













ظهور نظام الملفات الموزع Apache Hadoop (HDFS) أحدث ثورة في تخزين ومعالجة وتحليل البيانات لدى الشركات، مما سرع النمو في مجال البيانات الضخمة وأحدث تغييرات تحولية في الصناعة.
في البداية، كان يحتوي Hadoop على تكامل التخزين والحوسبة، لكن ظهور الحوسبة السحابية أدى إلى فصل هذه المكونات. ظهر التخزين الكائني كبديل لـ HDFS ولكنه كان يعاني من قيود. لاستكمال هذه القيود، JuiceFS، وهو نظام ملفات موزع عالي الأداء مفتوح المصدر، يقدم حلولاً مكلفة التكلفة للسيناريوهات المعقدة بالبيانات مثل الحوسبة والتحليل والتدريب. قرار تبني فصل التخزين والحوسبة حسب عوامل مثل القابلية للتوسع والأداء والتكلفة والتوافق.
في هذا المقال، سنراجع بنية Hadoop، ونناقش أهمية وقابلية فصل التخزين والحوسبة، ونستكشف الحلول المتاحة في السوق، مما يسلط الضوء على مزاياها وعيوبها. نهدف إلى تزويد الشركات المتعهدة بتحول بنية فصل التخزين والحوسبة بالرؤى والإلهام.
ميزات تصميم بنية Hadoop
Hadoop كإطار عمل شامل
في عام 2006، تم إصدار Hadoop كإطار عمل شامل يتكون من ثلاثة أجزاء:
- MapReduce للحوسبة
- YARN لجدولة الموارد
- HDFS لتخزين الملفات الموزع
 Core components of Hadoop
Core components of Hadoopمكونات الحوسبة المتنوعة
من بين هذه المكونات الثلاثة، شهد طبقة الحوسبة تطورًا سريعًا. في البداية، كان هناك فقط MapReduce، لكن الصناعة سرعان ما شهدت ظهور إطارات مختلفة مثل Tez و Spark للحوسبة، و Hive لمستودعات البيانات، ومحركات الاستعلام مثل Presto و Impala. بالاشتراك مع هذه المكونات، هناك العديد من أدوات نقل البيانات مثل Sqoop.

HDFS هيئ النظام التخزيني
خلال ما يقرب من عشر سنوات، ظل HDFS، نظام الملفات الموزع، هو النظام التخزيني المهيمن. كان الخيار الافتراضي لجميع مكونات الحوسبة تقريبًا. تم تصميم جميع المكونات المذكورة أعلاه داخل النظام البيئي للبيانات الكبيرة لواجهة برمجة التطبيقات HDFS. تستفيد بعض المكونات بعمق من القدرات الخاصة لـ HDFS. على سبيل المثال:
- HBase تستخدم قدرات كتابة HDFS ذات الطابعة المنخفضة للسرعة في سجلات الكتابة المسبقة.
- MapReduce و Spark قدما ميزات الموازنة المحلية للبيانات.
اختيارات التصميم لهذه المكونات الكبيرة للبيانات، على أساس واجهة برمجة التطبيقات HDFS، أحدثت تحديات محتملة لنشر منصات البيانات على الشبكة السحابية.
الهيكل المتزامن بين التخزين والحوسبة
المخطط التالي يوضح جزء من هيكل HDFS المبسط، الذي يربط الحوسبة بالتخزين.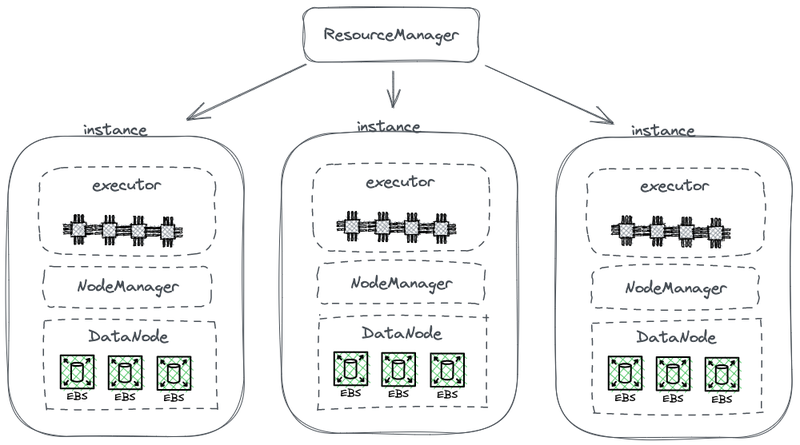
هاردوب إنفوجرافيك آركيتيكتور في ستوريج آند كامبيوت
في هذا المخطط، كل عقدة تعمل كـ HDFS DataNode لتخزين البيانات. بالإضافة إلى ذلك، ينشر YARN عملية Node Manager على كل عقدة. هذا يمكّن YARN من التعرف على العقدة كجزء من مواردها المُدارة لمهام الحوسبة. يسمح هذا الهيكل بتواجد التخزين والحوسبة في نفس الجهاز، ويمكن قراءة البيانات من القرص أثناء الحوسبة.
لماذا هاردوب يربط التخزين والحوسبة
تم ربط التخزين والحوسبة في هاردوب نظرًا للقيود التي واجهتها شبكة الاتصالات والأجهزة خلال مرحلة تصميمه.
في عام 2006، كانت الحوسبة السحابية لا تزال في مراحلها الأولى، وكانت أمازون قد أصدرت خدمتها الأولى. في مراكز البيانات، كانت بطاقات الشبكة السائدة تعمل بشكل أساسي بسرعة 100 ميغابت/ثانية. وكانت مسحوق البيانات المستخدمة لحسابات البيانات الكبيرة يحقق معدل تنفيذ حوالي 50 ميغابايت/ثانية، مما يعادل 400 ميغابت فيما يتعلق بالنطاق الترددي الشبكة.
يعتبر العقدة التي تحتوي على ثمانية أقراص تعمل بأقصى طاقة ممكنة، والتي كانت تحتاج إلى عدة جيجابت في الثانية من سعة الشبكة لتحقيق نقل البيانات بكفاءة. لسوء الحظ، كانت سعة البطاقات الشبكية القصوى محدودة إلى 1 جيجابت في الثانية. نتيجة لذلك، كانت سعة الشبكة لكل عقدة لا تكفي لاستغلال قدرات جميع الأقراص داخل العقدة بشكل كامل. ونتيجة لذلك، إذا كانت مهام الحوسبة على أحد طرفي الشبكة وكانت البيانات موجودة على عقد البيانات على الطرف الآخر، كانت سعة الشبكة عقبة كبيرة.
لماذا يكون فصل التخزين عن الحوسبة هو شيء ضروري
من عام 2006 إلى حوالي عام 2016، واجهت الشركات القضايا التالية:
- كان الطلب على قوة الحوسبة والتخزين في التطبيقات غير متوازن، وكانت معدلات نموها مختلفة. بينما كانت نمو البيانات التابعة للشركات سريعًا، لم يكن الحاجة إلى قوة الحوسبة تنمو بهذا السرور. فالمهام التي طورها البشر لم تتضاعف بشكل كبير في فترة قصيرة. ومع ذلك، كانت البيانات التي تم إنتاجها من هذه المهام تتراكم بسرعة، ربما بشكل كبير. علاوة على ذلك، قد لا تكون بعض هذه البيانات مفيدة للشركة في الوقت الراهن، لكنها ستكون ذات قيمة في المستقبل. ولذلك، قامت الشركات بتخزين البيانات بشكل شامل لاستكتشاف قيمتها المحتملة.
- خلال التوسعة، اضطرت الشركات لتوسيع الحساب والتخزين بشكل متزامن، مما أدى غالبًا إلى هدر موارد الحوسبة. تأثر توجه الأجهزة للبنية المشتركة للتخزين والحوسبة بتوسيع السعة. عندما كانت سعة التخزين غير كافية، كان علينا لا سيما إضافة الآلات ولكن أيضا ترقية المعالجات المركزية وذاكرة الوصول العشوائي لأن العقد الذي يحمل البيانات في الهيكل المشترك كان مسؤولا عن الحوسبة. ومن ثم، كانت الآلات مجهزة بقوة حسابية متوازنة وتكوين تخزين، مما يوفر سعة تخزين كافية مع قوة حوسبة متماثلة. ومع ذلك، لم يزداد الطلب الفعلي على قوة الحوسبة كما توقعت. نتيجة لذلك، تسبب الحوسبة الموسعة في هدر كبير للشركات.
- صبّ صعوبة الموازنة بين الحوسبة والتخزين واختيار الآلات المناسبة. استخدام الموارد للمجموعة الكاملة فيما يتعلق بالتخزين وإدخال/إخراج يمكن أن يكون غير متوازن بشكل كبير، وقد يفاقم هذا التفاوت مع توسع المجموعة. علاوة على ذلك، كان من الصعب شراء الآلات المناسبة، حيث كان على الآلات أن تجد التوازن بين متطلبات الحوسبة والتخزين.
- لأن البيانات يمكن أن توزع بشكل غير متساو، كان من الصعب جداً جداً تحديد مهام الحوسبة بشكل فعال على الحالات التي توجد فيها البيانات. قد لا تعالج استراتيجية جدولة البيانات المحلية بشكل فعال السيناريوهات الحقيقية نظرًا لاحتمال توزيع البيانات غير المتوازن. على سبيل المثال، قد تصبح بعض العقد نقاط ساخنة محلية، مما يتطلب قوة حوسبة أكبر. ونتيجة لذلك، حتى إذا تم جدولة مهام البيانات الكبيرة على هذه العقد الساخنة، قد يصبح أداء إدخال/إخراج عامل محدد.
لماذا فصل التخزين والحوسبة ممكن
أصبحت إمكانية فصل التخزين والحوسبة على ما يرام بفضل التقدم في الأجهزة والبرامج بين عامي 2006 و2016. تشمل هذه التطورات:
بطاقات الشبكة
تبنى بطاقات الشبكة 10 جي بشكلٍ كبير، مع زيادة التوافر لقدرات أعلى مثل 20 جي، 40 جي، وحتى 50 جي في مراكز البيانات وبيئات السحابة. في سيناريوهات الذكاء الاصطناعي، تستخدم بطاقات شبكة بسعة 100 جي ب أيضاً. هذا يمثل زيادة كبيرة في سعة الشبكة بمقدار أكثر من 100 مرة.
أقراص
تعتمد العديد من الشركات بقاء على حلول قاعدة بيانات مبنية على الأقراص في مجموعات البيانات الكبيرة. ارتفعت معدلات النقل للأقراص من 50 ميغابايت/ثانية إلى 100 ميغابايت/ثانية. تستطيع مثيل مجهز ببطاقة شبكة 10 جي ب تشغيل تدفق نقل عالي مثل 12 أقراص. هذا يكفي لمعظم الشركات، وبالتالي، لم يعد النقل الشبكي قا瓶颈.
برمجيات
استخدام خوارزميات الضغط الفعال مثل سنابي، لز4، وزستاندارد وأشكال التخزين العمودي مثل آفرو، باركويت، وأورك قد خففت أيضاً ضغط الإي/أو. تحولت القا瓶颈 في معالجة البيانات الكبيرة من الإي/أو إلى أداء المعالج.
كيفية تنفيذ فصل التخزين والحوسبة
المحاولة الأولى: نشر HDFS المستقل في السحابة
نشر HDFS المستقل
منذ عام 2013، كانت هناك محاولات داخل الصناعة لفصل التخزين والحوسبة. الأسلوب الأولي عادل تمامًا، ويتضمن نشر HDFS بشكل مستقل دون دمجه مع العمال الحوسبية. لم يُدخل هذا الحل أي مكونات جديدة إلى النظام البيئي لـ Hadoop.
كما هو موضح في الرسم التخطيطي أدناه، لم يعد NodeManager يتم نشره على DataNodes. هذا يشير إلى أن المهام الحسابية لم تعد تُرسل إلى DataNodes. تحول التخزين إلى مجموعة منفصلة، وتم نقل البيانات المطلوبة للحسابات عبر الشبكة، مدعومة ببطاقات شبكة 10 جيجابت بين نقطتي نقل. (لاحظ أن خطوط النقل الشبكية لم تُظهر في الرسم التخطيطي.)

على الرغم من أن هذا الحل كان يتخلى عن ميزة الوجود المحلي للبيانات، التصميم الأكثر براعة في HDFS، إلا أن سرعة الاتصال الشبكي المتزايدة قامت بتسهيل تكوين الخوادم بشكل كبير. تم الكشف عن هذا من خلال التجارب التي أجراها ديفيس، الشريك المؤسس في Juicedata، وزملاؤه خلال فترتهم في فيسبوك عام 2013. أثبتت النتائج جدوى النشر وإدارة العقد الحسابية بشكل مستقل.
ومع ذلك، لم تتابع هذه المحاولة تطويرًا. السبب الرئيسي هو تحديات نشر HDFS على السحابة.
تحديات نشر HDFS على السحابة
يواجه نشر HDFS على السحابة القضايا التالية:
- تعمل آلية تكرار متعدد في HDFS على زيادة تكلفة الشركات على السحابة:في الماضي، استخدمت الشركات الأقراص المجردة لبناء نظام HDFS في مراكز البيانات الخاصة بهم. للتخفيف من مخاطر تلف الأقراص، نفذت HDFS آلية التكرار المتعدد لضمان سلامة البيانات وتوافرها. ومع ذلك، عند نقل البيانات إلى السحابة، تقدم مزودو الخدمات السحابية أقراص السحابة التي تتمتع بالفعل بآلية التكرار المتعدد. ونتيجة لذلك، تحتاج الشركات إلى تكرار البيانات ثلاث مرات داخل السحابة، مما يؤدي إلى زيادة كبيرة في التكاليف.
- خيارات محدودة للتوزيع على أقراص مجردة:على الرغم من أن مزودي الخدمات السحابية تقدمون بعض أنواع الآلات مع أقراص مجردة، إلا أن الخيارات المتاحة محدودة. على سبيل المثال، من بين 100 نوع من أنواع الآلات الافتراضية المتاحة في السحابة، يدعم فقط 5-10 نوع من الآلات الأقراص المجردة. قد لا يلبي هذا الاختيار المحدود متطلبات الكومة الخاصة بالشركات.
- عدم القدرة على الاستفادة من المزايا الفريدة للسحابة:نشر HDFS على السحابة يتطلب إنشاء الآلات يدويًا، ونشرها، وصيانتها، ومراقبتها، والعمليات دون راحة التحجيم المرن ونموذج الدفع وفقًا لاستخدامك. وهذه هي المزايا الرئيسية لحوسبة السحابة. وبالتالي، ليس من السهل نشر HDFS على السحابة في حين تحقيق فصل التخزين عن الحوسبة.
قيود HDFS
لدى HDFS هذه القيود:
- القدرة التوافقية المحدودة لـ NameNodes:يمكن لـ NameNodes في HDFS التوسع فقط عموديًا ولا يمكنها التوسع بشكل موزع. تفرض هذه القيد على عدد الملفات التي يمكن إدارتها داخل مجموعة HDFS واحدة.
- تخزين أكثر من 500 مليون ملف يجلب تكاليف عمليات مرتفعة: وفقاً لخبرتنا، من السهل عملياً التشغيل والصيانة لـ HDFS مع أقل من 300 مليون ملف. عندما يتجاوز عدد الملفات 500 مليون، يجب تنفيذ آلية HDFS Federation. ومع ذلك، هذا يضيف تكاليف عالية للعمليات وإدارتها.
- استخدام الموارد العالي والإشغال الشديد للـ NameNode يؤثر على توافر سلسلة HDFS: عندما يستهلك NameNode الكثير من الموارد مع حمل عالٍ، قد يتم تشغيل جمعية زبالة كاملة (GC). هذا يؤثر على توافر السلسلة الكاملة لـ HDFS. قد يواجه تخزين النظام وقف التشغيل، مما يجعله غير قادر على قراءة البيانات، ولا يمكن التدخل في عملية GC. لا يمكن تحديد مدة التجمد النظامي. لقد كان هذا مشكلة دائمة في سلاسل HDFS عالية الحمل.
السحابة العامة + تخزين الكائنات
مع تقدم حوسبة السحابة، أصبحت الشركات الآن تتخيل استخدام تخزين الكائنات كبديل لـ HDFS. تخزين الكائنات مصمم خصيصاً لتخزين بيانات غير منظمة على نطاق واسع، مع توفير هيكل لتحميل وتنزيل البيانات بسهولة. يوفر سعة تخزين قابلة للتوسع بشكل كبير، مما يضمن كفاءة التكلفة.
فوائد تخزين الكائنات كبديل لـ HDFS
اكتسب تخزين الكائنات جذباً، بدءاً من AWS ومن ثم اعتماده من قبل مزودي السحابة الآخرين كبديل لـ HDFS. المزايا التالية ملحوظة:
- مدعومة من الخدمة وجاهزة للاستخدام: تخزين الكائنات لا يتطلب نشراً أو مراقبة أو مهام صيانة، مما يوفر تجربة مريحة وعملية للمستخدم.
- التحجيم المرن والدفع حسب الاستخدام: تدفع الشركات مقابل تخزين الكائنات بناءً على استخدامها الفعلي، مما يلغي الحاجة إلى تخطيط السعة. يمكنهم إنشاء سلة لتخزين الكائنات وتخزين ما يلزم من بيانات دون اهتمام بقيود سعة التخزين.
عيوب تخزين الكائنات
ومع ذلك، عند استخدام تخزين الكائنات لدعم نظم البيانات المعقدة مثل Hadoop، تنشأ التحديات التالية:
عيب رقم 1: ضعف أداء قائمة الملفات
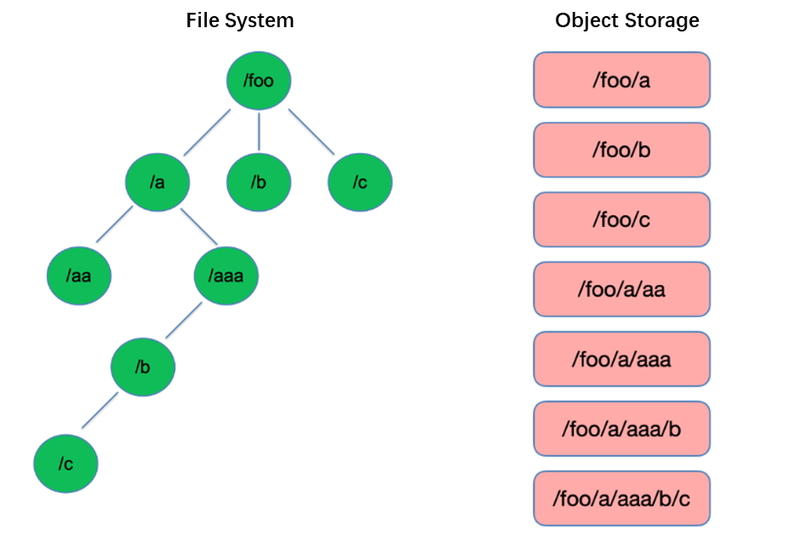
القائمة هي إحدى أسهل العمليات في نظام الملفات. إنها خفيفة الوزن وسريعة في الهياكل الشجرية مثل HDFS.
على النقيض من ذلك، يتبنى تخزين الكائنات هيكلًا مسطحًا ويتطلب الفهرسة مع المفاتيح (المعرفات الفريدة) لتخزين واسترداد آلاف أو حتى مليارات الكائنات. نتيجة لذلك، عند إجراء عملية القائمة، يمكن لتخزين الكائنات البحث فقط ضمن هذا الفهرس، مما يؤدي إلى أداء أقل بكثير مقارنة بالهياكل الشجرية.
عيب رقم 2: نقص قدرة التعيين الأصلي، مما يؤثر على أداء واستقرار المهمة
في نماذج الحوسبة لاستخراج، تحويل، وتحميل (ETL)، يكتب كل مهمة جزئية نتائجها إلى دليل مؤقت. عندما يكتمل المهمة بأكملها، يمكن تعيين الدليل المؤقت إلى اسم الدليل النهائي.
تعتبر عمليات Rename هذه ذاتية الأصل وسريعة في نظم الملفات مثل HDFS، وهي تضمن المعاملات. ومع ذلك، نظرًا لعدم وجود بنية أساسية للدلائل في تخزين الكائنات، فإن معالجة عملية Rename تكون عملية محاكاة يتضمن الكثير من نسخ البيانات الداخلية. قد تستغرق هذه العملية وقتًا طويلًا ولا توفر مضمون معاملات.
عندما يستخدم المستخدمون تخزين الكائنات، يستخدمون عادة نموذج المسار من الأنظمة الملفات التقليدية كمفتاح للكائنات، مثل “/order/2-22/8/10/detail”. خلال عملية Rename، يصبح من الضروري البحث عن جميع الكائنات التي تحتوي مفاتيحها على اسم الدليل ونسخ جميع الكائنات باستخدام الاسم الجديد للدليل كمفتاح. تتضمن هذه العملية نسخ البيانات، مما يؤدي إلى أداء أقل بشكل كبير مقارنة بنظم الملفات، وربما أبطأ بمرتين أو ثلاث.
بالإضافة إلى ذلك، نظرًا لعدم وجود مضمون معاملات، هناك خطر فشل خلال العملية، مما يؤدي إلى بيانات غير صحيحة. تؤثر هذه الاختلافات الطفيفة على الأداء واستقرار خطوط المهام بأكملها.
عيب رقم 3: آلية التناغم النهائي تؤثر على صحة البيانات واستقرار المهمة
على سبيل المثال، عندما ينشئ عدة مستخدمين بشكل متزامن ملفات تحت مسار، قد لا يشمل قائمة الملفات التي يتم الحصول عليها من خلال واجهة برمجة التطبيقات List جميع الملفات المنشأة على الفور. يستغرق وقتًا لنظام تخزين الكائنات الداخلي لتحقيق تناغم البيانات. يتم استخدام هذا النمط الوصول في معالجة البيانات ETL بشكل شائع، والتناغم النهائي قد يؤثر على صحة البيانات واستقرار المهمة.
لمعالجة مشكلة عدم القدرة على الحفاظ على تناسق دقيق للبيانات في تخزين الأجسام، أصدرت AWS منتجًا يُعرف باسم EMRFS. تتمثل نهجها في استخدام قاعدة بيانات DynamoDB إضافية. على سبيل المثال، عندما يكتب Spark ملفًا، يكتب أيضًا نسخة من قائمة الملفات في DynamoDB في نفس الوقت. ثم يتم إنشاء آلية للاتصال باستمرار بـ List API لتخزين الأشياء ومقارنة النتائج التي تم الحصول عليها مع النتائج المخزنة في قاعدة البيانات حتى تصبح متسقة، عندئذ تُرجع النتائج. ومع ذلك، ليس الاستقرار في هذه الآلية جيدًا بما فيه الكفاية حيث يمكن أن يتأثر بالحمل على المنطقة التي يوجد فيها تخزين الأشياء، مما يؤدي إلى أداء متقلب. وبالتالي، ليس حلًا مثاليًا.
عيب #4: التوافق المحدود مع مكونات Hadoop
كان HDFS هو الخيار الأساسي للتخزين في مراحل البداية لنظام البيانات Hadoop، وتم تطوير مكونات مختلفة بناءً على API HDFS. ظهور تخزين الأشياء أدى إلى تغييرات في بنية التخزين و APIs الخاصة بالبيانات.
تحتاج مزودو الأسماء العادية إلى تعديل موصلات بين المكونات وتخزين الأشياء في الأسماء العادية، وكذلك تصحيح المكونات العلوية لضمان التوافق. هذه المهمة تضع حملًا كبيرًا على مزودي الأسماء العادية.
ونتيجة لذلك، يكون عدد المكونات المداخلة المدعومة في منصات البيانات الكبيرة التي تقدمها الأسماء العادية محدودًا، وعادةً ما يشمل إلى جانب إصدارات قليلة من Spark و Hive و Presto فقط. تشكل هذه القيود تحديات لنقل منصات البيانات الكبيرة إلى الأسماء العادية أو للمستخدمين الذين لديهم متطلبات محددة لتوزيعهم الخاص ومكوناتهم.
للاستفادة من الأداء القوي لتخزين الكائنات مع الحفاظ على موثوقية نظام الملفات، يمكن للشركات استخدام تخزين الكائنات + JuiceFS.
تخزين الكائنات + JuiceFS
عندما يرغب المستخدمون في إجراء حسابات وتحليلات وتدريب معقد على البيانات على تخزين الكائنات، قد لا يكفي تخزين الكائنات وحده لتلبية احتياجات الشركات.هذا هو الدافع الرئيسي وراء تطوير Juicedata لـ JuiceFS، الذي يهدف لتكميل قيود تخزين الكائنات.
JuiceFS هو نظام ملفات موزع عالي الأداء مفتوح المصدر مصمم للغوص في السحابة. بالإضافة إلى تخزين الكائنات، يوفر JuiceFS حلولاً مبتكرة للتكلفة للمواقف الحافلة بالبيانات مثل الحساب والتحليل والتدريب.
كيف يعمل JuiceFS + تخزين الكائنات
يوضح الرسم التوضيحي أدناه توزيع JuiceFS داخل مجموعة Hadoop.
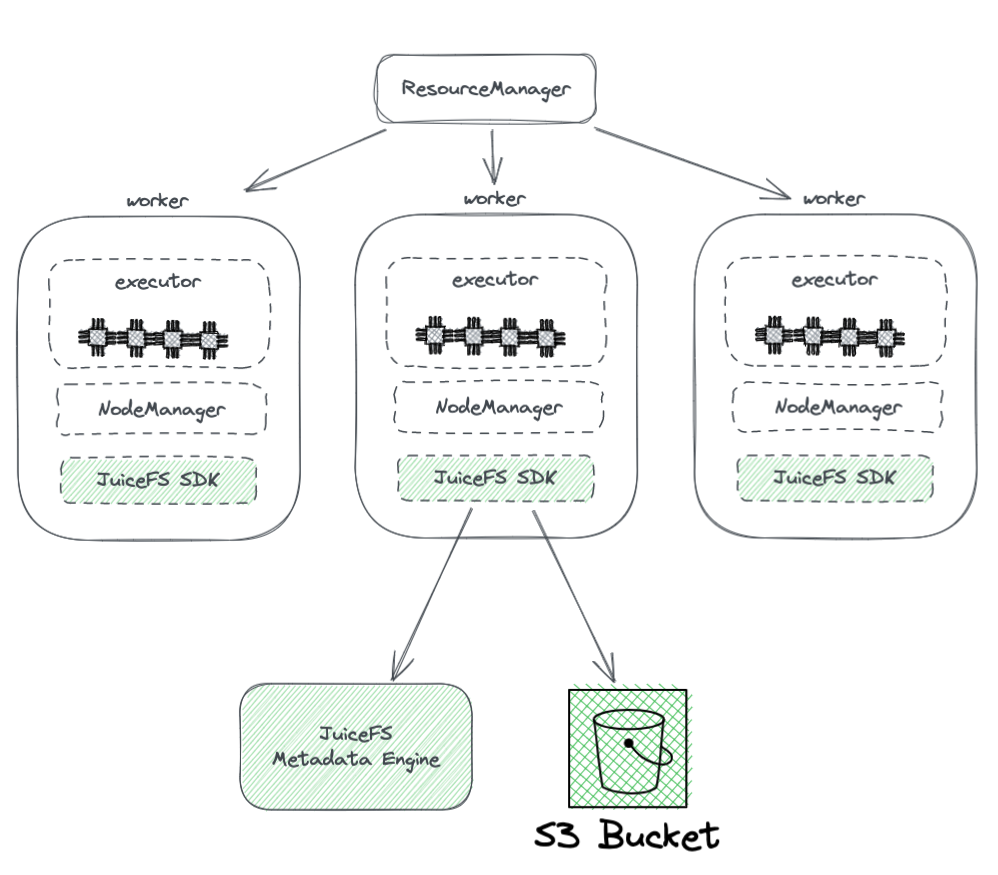
من الرسم، يمكننا رؤية ما يلي:
- كل العقد العاملة التي يديرها YARN يحمل لها SDK لـ JuiceFS لـ Hadoop، الذي يضمن التوافق الكامل مع HDFS.
- الـSDK يستخدم جزئين:
-
محرك بيانات JuiceFS: يعمل محرك البيانات كنظير لعقدة الاسم في HDFS. يخزن معلومات البيانات عن النظام الفارغ بأكمله، بما في ذلك عدد الدلائل، أسماء الملفات، الأذونات، والتوقيت، ويحل مشاكل القابلية للتوسعة والمكافئة النقطية التي تواجه عقدة الاسم في HDFS.
-
حوض S3: تُخزن البيانات داخل حوض S3، والذي يمكن رؤيته مشابهًا لعقدة HDFS. يمكن استخدامه كمجموعة كبيرة من الأقراص، يدير مهام تخزين البيانات والتكرار.
-
-
يتكون JuiceFS من ثلاثة أجزاء:
- مكتبة JuiceFS Hadoop
- محرك البيانات
- حوض S3
مزايا Juicefs على الاستخدام المباشر لتخزين الكائنات
JuiceFS يقدم عدة مزايا مقارنة بالاستخدام المباشر لتخزين الكائنات:
- توافق كامل مع HDFS: هذا متاح من خلال تصميم JuiceFS الأولي لدعم POSIX بالكامل. وAPI POSIX يغطي مجالًا أوسع وتعقيدًا أكبر من HDFS.
- القدرة على الاستخدام مع HDFS وتخزين الكائنات الحاليين: بفضل تصميم نظام Hadoop، يمكن استخدام JuiceFS جنبًا إلى جنب مع أنظمة HDFS وتخزين الكائنات الحالية دون الحاجة إلى استبدال كامل. في مجموعة Hadoop، يمكن تكوين عدة منظمين للملفات، مما يسمح لـ JuiceFS وHDFS بالتعاون والتواجد معًا. هذا التصميم يتجنب الحاجة إلى استبدال كامل لمجموعات HDFS الحالية، والذي ينطوي على جهد ومخاطر كبيرين. يمكن للمستخدمين دمج JuiceFS تدريجيًا بناءً على احتياجات تطبيقاتهم وحالة الخوادم.
- أداء البيانات الوصفية قوي: JuiceFS يفصل محرك البيانات الوصفية عن S3 ولم يعد يعتمد على أداء بيانات S3 الوصفية. هذا يضمن أداء البيانات الوصفية بأفضل شكل. عند استخدام JuiceFS، تبسط التفاعلات مع التخزين الكائني الأساسي إلى عمليات بسيطة مثل Get وPut وDelete. هذا التصميم يتغلب على قيود أداء بيانات التخزين الكائني ويلغي مشكلات التوازن النهائي.
- دعم الإعادة تسمية الذرية: يدعم JuiceFS عمليات الإعادة تسمية الذرية بفضل محرك البيانات الوصفية المستقل. يعزز التخزين المؤقت أداء الوصول إلى البيانات الساخنة ويوفر ميزة الموائع المحلية: مع التخزين المؤقت، لم تعد البيانات الساخنة مطلوبة استردادها من التخزين العنصري عبر الشبكة في كل مرة. علاوة على ذلك، ينفذ JuiceFS API المحلية الخاصة بـ HDFS، بحيث يمكن لجميع المكونات العلوية التي تدعم الموائع المحلية إستعادة وعي التجاذب البيانات. هذا يتيح لـ YARN تفضيل جدولة المهام على العقد التي تم تأسيس التخزين المؤقت عليها، مما يؤدي إلى أداء إجمالي يشبه HDFS المزدوج التخزين-الحساب.
- يتوافق JuiceFS مع POSIX، مما يجعل التكامل مع تطبيقات التعلم الآلي والذكاء الاصطناعي سهلًا.
الخاتمة
مع تطور متطلبات الشركات والتقدم في التقنيات، اجتازت بنية التخزين والحوسبة تغيرات، من الربط إلى الفصل.
هناك طرق متنوعة لتحقيق فصل التخزين والحوسبة، كل منها له مزايا وعيوبها. تتراوح هذه من نشر HDFS إلى السحابة إلى استخدام حلول السحابة العامة التوافقية مع Hadoop وحتى اتباع حلول مثل التخزين العنصري + JuiceFS، والتي تناسب حسابات البيانات الكبيرة المعقدة والتخزين في السحابة.
بالنسبة للشركات، لا يوجد سُمية واحدة، والمفتاح يكمن في اختيار البنية استنادًا إلى احتياجاتها الخاصة. ومع ذلك، بغض النظر عن الخيار، فإن البساطة هي الخيار الآمن دائمًا.
معلومات عن المؤلف
روي سو، شريك في شركة جوسيداتا ، كان عضواً منذ إنشائها يشارك في التطوير الكامل لمنتج JuiceFS وسوقه والمجتمع المفتوح المصدر منذ عام 2017. بعدد 16 عاماً من الخبرة في الصناعة، قام بالأدوار التي تشمل بحوث وتطوير المنتجات ومدير المنتج والمؤسس في البرمجيات والشبكات العنكبوتية والمنظمات غير الحكومية.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora