













في الجزء الأول من هذه السلسلة، نظرنا إلى MongoDB، واحدة من أكثر قواعد البيانات المستندية الـ NoSQL موثوقية وقوة. هنا في
Elasticsearch ليس مجرد قاعدة بيانات موزعة مفتوحة المصدر شائعة وقوية، بل هو أولاً وأخيراً محرك بحث وتحليل. إنه مبنى على رأس Apache Lucene ، أشهر مكتبة بحث Java ، ويمكنه تنفيذ عمليات بحث وتحليل فورية على بيانات منظمة وغير منظمة. إنه مصمم لمعالجة كميات كبيرة من البيانات بكفاءة.
مرة أخرى، نود أن ن澄清 أن هذا المقال القصير لا يمكن أن يكون تلميحاً لتعليم Elasticsearch. وفقًا لذلك، يُشجع القارئ بشدة على استخدام الوثائق الرسمية بشكل واسع، بالإضافة إلى الكتاب الرائع “ Elasticsearch in Action ” لمadhushudhan Konda (Manning، 2023) لمعرفة المزيد عن بنية المنتج وعملياته. هنا، نحن فقط نعيد تنفيذ نفس السيناريو السابق، ولكن هذه المرة باستخدام Elasticsearch بدلاً من MongoDB .
إذن، لنبدأ!
نموذج المجال
يوضح الرسم البياني أدناه نموذج مجالنا customer-order-product :
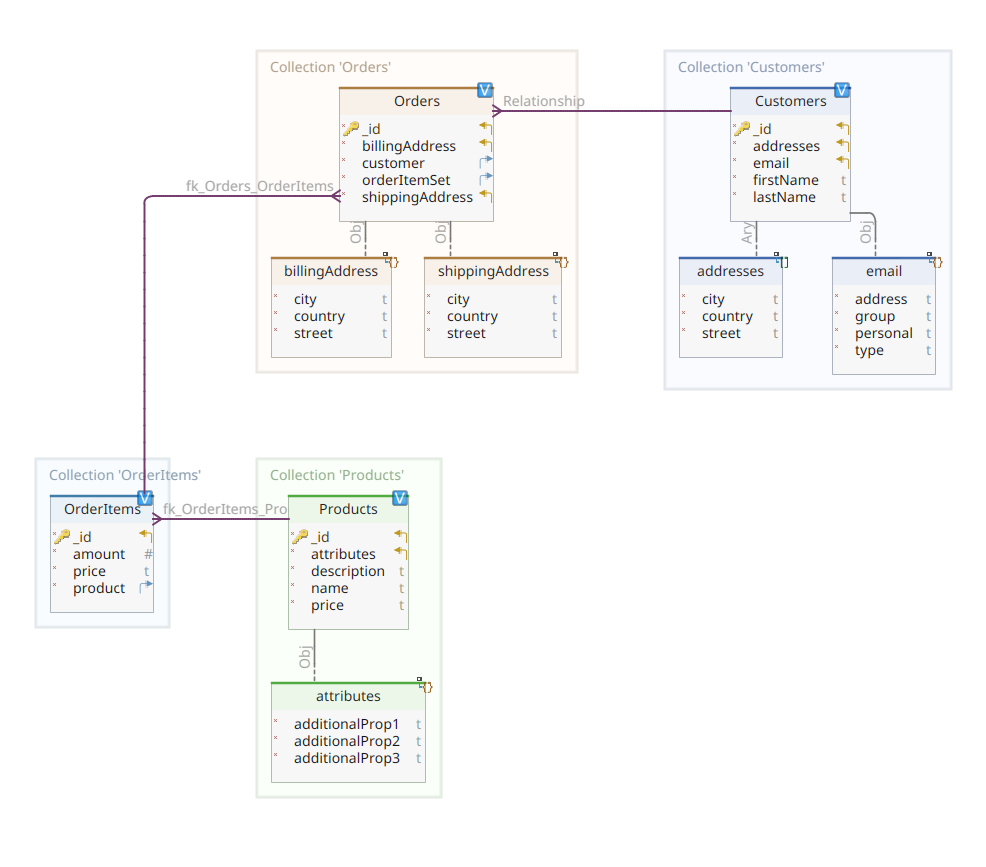
هذا الرسم البياني هو نفسه الذي قدم في الجزء الأول. مثل MongoDB، Elasticsearch هو أيضًا مستودع بيانات الوثائق، وكمثل ذلك، يتوقع أن يتم تقديم الوثائق في صيغة JSON. الاختلاف الوحيد هو أن لمعالجة بياناته، يحتاج Elasticsearch إلى أن يتم فهرسة البيانات.
هناك عدة طرق يمكن من خلالها فهرسة البيانات في مستودع Elasticsearch؛ على سبيل المثال، تمريرها من قاعدة بيانات علاقية، استخراجها من نظام الملفات، تدفقها من مصدر حقيقي الزمن، وما إلى ذلك. ولكن مهما كان طريقة الاستيعاب قد تكون، فإنها تنتهي دائمًا باستدعاء واجهة برمجة تطبيقات Elasticsearch RESTful عبر عميل مخصص. هناك فئتان من هذه العملاء المخصصين:
- عملاء تعتمد على REST مثل
curl،Postman، ووحدات HTTP لـ Java، JavaScript، Node.js، وما إلى ذلك. - حزم تطوير البرمجيات (SDKs): يقدم Elasticsearch حزم تطوير برمجية لجميع اللغات البرمجية الأكثر استخدامًا، بما في ذلك Java، Python، وما إلى ذلك.
فهرسة وثيقة جديدة مع Elasticsearch تعني إنشائها باستخدام طلب POST ضد نهاية واجهة RESTful خاصة تُدعى _doc. على سبيل المثال، الطلب التالي سيقوم بإنشاء فهرس Elasticsearch جديد وتخزين وحدة عميل جديدة فيه.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}تشغيل الطلب السابق باستخدام curl أو وحدة التحكم Kibana (كما سنرى لاحقًا) سينتج النتيجة التالية:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
هذه هي الاستجابة標ية لـ Elasticsearch لطلب POST. تأكید إنشاء الفهرس المسمى customers، وأنشاء مستند جديد customer، معرّفًا بواسطة معرف自动ically مولد (في هذه الحالة، ZEQsJI4BbwDzNcFB0ubC).
تظهر هنا بعض المعلمات المثيرة للاهتمام، مثل _version و_shards خاصةً. بدون الدخول في تفاصيل كثيرة، يخلق Elasticsearch الفهارس كمجموعات منطقية من المستندات. تمامًا مثل الحفاظ على مستندات الورق في خزانة الأرشيف، يحتفظ Elasticsearch بالمستندات في الفهرس. كل فهرس يتكون من شرائح, وهي إصدارات مادية لـ Apache Lucene، المحرك خلف الكواليس المسؤول عن إدخال البيانات أو إخراجها من التخزين. قد تكون إما أساسية، ت�� مستندات، أو نماذج، التي ت��، كما ي暗示 اسمها، نسخ من الشرائح الأساسية. المزيد من ذلك في وثائق Elasticsearch – للآن، نحتاج إلى ملاحظة أن فهرسنا المسمى customers يتكون من شريحتين: إحداهما بالتأكيد أساسية.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
لنعود إلى الرسم البياني لنموذج المجال، كما ترون، المستند المركزي هو Order، المخزن في مجموعة مخصصة تسمى Orders. هو Order هو تجميع لمستندات OrderItem، كل منها يشير إلى المنتج Product المرتبط به. يحدد مستند Order أيضًا العميل Customer الذي قام بإنشائه. في Java، يتم تنفيذ ذلك كالتالي:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
كما يظهر الرمز أعلاه جزء من فئة Customer. هذه فئة بسيطة من POJO (Plain Old Java Object) تحتوي على خصائص مثل معرف العميل، الاسم الأول والاسم الأخير، عنوان البريد الإلكتروني ومجموعة من العناوين البريدية.
دعونا الآن ننظر في وثيقة Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
هنا يمكنك ملاحظة بعض الاختلافات مقارنة بالنسخة MongoDB. في الواقع، باستخدام MongoDB، كنا نستخدم مرجعًا إلى مثيل العميل المرتبط بهذا الطلب. هذه فكرة المرجع لا توجد مع Elasticsearch، وبالتالي نستخدم معرف الوثيقة هذا لإنشاء ارتباط بين الطلب والعميل الذي قدمه. نفس الشيء ينطبق على الخاصية orderItemSet التي تخلق ارتباطًا بين الطلب وitems الخاصة به.
الباقي من نموذج المجال الخاص بنا مشابه جدًا ويعتمد على نفس أفكار الت normalize. على سبيل المثال، وثيقة OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
هنا، نحتاج لربط المنتج الذي يشكل كائن عنصر الطلب الحالي. وأخيرًا، لدينا وثيقة Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}مستودعات البيانات
Quarkus Panache يبسط بشكل كبير عملية الحفاظ على البيانات بدعمه لكل من نموذج السجل النشط و نموذج المستودع. في الجزء الأول، استخدمنا الامتداد Quarkus Panache لـ MongoDB لتنفيذ مستودعات بياناتنا، ولكن لا يوجد حتى الآن امتداد Quarkus Panache tương đương لـ Elasticsearch. ونتيجة لذلك، بانتظار امتداد Quarkus المحتمل للمستقبل لـ Elasticsearch، يجب علينا هنا تنفيذ مستودعات بياناتنا يدويًا باستخدام عميل Elasticsearch المخصص.
Elasticsearch مكتوب بلغة Java، ونتيجة لذلك، ليس من المستغرب أنه يقدم دعمًا natif لاستدعاء واجهة برمجة التطبيقات لـ Elasticsearch باستخدام مكتبة عميل Java. هذه المكتبة تعتمد على نمط تصميم بناء API المتكلم وتقدم نماذج معالجة متزامنة وغير متزامنة. يتطلب Java 8 على الأقل.
إذًا، ما يبدو عليه مستودعات بياناتنا بناءً على بنية API المتكلم؟ فيما يلي جزء من فئة CustomerServiceImpl التي تعمل كمستودع بيانات للـ Customer الوثيقة.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
كما نرى، يجب أن تكون تنفيذية مستودع البيانات لدينا كوية CDI بحجم تطبيق. يتم حقن عميل Elasticsearch ببساطة بفضل الامتداد quarkus-elasticsearch-java-client لـ Quarkus. بهذه الطريقة، نتجنب الكثير من التفاصيل التي كان علينا استخدامها要不. الشيء الوحيد الذي نحتاجه لتتمكن من حقن العمميل هو إعلان الممتلكات التالية:
quarkus.elasticsearch.hosts = elasticsearch:9200هنا، elasticsearch هو اسم DNS (خادم أسماء النطاقات) الذي نربطه مع خادم قاعدة بيانات البحث المتين في ملف docker-compose.yaml. 9200 هو رقم منفذ TCP الذي يستخدمه الخادم للاستماع إلى الاتصالات.
المethode doIndex() في الأعلى يإنشأ فهرسًا جديدًا باسم customers إذا لم يكن موجودًا ويؤشر (يخزن) فيه وثيقة جديدة تمثل مثيلًا من فئة Customer. عملية الفهرسة تتم بناءً على IndexRequest يقبل كأргументات اسم الفهرس وجسم الوثيقة. بالنسبة لمعرف الوثيقة، يتم إنشاؤه آليًا وإرجاعه للمستدعي للإشارة إليه لاحقًا.
الطريقة التالية تتيح استرجاع العميل المعرف بالمعرف المعطى كأргумент إدخال:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
الinciple هو نفسه: باستخدام هذا fluent API نمط بناء المتكلم، ننشئ مثيل GetRequest بطريقة مشابهة لما فعلناه مع IndexRequest، ونقوم بتنفيذه ضد عميل Elasticsearch Java. يتم تصميم باقي نهايات بيانات مستودعنا، التي تتيح لنا تنفيذ عمليات البحث الكامل أو تحديث وحذف العملاء، بنفس الطريقة.
يرجى تخصيص بعض الوقت لمراجعة الكود لفهم كيف تعمل الأمور.
API REST
كان واجهة MongoDB REST API سهلة التنفيذ بفضل توسعة quarkus-mongodb-rest-data-panache، حيث generates المبرمج التوضيحي تلقائيًا جميع النقاط النهائية المطلوبة. مع Elasticsearch، لم نتمتع بعد بالراحة نفسها، وبالتالي، نحتاج إلى تنفيذها يدويًا. هذا ليس مشكلة كبيرة، حيث يمكننا حقن مستودعات البيانات السابقة، كما هو موضح أدناه:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}هذا هو تنفيذ واجهة REST للعميل. الأخرى المرتبطة بالطلبات، عناصر الطلبات، والمنتجات متشابهة.
لنرى الآن كيفية تشغيل اختبار كل شيء.
تشغيل اختبار خدمات الميكرو
الآن بعد أن نظرنا إلى تفاصيل تنفيذنا، لنرى كيفية تشغيله واختباره. اخترنا القيام بذلك نيابة عن أداة docker-compose. إليك الملف المرتبط docker-compose.yml:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
يأمر هذا الملف أداة docker-compose بتشغيل ثلاثة خدمات:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
الآن، يمكنك التحقق من أن جميع العمليات المطلوبة قيد التشغيل:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
لتحديد أن خادم Elasticsearch متاح وقادر على تشغيل الاستعلامات، يمكنك الاتصال بـ Kibana على http://localhost:601. بعد التمرير لأسفل الصفحة واختيار Dev Tools من قائمة التفضيلات، يمكنك تشغيل الاستعلامات كما هو موضح أدناه:
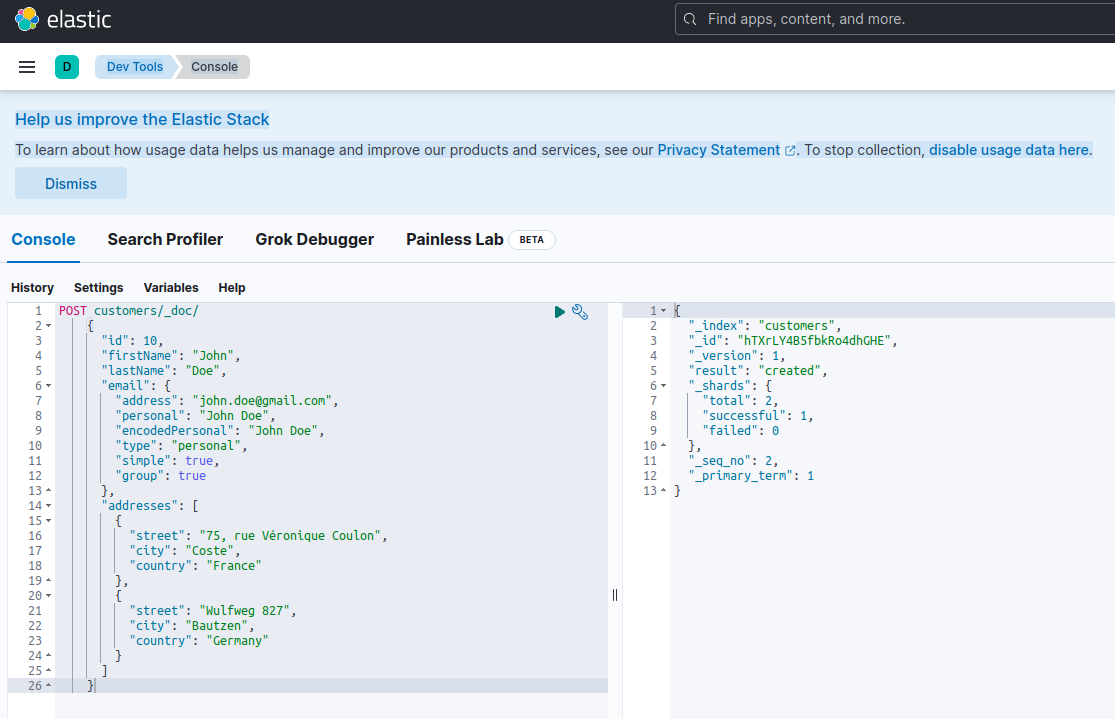
لاختبار خدمات الميكرو، قم بما يلي:
1. انسخ مستودع GitHub المرتبط:
$ git clone https://github.com/nicolasduminil/docstore.git2. انتقل إلى المشروع:
$ cd docstore3. تحقق من الفرع الصحيح:
$ git checkout elastic-search4. بناء:
$ mvn clean install5. تشغيل اختبارات التكامل:
$ mvn -DskipTests=false failsafe:integration-testهذا الأمر الأخير سيعمل اختبارًا integrations الـ 17 المقدمة، وينبغي أن تنجح جميعها. يمكنك أيضًا استخدام واجهة Swagger UI للاختبار من خلال فتح متصفحك المفضل على الرابط http://localhost:8080/q:swagger-ui. ثم، لاختبار نهايات los، يمكنك استخدام الحمولة الموجودة في ملفات JSON الموجودة في دليل src/resources/data لمشروع docstore-api.
تمتع بوقتك!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse