقوم المثال التالي باستعلام جدول employee ويعيد فقط أول ثلاث نتائج مُطابقة:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
يمكنك استخدام limit() مع طرق أخرى، مثل filter و order_by. على سبيل المثال، يمكنك الحصول على آخر موظفين اثنين تم توظيفهم في عام 2021 باستخدام الطريقة limit() على النحو التالي:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
هنا، تستخدم نفس الاستعلام في القسم السابق مع استدعاء طريقة limit(2) إضافية.
عد النتائج
لحساب عدد نتائج الاستعلام، يمكنك استخدام الطريقة count(). على سبيل المثال، للحصول على عدد الموظفين الموجودين حاليًا في قاعدة البيانات:
Output9
يمكنك دمج طريقة count() مع طرق الاستعلام الأخرى مشابهة لـ limit(). على سبيل المثال، للحصول على عدد الموظفين الذين تم توظيفهم في عام 2021:
Output3
هنا تستخدم نفس الاستعلام الذي استخدمته سابقًا للحصول على جميع الموظفين الذين تم توظيفهم في عام 2021. وتستخدم الطريقة count() لاسترجاع عدد الإدخالات، والذي هو 3.
لقد قمت بترتيب وتقييد وعد النتائج للاستعلامات في Flask-SQLAlchemy. فيما يلي، ستتعلم كيفية تقسيم نتائج الاستعلام إلى عدة صفحات وكيفية إنشاء نظام ترقيم الصفحات في تطبيقات Flask الخاصة بك.
الخطوة 5 — عرض قوائم التسجيل الطويلة على عدة صفحات
في هذه الخطوة، ستقوم بتعديل المسار الرئيسي لجعل صفحة الفهرس تعرض الموظفين على عدة صفحات لتسهيل تصفح قائمة الموظفين.
أولاً، ستستخدم واجهة Flask لرؤية عرض لكيفية استخدام ميزة الترقيم في Flask-SQLAlchemy. افتح واجهة Flask إذا لم تفعل بالفعل:
لنفترض أنك تريد تقسيم سجلات الموظفين في جدولك إلى صفحات متعددة، مع عنصرين في كل صفحة. يمكنك القيام بذلك باستخدام طريقة الاستعلام paginate() كما يلي:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
تستخدم معلمة page لطريقة الاستعلام paginate() لتحديد الصفحة التي تريد الوصول إليها، والتي هي الصفحة الأولى في هذه الحالة. تحدد معلمة per_page عدد العناصر التي يجب أن تحتوي عليها كل صفحة. في هذه الحالة، يتم تعيينها إلى 2 لجعل كل صفحة تحتوي على عنصرين.
المتغير page1 هنا هو كائن الترقيم، الذي يمنحك الوصول إلى السمات والأساليب التي ستستخدمها لإدارة الترقيم.
يمكنك الوصول إلى عناصر الصفحة باستخدام السمة items.
للوصول إلى الصفحة التالية، يمكنك استخدام الطريقة next() لكائن الترقيم كما يلي، النتيجة المُرجعة أيضًا كائن ترقيم:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
يمكنك الحصول على كائن ترقيم للصفحة السابقة باستخدام الطريقة prev(). في المثال التالي، تصل إلى كائن الترقيم للصفحة الرابعة، ثم تصل إلى كائن الترقيم لصفحتها السابقة، التي هي الصفحة 3:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
يمكنك الوصول إلى رقم الصفحة الحالية باستخدام السمة page كما يلي:
Output1
2
للحصول على إجمالي عدد الصفحات، استخدم سمة pages لكائن الترقيم. في المثال التالي، كلاً من page1.pages و page2.pages يعيدان نفس القيمة لأن إجمالي عدد الصفحات هو ثابت:
Output5
5
بالنسبة إلى العدد الإجمالي للعناصر، استخدم سمة total لكائن الترقيم:
Output9
9
هنا، نظرًا لأنك تستعلم عن جميع الموظفين، فإن العدد الإجمالي للعناصر في الترقيم هو 9، لأن هناك تسعة موظفين في قاعدة البيانات.
فيما يلي بعض السمات الأخرى التي تحتوي عليها كائنات الترقيم:
prev_num: رقم الصفحة السابقة.next_num: رقم الصفحة التالية.has_next:Trueإذا كان هناك صفحة تالية.has_prev:Trueإذا كانت هناك صفحة سابقة.per_page: عدد العناصر في كل صفحة.
كما أن لدى كائن الترقيم طريقة iter_pages() يمكنك الاستمرار في الحلق عبرها للوصول إلى أرقام الصفحات. على سبيل المثال، يمكنك طباعة جميع أرقام الصفحات كما يلي:
Output1
2
3
4
5
التالي هو عرض لكيفية الوصول إلى جميع الصفحات وعناصرها باستخدام كائن الترقيم وطريقة iter_pages():
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
هنا، تنشئ كائن ترقيم يبدأ من الصفحة الأولى. تحلق عبر الصفحات باستخدام حلقة for مع طريقة ترقيم iter_pages(). تطبع رقم الصفحة وعناصر الصفحة، وتعيد تعيين كائن pagination إلى كائن الترقيم للصفحة التالية باستخدام الطريقة next().
يمكنك أيضًا استخدام الطرق filter() و order_by() مع الطريقة paginate() لتقسيم نتائج الاستعلام المُصفَّاة والمُرتبة. على سبيل المثال، يمكنك الحصول على الموظفين الذين تزيد أعمارهم عن ثلاثين عامًا وترتيب النتائج حسب العمر وتقسيم النتائج كالتالي:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
الآن بعد أن لديك فهمًا قويًا لكيفية عمل التقسيم في Flask-SQLAlchemy، ستقوم بتحرير صفحة الفهرس في تطبيقك لعرض الموظفين على صفحات متعددة لسهولة التنقل.
انس الطرفية الخاصة بـ Flask:
للوصول إلى صفحات مختلفة، ستستخدم معلمات عنوان URL، المعروفة أيضًا باسم سلاسل الاستعلام لعنوان URL، وهي طريقة لتمرير المعلومات إلى التطبيق عبر عنوان URL. يتم تمرير المعلمات إلى التطبيق في عنوان URL بعد رمز ؟. على سبيل المثال، لتمرير معلمة page بقيم مختلفة، يمكنك استخدام عناوين URL التالية:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
هنا، تمرر العنوان الأول قيمة 1 إلى معلمة عنوان URL page. يمرر العنوان الثاني قيمة 3 إلى نفس المعلمة.
افتح ملف app.py:
عدّل مسار الفهرس ليبدو كما يلي:
هنا، تحصل على قيمة معلمة عنوان URL page باستخدام كائن request.args وطريقته get(). على سبيل المثال /?page=1 سيحصل على القيمة 1 من معلمة عنوان URL page. تمرر 1 كقيمة افتراضية، وتمرر نوع بيثون int كوسيطة للمعلمة type للتأكد من أن القيمة هي عدد صحيح.
ثم تقوم بإنشاء كائن pagination، مرتباً نتائج الاستعلام حسب الاسم الأول. تمرر قيمة معلمة عنوان page إلى طريقة paginate()، وتقسم النتائج إلى عنصرين لكل صفحة عن طريق تمرير القيمة 2 إلى المعلمة per_page.
وأخيرًا، تمرر الكائن pagination الذي قمت بإنشائه إلى قالب index.html المرتجع.
احفظ الملف وأغلقه.
ثم، قم بتعديل قالب index.html لعرض عناصر الترقيم:
قم بتغيير علامة الفقرة div بإضافة عنوان h2 يشير إلى الصفحة الحالية، وقم بتغيير حلقة for لتكرار كائن pagination.items بدلاً من كائن employees الذي لم يعد متاحًا:
احفظ الملف وأغلقه.
إذا لم تقم بذلك بالفعل، قم بتعيين متغيرات البيئة FLASK_APP و FLASK_ENV وتشغيل خادم التطوير:
الآن، انتقل إلى صفحة الفهرس بقيم مختلفة لمعلمة عنوان page:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
سترى صفحات مختلفة تحتوي على عنصرين لكل منها، وعناصر مختلفة على كل صفحة، كما رأيت سابقاً في محطة Flask.
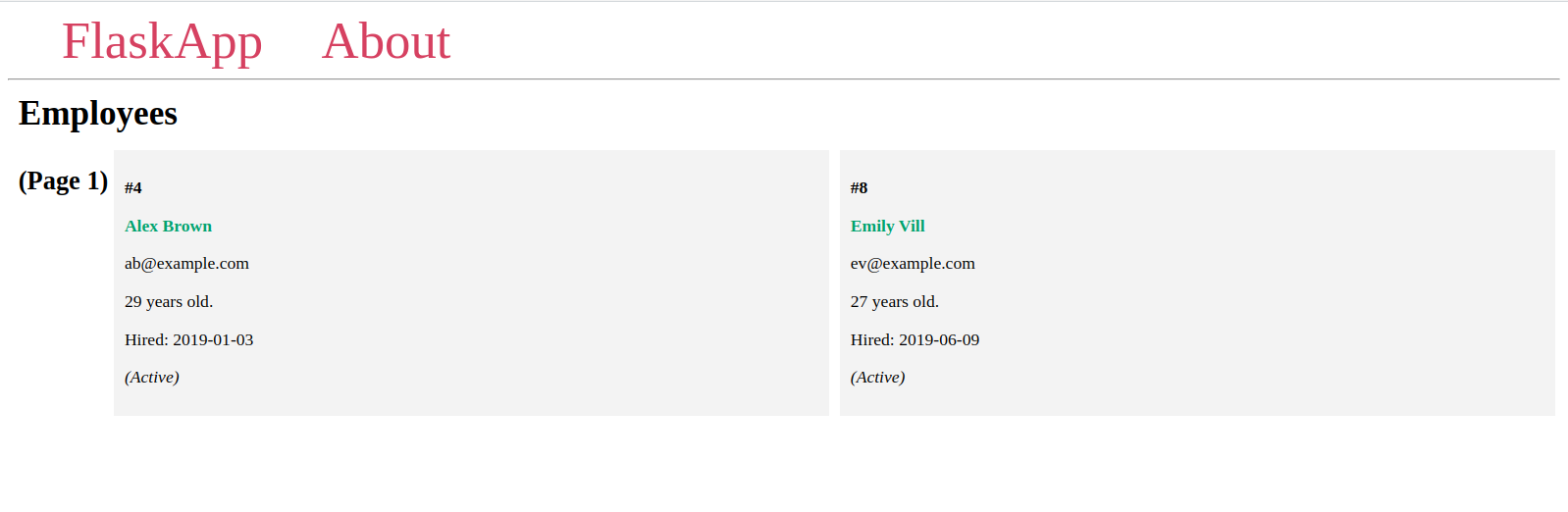
إذا كان رقم الصفحة المعطى غير موجود، ستحصل على خطأ HTTP 404 Not Found، وهذا هو الحال مع آخر عنوان URL في القائمة السابقة.
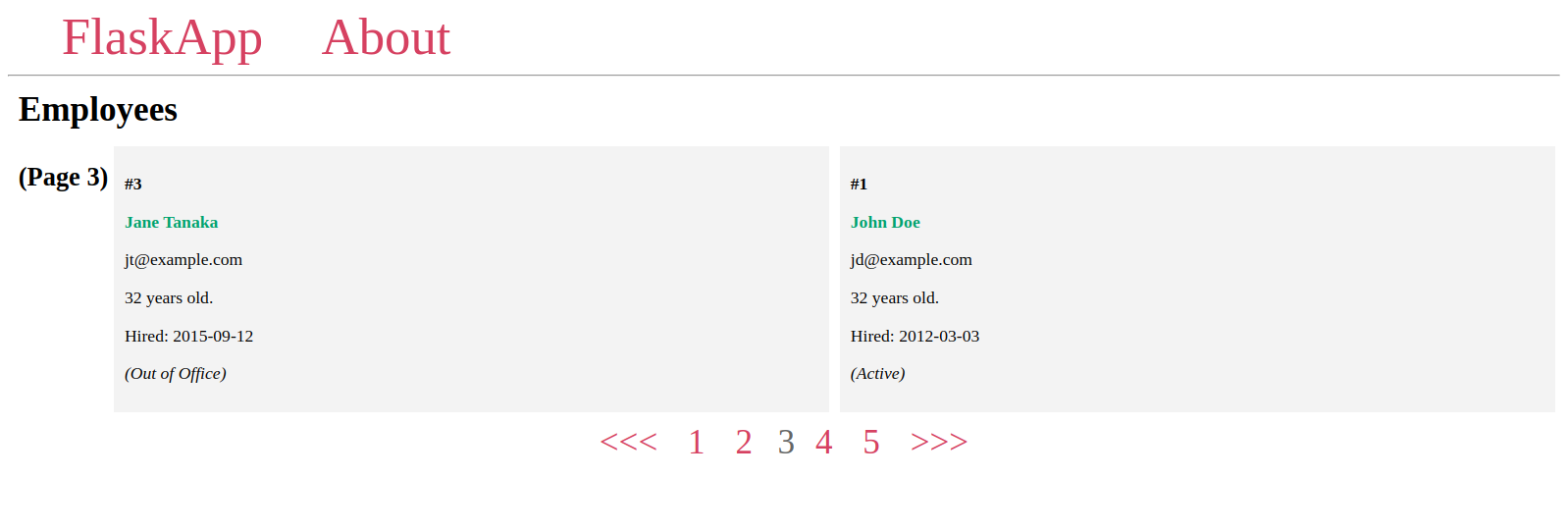
ثم، ستقوم بإنشاء عنصر واجهة مستخدم لترقيم الصفحات للتنقل بين الصفحات، وستستخدم بعض السمات والطرق من كائن الترقيم لعرض جميع أرقام الصفحات، حيث يرتبط كل رقم بصفحته المخصصة، بالإضافة إلى زر <<< للرجوع إذا كانت الصفحة الحالية تمتلك صفحة سابقة، وزر >>> للانتقال إلى الصفحة التالية إذا كانت موجودة.
سيبدو عنصر واجهة مستخدم الترقيم كالتالي:

لإضافته، قم بفتح ملف index.html:
قم بتعديل الملف عن طريق إضافة العنصر div المظلل أدناه إلى داخل عنصر الـ div الخاص بالمحتوى:
احفظ وأغلق الملف.
هنا، ستستخدم الشرط if pagination.has_prev لإضافة رابط <<< للصفحة السابقة إذا لم تكن الصفحة الحالية هي الصفحة الأولى. ستقوم بربطه بالصفحة السابقة باستخدام استدعاء الدالة url_for('index', page=pagination.prev_num)، حيث ستربط بدالة عرض الفهرس، وستمرر قيمة pagination.prev_num كمعلمة URL page.
لعرض روابط إلى جميع أرقام الصفحات المتاحة، ستقوم بتكرار عناصر الطريقة pagination.iter_pages() التي تعيد لك رقم صفحة في كل دورة.
تستخدم شرط if pagination.page != number لمعرفة ما إذا كان رقم الصفحة الحالية ليس نفس الرقم في الحلقة الحالية. إذا كان الشرط صحيحًا، فستقوم بربط الصفحة للسماح للمستخدم بتغيير الصفحة الحالية إلى صفحة أخرى. وإذا كانت الصفحة الحالية هي نفس رقم الحلقة، فستعرض الرقم بدون رابط. هذا يتيح للمستخدمين معرفة رقم الصفحة الحالية في عنصر واجهة التصفح.
أخيرًا، تستخدم شرط pagination.has_next لمعرفة ما إذا كانت الصفحة الحالية تحتوي على صفحة للأمام، في هذه الحالة ستقوم بربطها باستخدام استدعاء url_for('index', page=pagination.next_num) ورابط >>>.
انتقل إلى صفحة الفهرس في متصفحك: http://127.0.0.1:5000/
سترى عنصر واجهة التصفح يعمل بشكل كامل:
هنا، تستخدم >>> للانتقال إلى الصفحة التالية و <<< للصفحة السابقة، لكن يمكنك أيضًا استخدام أي رموز أخرى تفضلها، مثل > و < أو صور في علامات <img>.
لقد قمت بعرض الموظفين على عدة صفحات وتعلمت كيفية التعامل مع الترقيم في Flask-SQLAlchemy. ويمكنك الآن استخدام عنصر واجهة التصفح هذا في تطبيقات Flask الأخرى التي تقوم ببنائها.
الاستنتاج
استخدمت Flask-SQLAlchemy لإنشاء نظام إدارة الموظفين. قمت باستعلام جدول وفرز النتائج استنادًا إلى قيم الأعمدة والشروط المنطقية البسيطة والمعقدة. وقمت بترتيب وعد وتقييد نتائج الاستعلام. وقمت بإنشاء نظام ترقيم الصفحات لعرض عدد معين من السجلات في كل صفحة في تطبيق الويب الخاص بك، والتنقل بين الصفحات.
يمكنك استخدام ما تعلمته في هذا البرنامج التعليمي بالاقتران مع المفاهيم المشروحة في بعض برامج البرمجة النصية الأخرى لـ Flask-SQLAlchemy لإضافة المزيد من الوظائف إلى نظام إدارة الموظفين الخاص بك:
- كيفية استخدام Flask-SQLAlchemy للتفاعل مع قواعد البيانات في تطبيق Flask لتعلم كيفية إضافة، تحرير، أو حذف الموظفين.
- كيفية استخدام العلاقات القاعدية واحد-إلى-كثير مع Flask-SQLAlchemy لتعلم كيفية استخدام العلاقات القاعدية واحد-إلى-كثير لإنشاء جدول الإدارة لربط كل موظف بالإدارة التي ينتمون إليها.
- كيفية استخدام علاقات قاعدة بيانات كثير إلى كثير مع Flask-SQLAlchemy لتعلم كيفية استخدام العلاقات الكثير إلى الكثير لإنشاء جدول
tasksوربطه بجدولemployee، حيث يمتلك كل موظف العديد من المهام وتُعين كل مهمة لعدة موظفين.
إذا كنت ترغب في قراءة المزيد حول Flask، فقم بالتحقق من البرامج التعليمية الأخرى في سلسلة كيفية بناء تطبيقات الويب باستخدام Flask.