













في الجزء الأول، غطينا عدة مواضيع رئيسية. أنصحك بقراءته، حيث يبنى هذا الجزء التالي عليه.
كمراجعة سريعة، في الجزء الأول، نظرنا إلى بياناتنا من منظور واسع وفرقنا بين البيانات الداخلية والخارجية. كما ناقشنا السيناريوهات واتفاقيات البيانات وكيف توفر وسيلة للتفاوض، والتغيير، والتطور لتياراتنا بمرور الوقت. وأخيرًا، غطينا أنواع الأحداث الوقائعية (الحالة) والأحداث التفاضلية. أحداث الوقائعية هي الأفضل للإبلاغ عن الحالة و découplage الأنظمة، بينما تميل أحداث التفاضل إلى الاستخدام أكثر للبيانات الداخلية، مثل في مصادر الأحداث واستخدامات متشابكة بإحكام.
الجداول المعيارية تؤدي إلى تيارات معيارية
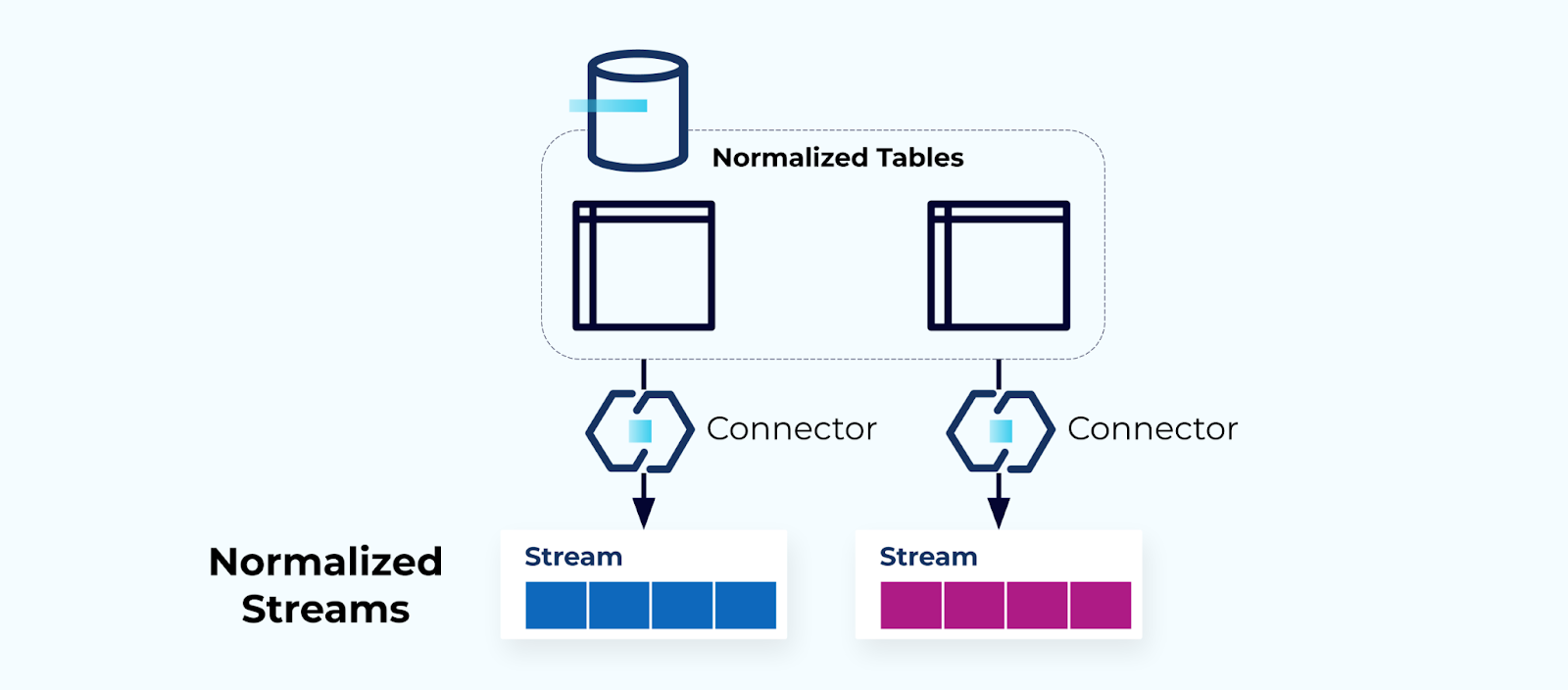
الجداول المعيارية تؤدي إلى تيارات أحداث معيارية. الوصلات (مثل، CDC) تسحب البيانات مباشرة من قاعدة البيانات إلى مجموعة معكوسة من تيارات الأحداث. هذا ليس مثاليًا، حيث إنه يخلق ارتباطًا قويًا بين جداول قاعدة البيانات الداخلية وتيارات الأحداث الخارجية.
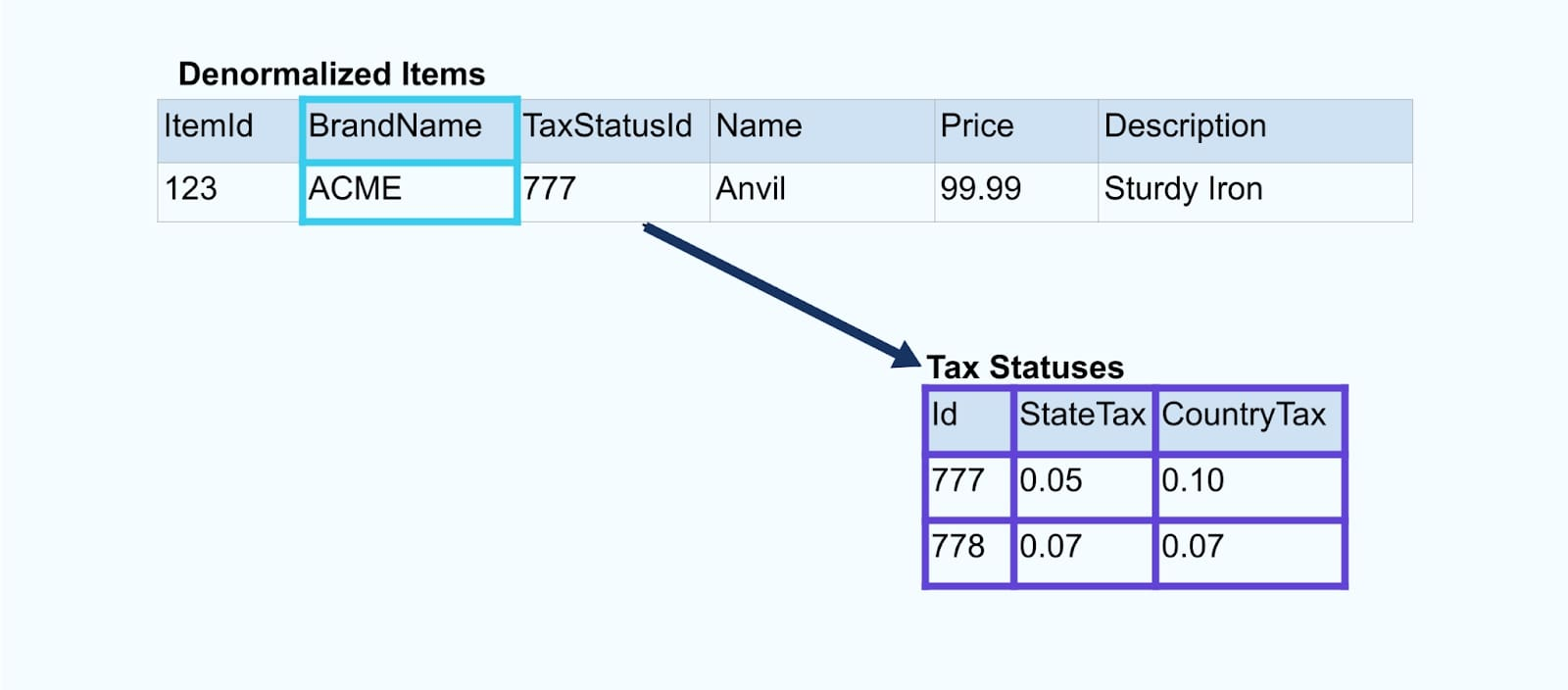
انظر إلى بيانات بسيطة لمتجر إلكتروني المنتج وما يرتبط به من جداول العلامة التجارية و حالة الضرائب.
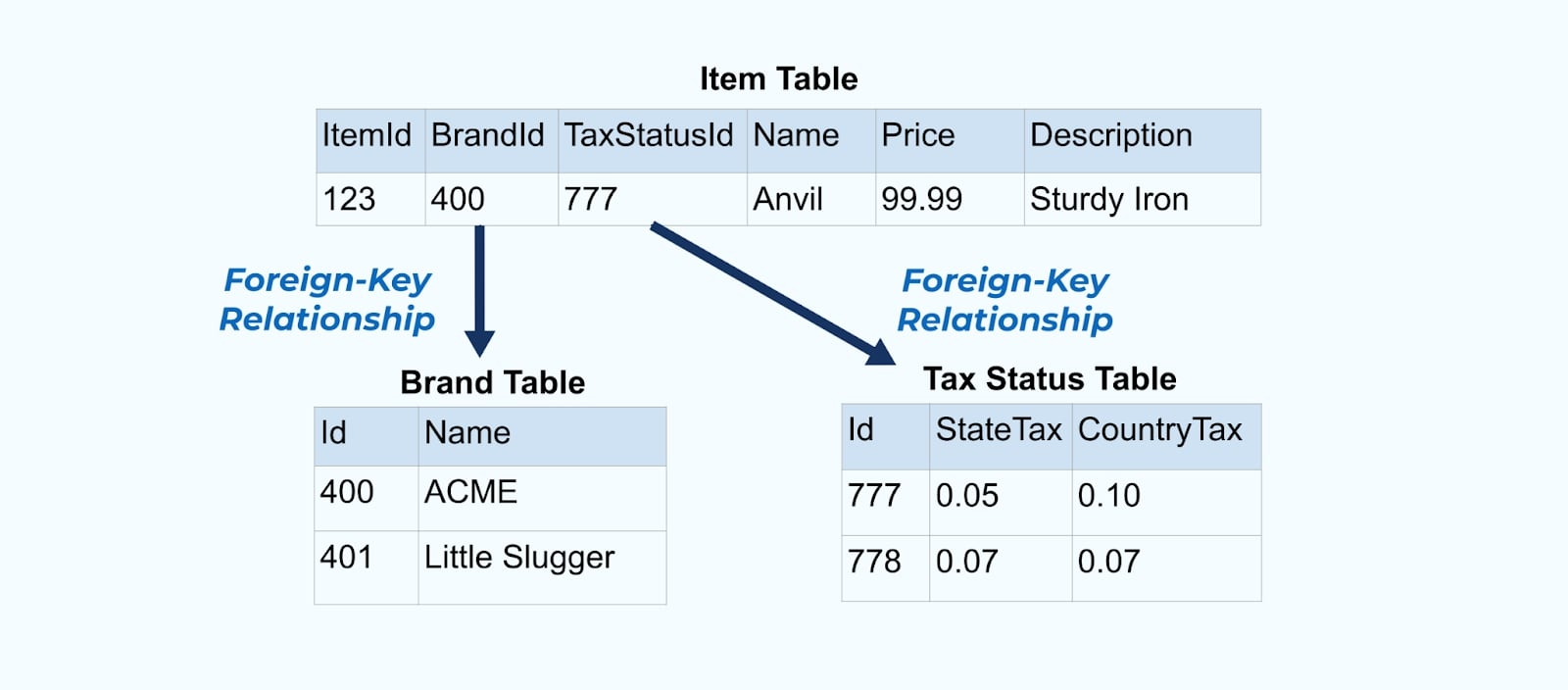
جداول العلامة التجارية و حالة الضرائب ترتبط بجدول المنتج من خلال علاقات المفاتيح الخارجية. بينما نعرض فقط منتجًا واحدًا في الجدول، من المحتمل أن يكون لديك آلاف (أو ملايين)، اعتمادًا على المنتجات التي تبيعها.
من الشائع إعداد موصل لكل جدول، سحب البيانات من الجدول، تكوينها كأحداث، وكتابة كل جدول إلى تيار أحداث مخصص.
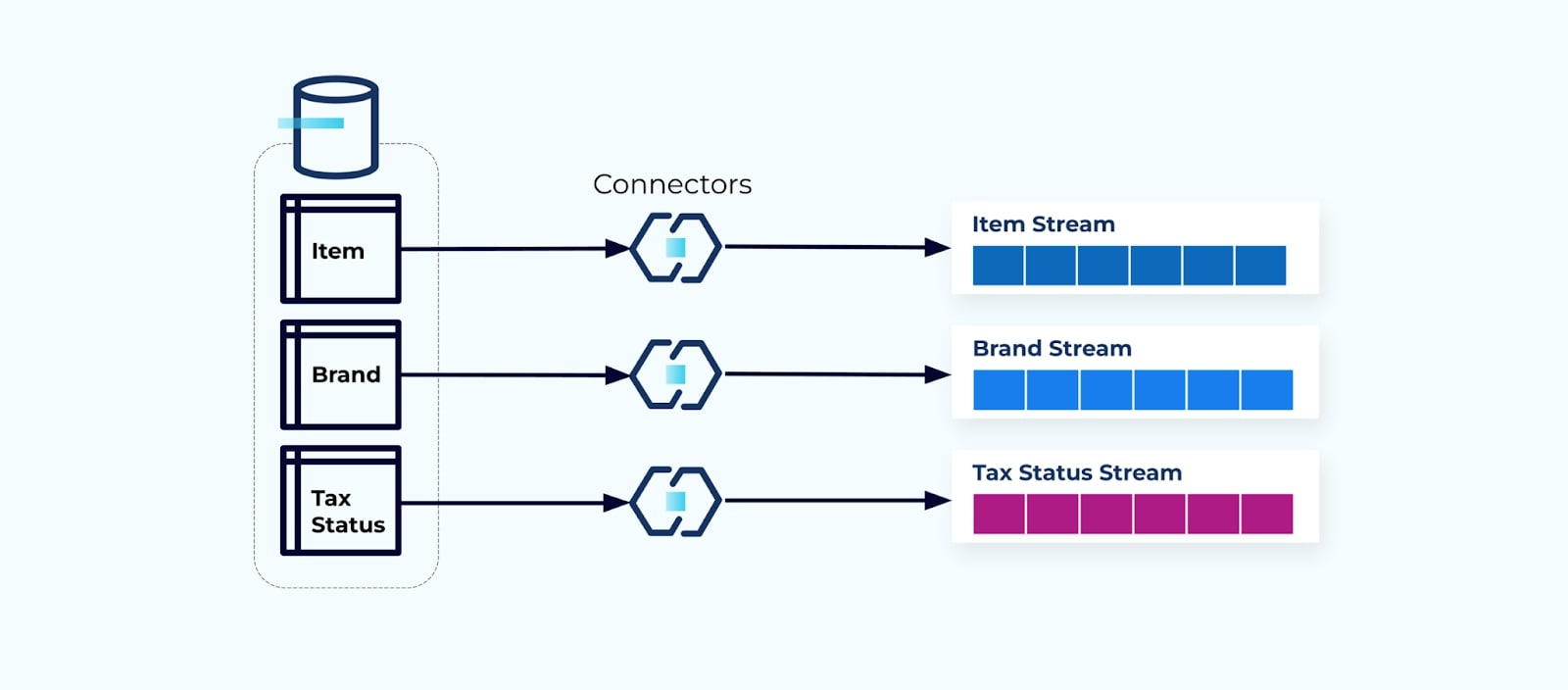
يؤدي الكشف عن الجداول الأساسية في قاعدة البيانات إلى تيار أحداث مكافئ لكل جدول. بينما يسهل البدء بهذه الطريقة، إلا أنها تؤدي إلى مشاكل متعددة، يمكن تلخيصها إما كمشكلة ربط مشكلة أو مشكلة تكلفة مشكلة. دعونا ننظر في كل منها.
المشكلة: تربط المستهلكون بالنموذج الداخلي
يكشف الجدول المصدر عنصر كما هو ي fuerza المستهلكين إلى الربط به مباشرة. ستؤثر التغييرات في نموذج البيانات لنظام المصدر على المستهلكين اللاحقين.
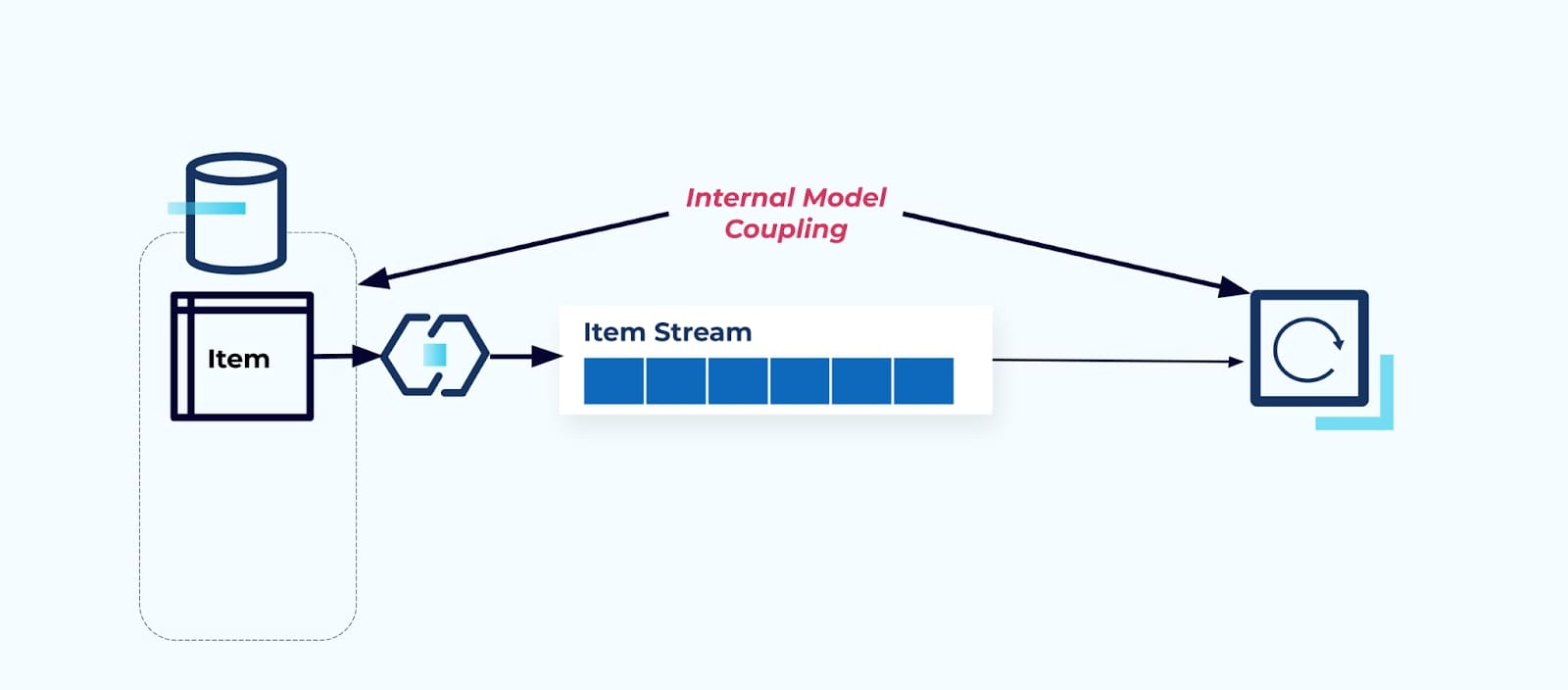
لنقل أننا أجرينا إعادة هيكلة الجدول عنصر لاستخراج سعر إلى جدوله الخاص.
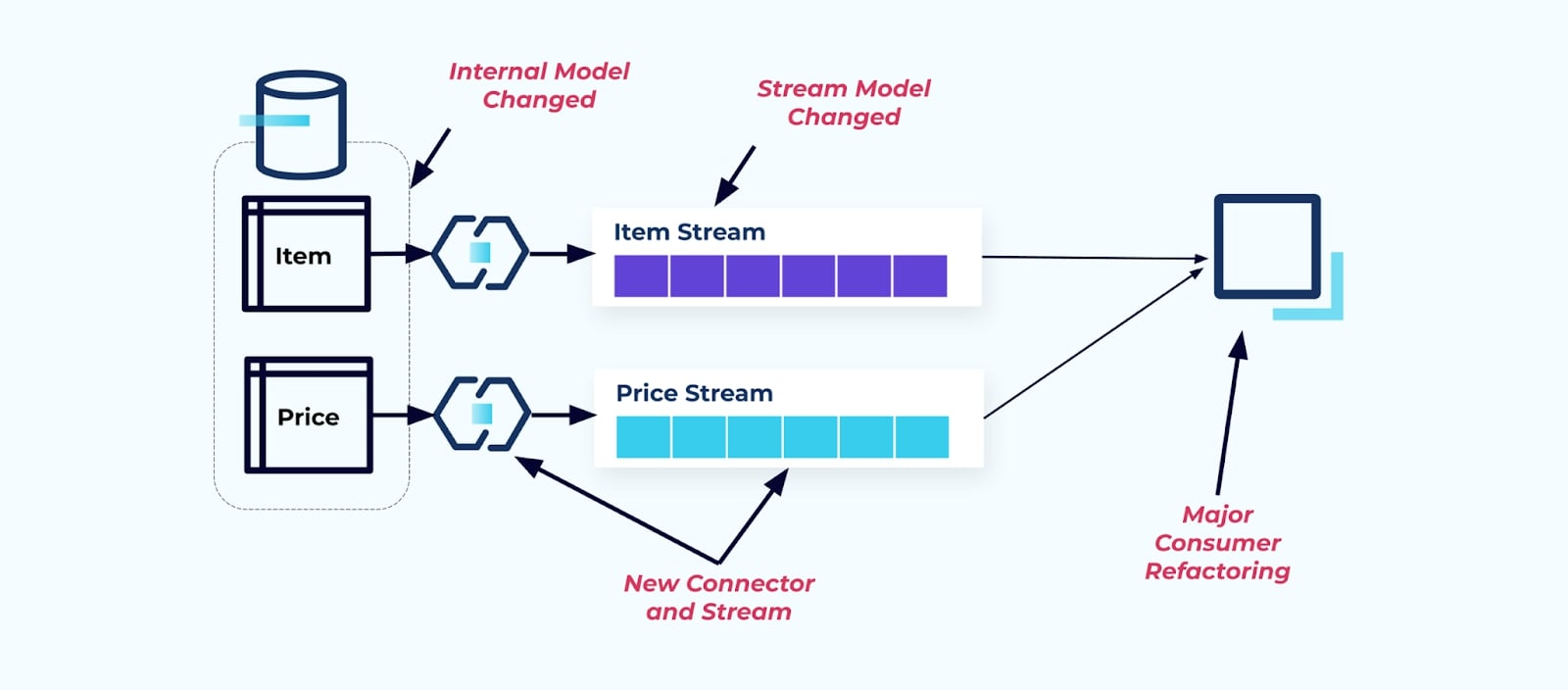
إعادة هيكلة جداول المصدر تؤدي إلى انتهاك عقد البيانات لنهر العنصر. لم يعد المستهلك يحصل على نفس بيانات العنصر التي كان يتوقعها في الأصل. يجب علينا أيضًا إنشاء موصل جديد — نهر جديد للأسعار — وأخيرًا، إعادة هيكلة منطق المستهلك لإعادة تشغيله. إعادة تسمية الأعمدة، تغيير القيم الافتراضية، وتغيير أنواع الأعمدة هي أشكال أخرى من التغييرات المدمرة التي تُدخلها الاعتمادية القوية على النموذج الداخلي للبيانات.
المشكلة: عمليات الدمج في التدفقات (عادةً) مكلفة
قواعد البيانات العلائقية مبنية خصيصًا لحل عمليات الدمج بسرعة وتكلفة زهيدة. ولكن عمليات الدمج في التدفقات، للأسف، ليست كذلك.
فكّر في خدمتين ترغبان في الوصول إلى العنصر، والضريبة الخاصة به، والعلامة التجارية الخاصة به. إذا كانت البيانات مكتوبة بالفعل في التدفقات المقابلة لها، فإن كل مستهلك (على اليمين في الصورة أدناه) سيحتاج إلى حساب نفس عمليات الدمج لتحويل Item، Brand، وTax إلى شكل غير عادي.
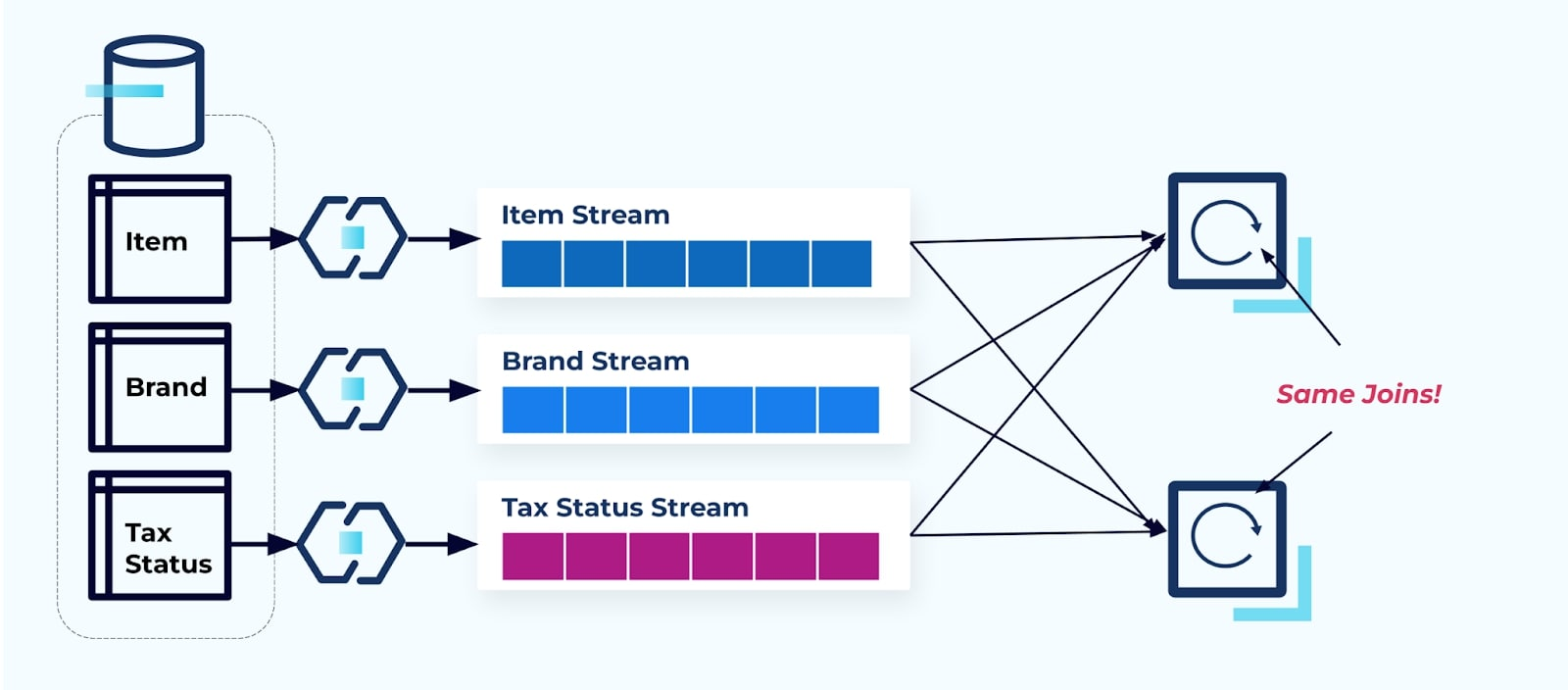
هذه الاستراتيجية يمكن أن تتسبب في تكاليف عالية، سواء في ساعات التطوير ل كتابة التطبيقات أو في تكاليف الخادم لحساب الجمعيات. حل الجمعيات التدفقات على نطاق واسع يمكن أن يؤدي إلى الكثير من تبادل البيانات، مما يتسبب في استهلاك طاقة معالجة، شبكات، وتكاليف تخزين. بالإضافة إلى ذلك، ليست كل أطر معالجة التدفقات تدعم الجمعيات، خاصة على المفاتيح الخارجية. من بين تلك التي تدعم ذلك، مثل Flink، Spark، KSQL، أو Kafka Streams (على سبيل المثال)، ستجد نفسك محدودًا بمجموعة فرعية من لغات البرمجة (Java، Scala، Python).
الحل: تقديم البيانات غير الطبيعية هو الأفضل
كمبدأ، اجعل تدفقات الأحداث سهلة الاستخدام لمستهلكيك. قم بتحويل البيانات إلى شكل غير طبيعي قبل جعلها متاحة للمستهلكين باستخدام طبقة تجريد وإنشاء نموذج خارجي واضح عقدة بيانات (البيانات في الخارج) للمستهلكين ليتم الربط عليها.
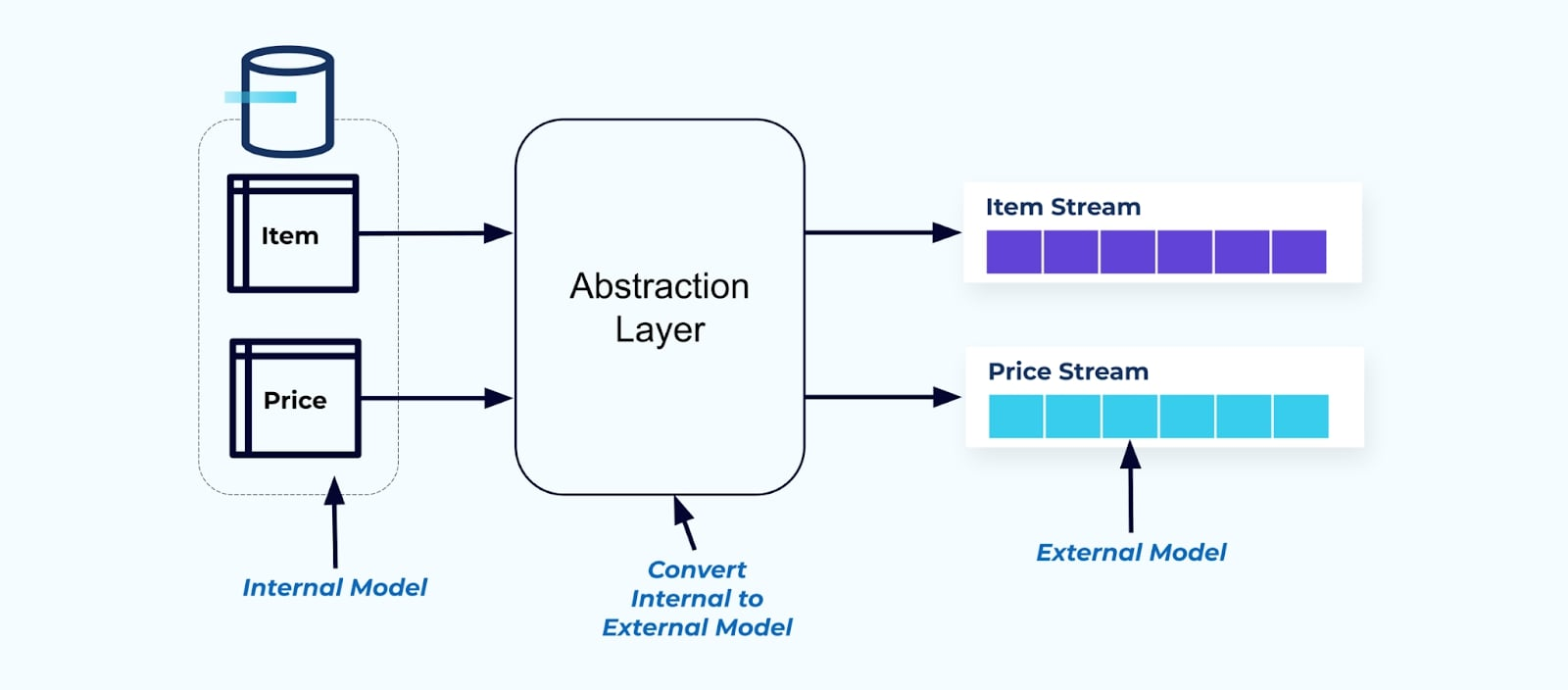
تظل التغييرات على النموذج الداخلي معزولة في أنظمة المصدر. يحصل المستهلكون على عقدة بيانات محددة جيدًا للربط عليها. يمكن أن تتم التغييرات التي تتم على نموذج المصدر دون عائق، طالما أن نظام المصدر يحافظ على عقدة البيانات للمستهلكين.
لكن أين نقوم بتحويل البيانات إلى شكل غير طبيعي؟ هناك خياران:
- إعادة البناء خارج نظام المصدر عبر خدمة جمع مخصصة.
- خلال إنشاء الحدث في نظام المصدر باستخدام نمط صندوق المعاملات.
دعونا ننظر في كل حل على حدة.
الخيار 1: تحويل البيانات إلى شكل غير طبيعي باستخدام خدمة جمع مخصصة
في هذا المثال، التدفقات على اليسار تعكس الجداول التي جاءت منها في قاعدة البيانات.
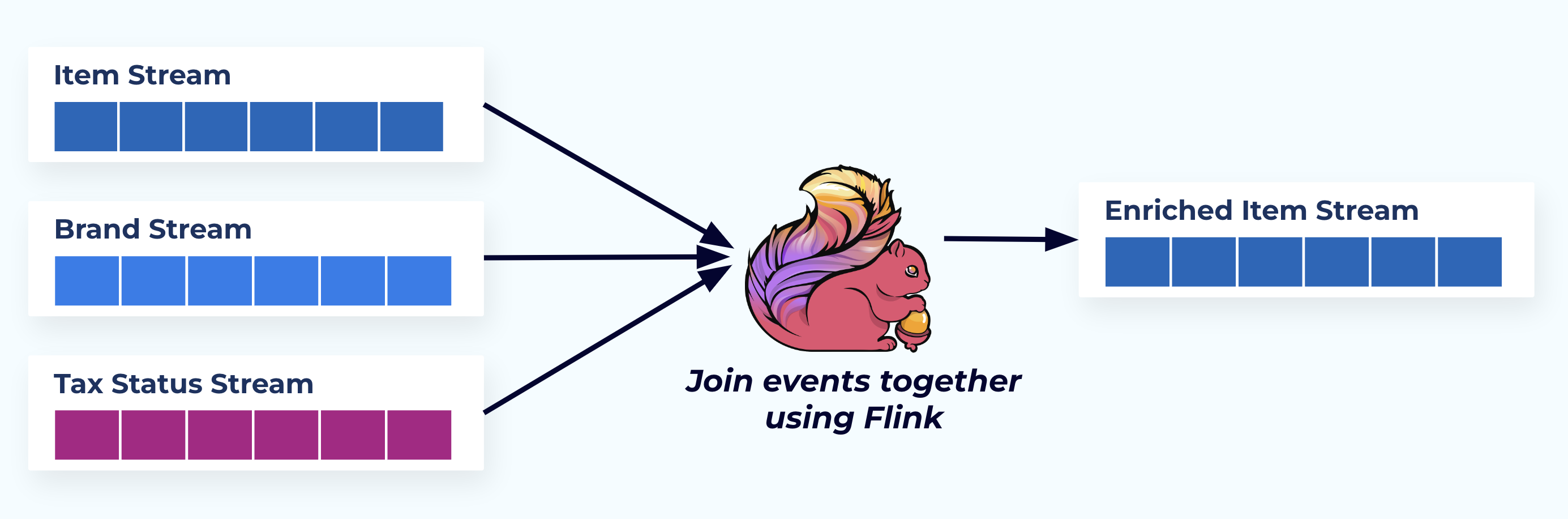
نحن نربط الأحداث باستخدام تطبيق مخصص (أو استعلام SQL مباشر) يعتمد على علاقات المفتاح الخارجي ونصدر تدفقًا واحدًا من العناصر المعززة.

من الناحية المنطقية، نحن نحل العلاقات ونسحق البيانات في صف واحد غير معياري.
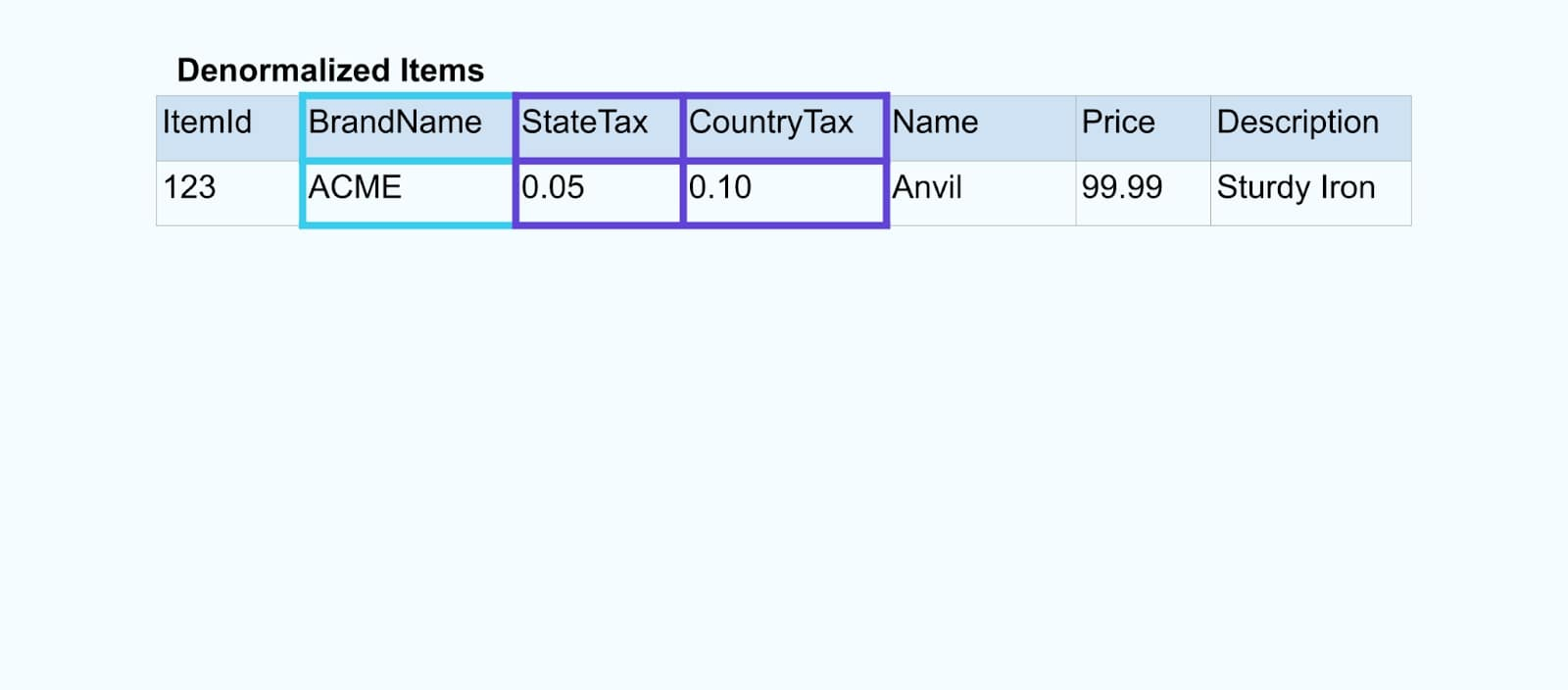
تعتمد أدوات الربط المخصصة على إطارات معالجة التدفقات مثل Apache Kafka Streams وApache Flink لحل كل من مفتاحي الربط الأساسي والخارجي. إنها تتجسد بيانات التدفق في تنسيقات جداول داخلية متينة، مما يتيح لتطبيق الربط الانضمام إلى الأحداث عبر أي فترة – وليس فقط تلك المقيدة بنافذة زمنية محدودة.
أدوات الربط التي تستخدم Flink أو Kafka Streams قابلة للتطوير بشكل ملحوظ – يمكنها التوسع والانكماش مع الحملة ومعالجة كميات هائلة من المرور.
نصيحة: لا تضع أي منطق أعمال في أداة الربط. لتحقيق النجاح في هذا النمط، يجب أن تعكس البيانات المربوطة المصدر بدقة، ببساطة كنتيجة غير معيارية. دع المستهلكين لاحقًا يطبقون منطقهم الخاص للأعمال، باستخدام البيانات غير المعيارية كمصدر وحيد للحقيقة.
إذا لم ترغب في استخدام أداة ربط لاحقة، فهناك خيارات أخرى. دعونا نلقي نظرة على نمط صندوق الصفقات التجارية التالي.
الخيار 2: نمط صندوق الصفقات التجارية
أولاً، أنشئ جدولًا مخصصًا للصندوق الخارجي لكتابة الأحداث في التدفق.
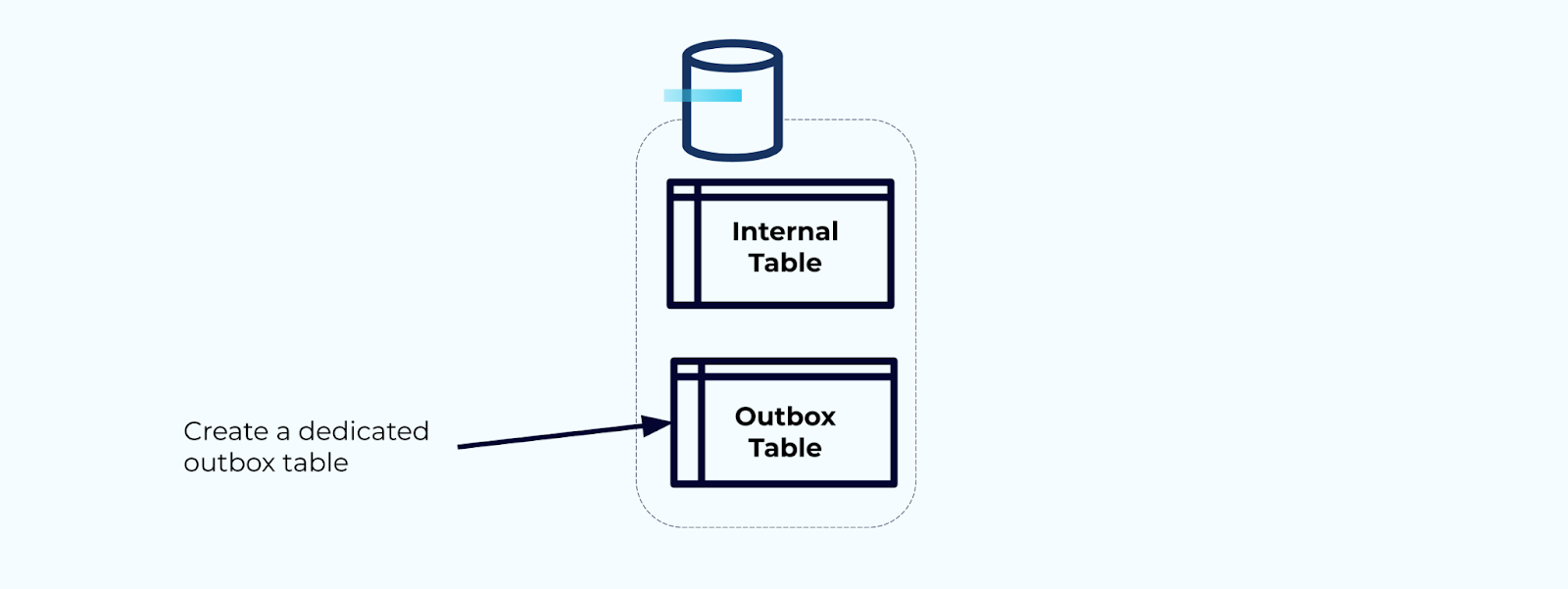
ثانياً، لف جميع تحديثات الجدول الداخلي الضرورية داخل معاملة. تضمن المعاملات أن أي تحديثات تُجري على الجدول الداخلي سيتم كتابتها أيضًا في جدول الصندوق الخارجي.
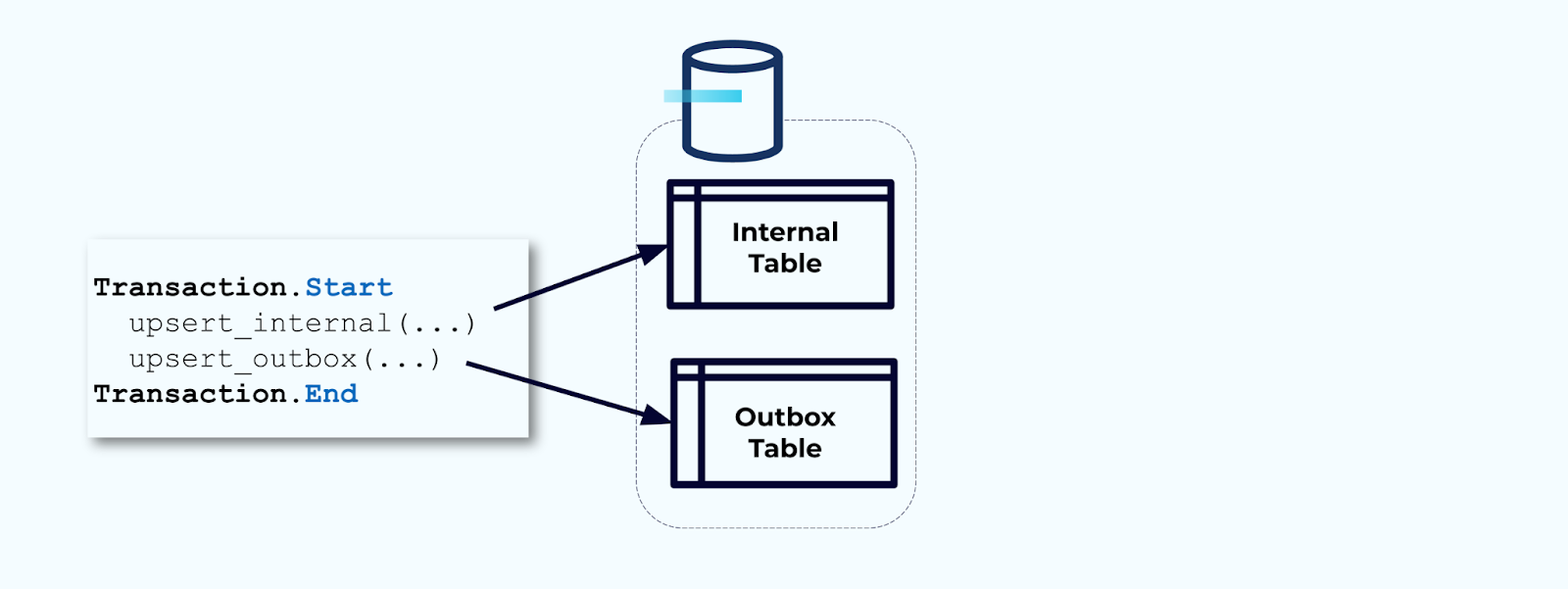
يسمح لك الصندوق الخارجي بفصل النموذج البياني الداخلي حيث يمكنك دمج وتحويل البيانات قبل كتابتها في صندوقك الخارجي. يتصرف الصندوق الخارجي كطبقة تجريد بين بياناتك الداخلية والخارجية، حيث يتصرف كعقد بيانات لمستهلكيك.
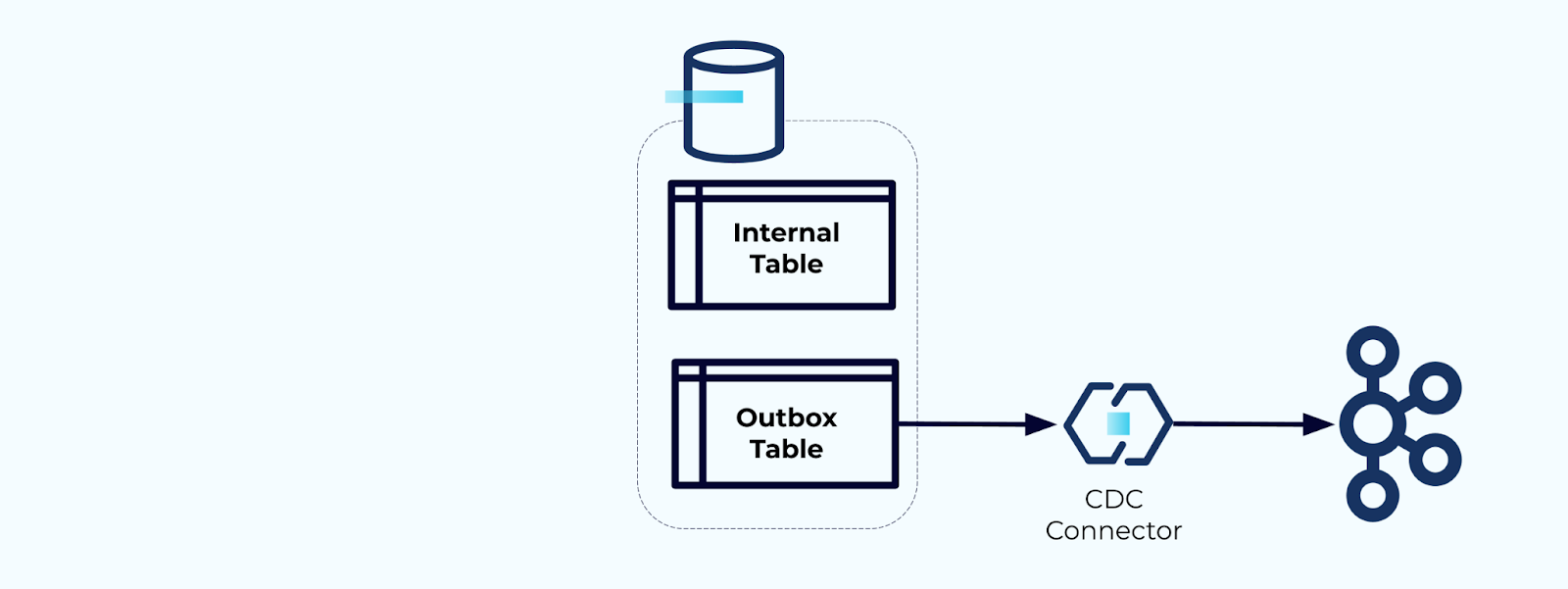
وأخيرًا، يمكنك استخدام موصل لنقل البيانات من الصندوق الخارجي إلى كافكا.
يجب عليك التأكد من أن الصندوق الخارجي لا ينمو بلا حدود – إما بحذف البيانات بعد التقاطها بواسطة CDC أو بشكل دوري بواسطة مهمة مجدولة.
مثال: تحويل تتبع أحداث سلوك المستخدم إلى شكل غير متوازن
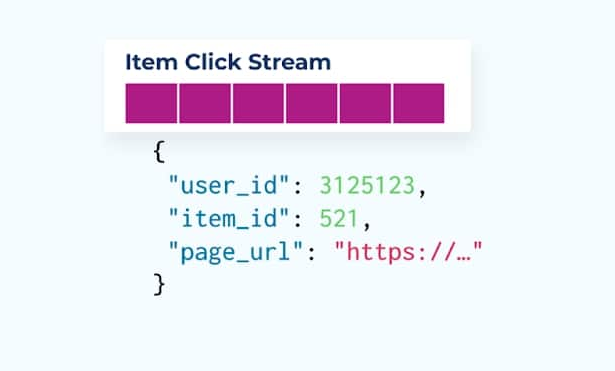
تتبع سلوك المستخدم في صفحات الويب وتطبيقاتك هو مصدر شائع للأحداث المتوازنة – فكر في Google Analytics أو الخيارات الداخلية الخاصة. لكننا لا ندرج جميع المعلومات في الحدث؛ بدلاً من ذلك، نقتصر على المعرفات (أسرع، أصغر، أرخص)، ونقوم بتحويلها إلى شكل غير متوازن بعد إنشاء الحقائق.
انظر إلى سلسلة من أحداث نقرات العنصر التي توضح عندما ينقر المستخدم على عنصر أثناء التصفح في منتجات التجارة الإلكترونية. لاحظ أن هذا حدث نقر العنصر لا يحتوي على معلومات أغنى عن العنصر مثل الاسم والسعر والوصف، فقط المعرفات الأساسية ids.
الأولى التي يقوم بها العديد من مستهلكي تيار النقرات هي دمجها مع تيار حقائق العنصر. ولأنك تتعامل مع العديد من أحداث النقر، تكتشف أن ذلك ينتهي باستخدام كمية كبيرة من موارد الحوسبة. تطبيق Flink مخصص يمكنه دمج نقرات العنصر مع بيانات العنصر التفصيلية وإصدارها إلى تيار نقرات العنصر المحسن.
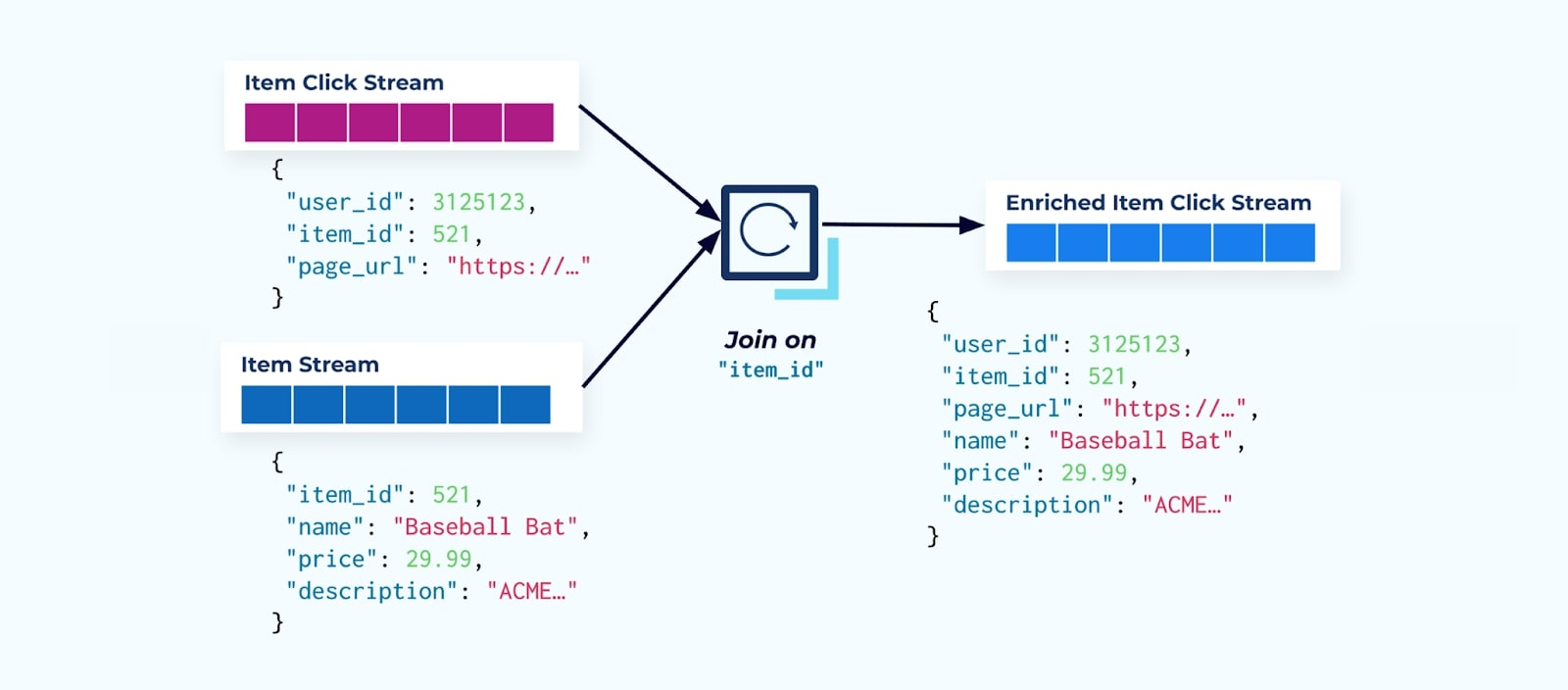
الشركات الكبيرة ذات الأقسام المتعددة (والأنظمة) ستشهد على الأرجح أن بياناتها تأتي من مصادر مختلفة، ودمجها بعد الحدث باستخدام مشترك التدفقات هو النتيجة الأكثر احتمالاً.
الاعتبارات المتعلقة بالأبعاد المتغيرة ببطء
لقد ناقشنا بالفعل اعتبارات الأداء لكتابة أحداث تحتوي على مجموعات بيانات كبيرة (مثل، نصوص كبيرة) و مجالات بيانات تتغير بشكل متكرر (مثل، مخزون العنصر). الآن، سننظر في الأبعاد المتغيرة ببطء (SCDs)، التي غالباً ما يتم الإشارة إليها عبر علاقة مفتاح خارجي، حيث يمكن أن تكون مصدراً آخر لحجوم بيانات كبيرة.
دعونا نعود إلى مثال العنصر مرة أخرى. لنفترض أن لديك عملية تقوم بتحديث جدول العنصر. سنقوم بتغيير اسم العنصر من “Anvil” إلى “Iron Anvil”.
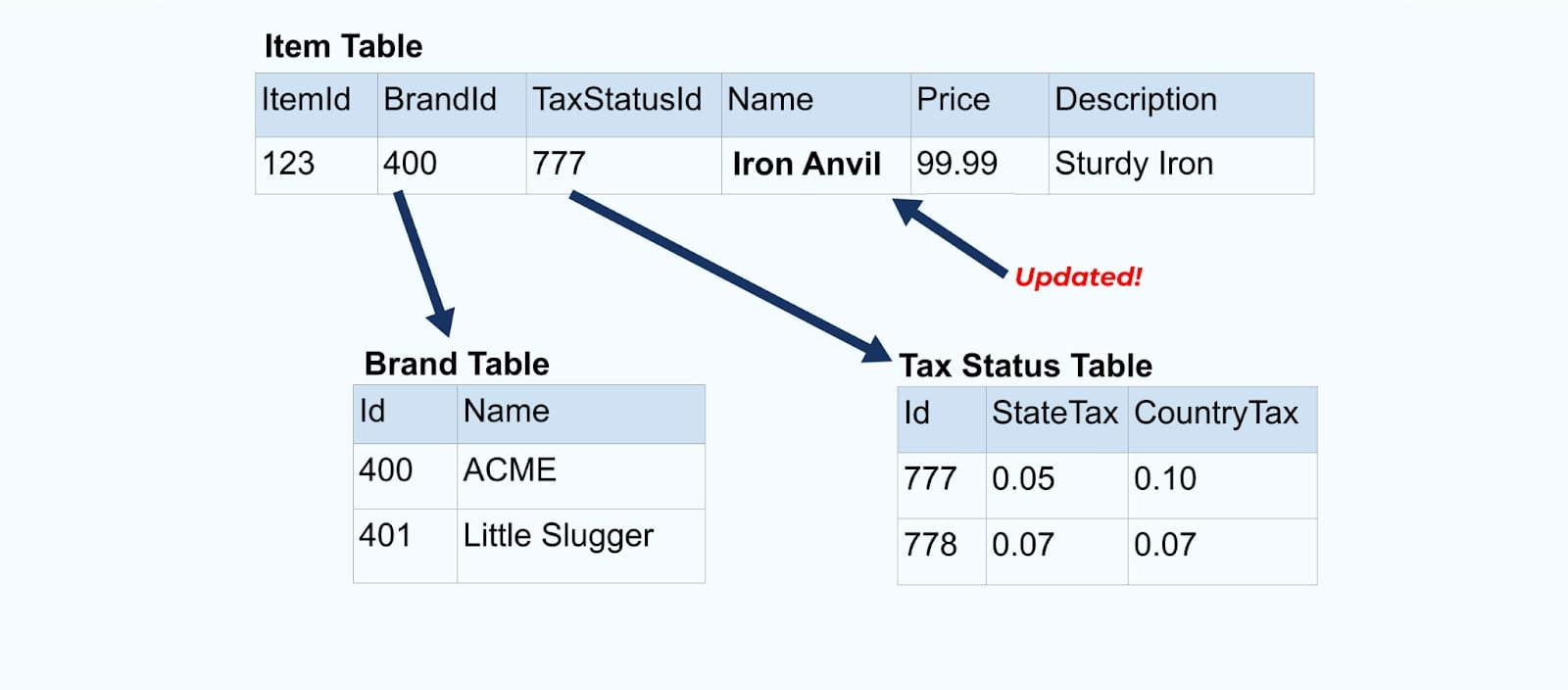
عند تحديث البيانات في قاعدة البيانات، نقوم أيضاً بإصدار العنصر المحدث (لنقل عبر نمط الصندوق الخارجي)، كاملاً مع حالة الضرائب والجدول العلامة التجارية غير الطبيعي.
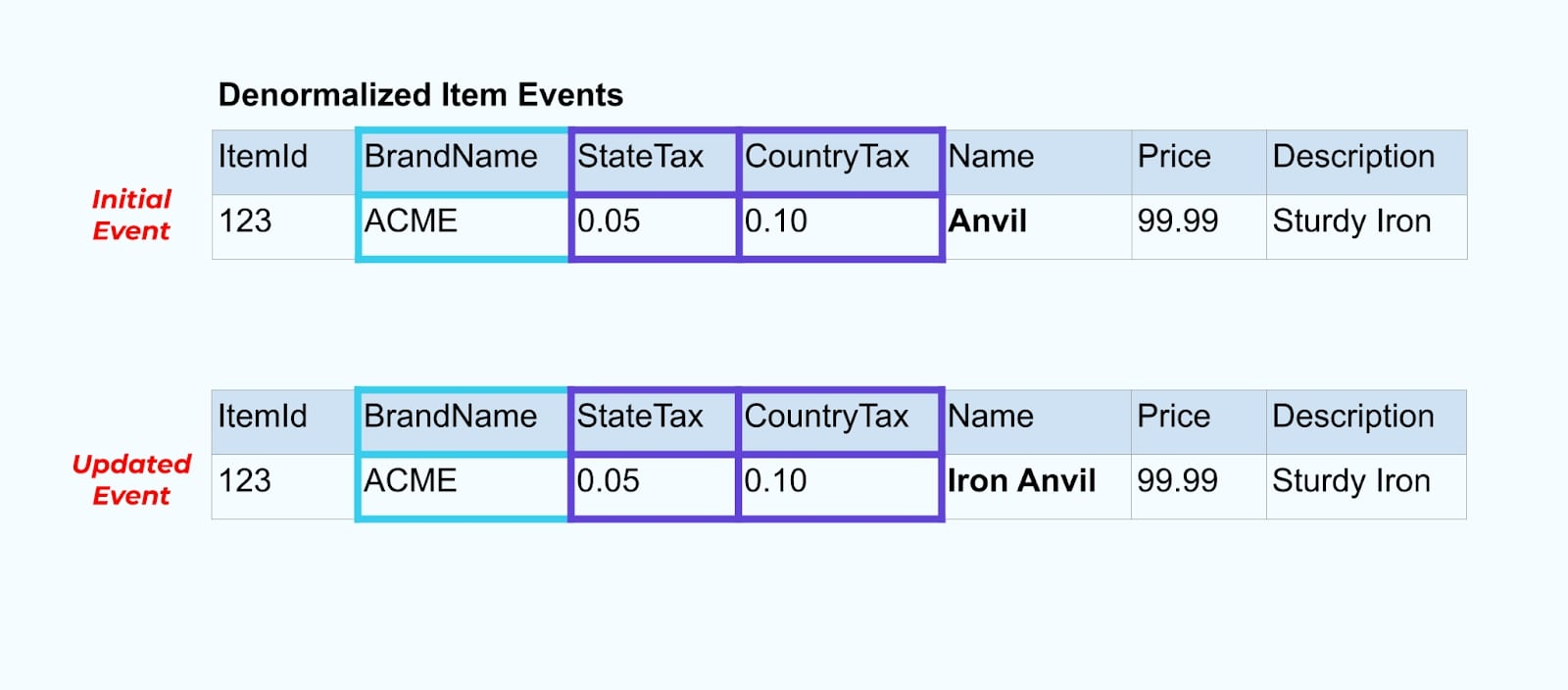
ومع ذلك، نحتاج أيضًا إلى النظر في ما يحدث عند تغيير القيم في جداول العلامة التجارية أو الضرائب. تحديث أحد هذه الأبعاد المتغيرة ببطء يمكن أن يؤدي إلى عدد كبير جداً من التحديثات لجميع العناصر المتأثرة.
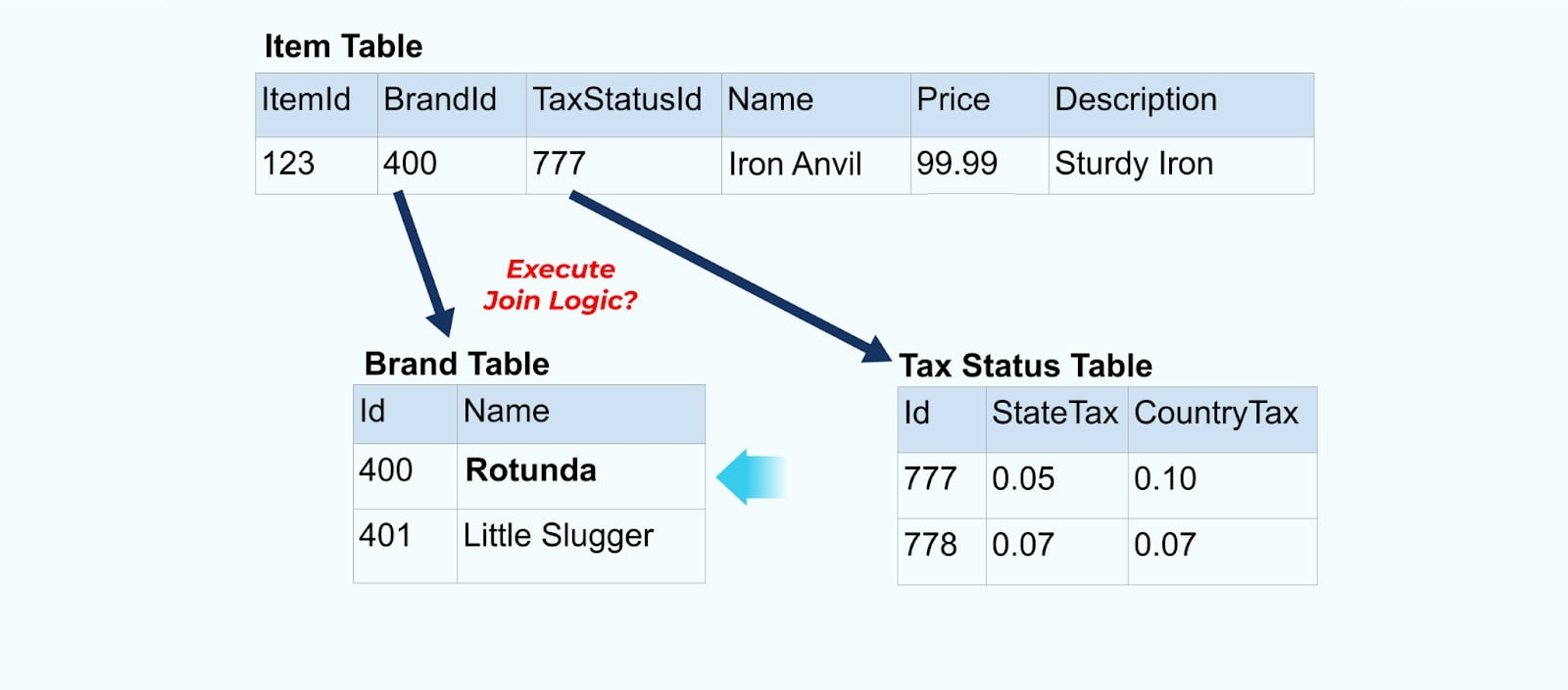
على سبيل المثال، تمر شركة ACME بعملية إعادة تسمية العلامة التجارية وتأتِ باسم علامة تجارية جديد، تتغير من ACME إلى Rotunda. ننتج حدثًا آخر لـ ItemId=123.
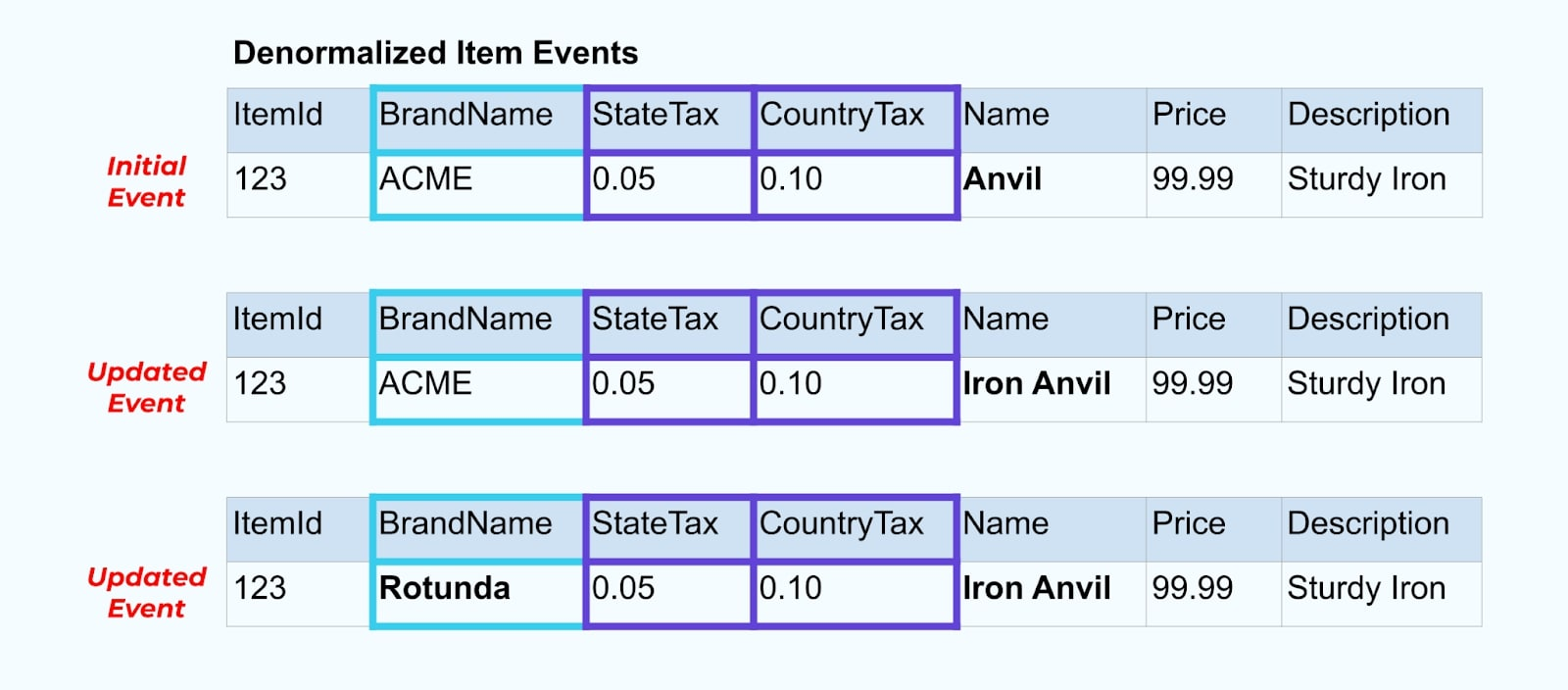
ومع ذلك، من المحتمل أن تكون شركة Rotunda (سابقًا ACME) تمتلك مئات (أو آلاف) من العناصر التي يتم تحديثها أيضًا بهذا التغيير، مما يؤدي إلى عدد مماثل من أحداث العناصر المعززة المحدثة.
عند تحويل SCDs والعلاقات الخارجية، تأكد من مراعاة تأثير تغيير SCD على تيار الأحداث ككل. قد تقرر التخلي عن التحويل وتركه للمستهلك في الحالة التي يؤدي فيها تغيير SCD إلى ملايين أو مليارات من أحداث التحديث.
ملخص
التحويل يجعل من السهل على المستهلكين استخدام البيانات، لكنه يأتي على حساب المزيد من المعالجة في النهاية العليا واختيار دقيق للبيانات لشملها. قد يجد المستهلكون سهولة أكبر في بناء التطبيقات ويمكنهم الاختيار من مجموعة أوسع من التقنيات، بما في ذلك تلك التي لا تدعم بشكل أصلي عمليات الدمج التدفقي.
تحويل البيانات في النهاية العليا يعمل بشكل جيد عندما تكون البيانات صغيرة وتُحدّث بشكل نادر. أحجام الأحداث الكبيرة، التحديثات المتكررة، وSCDs هي جميعها عوامل يجب مراقبتها عند تحديد ما يجب تحويله في النهاية العليا وما يجب تركه للمستهلكين للقيام به بأنفسهم.
في النهاية، اختيار البيانات التي يجب تضمينها في حدث وما يجب تركه هو توازن بين احتياجات المستهلكين، قدرات المنتجين، والعلاقات الفريدة لنموذج البيانات. لكن أفضل مكان للبدء هو فهم احتياجات المستهلكين و فصل نموذج البيانات الداخلي لنظام المصدر الخاص بك.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2