













انتشار الذكاء الاصطناعي العملي قد زاد من الحماس حول الوكلاء الذين يقومون بمهام تلقائية، ويقدمون توصيات، وينفذون تدفقات عمل معقدة تمزج بين الذكاء الاصطناعي والحوسبة التقليدية. ولكن إنشاء مثل هذه الوكلاء في بيئات العمل الحقيقية والمنحى نحو المنتجات يواجه تحديات تتجاوز الذكاء الاصطناعي نفسه.
بدون هندسة معمارية دقيقة، يمكن أن تخلق التبعيات بين المكونات زيادة في العقبات، وتقييد التوسعية، وتعقيد الصيانة مع تطور الأنظمة. الحل يكمن في فك تشابك تدفقات العمل، حيث يتفاعل الوكلاء والبنية التحتية وغيرها من المكونات بسلاسة دون تبعيات صارمة.
هذا النوع من التكامل المرن والقابل للتوسعة يتطلب “لغة” مشتركة لتبادل البيانات – وهي معمارية مدفوعة بتدفقات الأحداث. من خلال تنظيم التطبيقات حول الأحداث، يمكن للوكلاء العمل في نظام مستجيب ومفكك حيث يقوم كل جزء بعمله بشكل مستقل. يمكن للفرق اتخاذ خيارات تكنولوجية بحرية، وإدارة احتياجات التوسع بشكل منفصل، والحفاظ على حدود واضحة بين المكونات، مما يسمح بالتنقل الحقيقي.
لوضع هذه المبادئ على الاختبار، قمت بتطوير PodPrep AI، مساعد البحث الذكي الذي يساعدني على الاستعداد لمقابلات البودكاست على Software Engineering Daily وSoftware Huddle. في هذه المقالة، سأغوص في تصميم وهندسة برمجيات PodPrep AI، موضحًا كيف تدعم معمارية تدفق الأحداث وتبادل البيانات في الوقت الحقيقي نظامًا وكيليًا فعالًا.
ملاحظة: إذا كنت ترغب فقط في النظر إلى الكود، انتقل إلى مستودع GitHub الخاص بي هنا.
لماذا معمارية تدفق الأحداث للذكاء الاصطناعي؟
في تطبيقات الذكاء الاصطناعي في العالم الحقيقي، التصميم الوحدوي الربط لا يكون كافيًا. في حين أن إثباتات المفهوم أو العروض التوضيحية غالبًا ما تستخدم نظامًا واحدًا وموحدًا للبساطة، إلا أن هذا النهج يصبح سريعًا غير عملي في الإنتاج، خاصة في بيئات الانتشار. الأنظمة ذات الربط الثابت تخلق عقبات، وتحد من قابلية التوسع، وتبطئ عمليات التكرار – كلها تحديات حرجة يجب تجنبها مع نمو حلول الذكاء الاصطناعي.
فكر في وكيل الذكاء الاصطناعي النموذجي.
قد يحتاج إلى استخراج البيانات من مصادر متعددة، ومعالجة الاستعلامات وتدفق العمليات المرتبطة بالذكاء الاصطناعي، والتفاعل مباشرة مع مختلف الأدوات لتنفيذ تدفقات العمل المحددة. الأوركسترا ضرورية مع وجود تبعيات على أنظمة متعددة. وإذا كان الوكيل بحاجة للتواصل مع وكلاء آخرين، فإن التعقيد يزداد فقط. بدون بنية مرنة، تجعل هذه التبعيات من الصعب تقريبًا توسيع النطاق وإجراء التعديلات.

في الإنتاج، يتولى فرق مختلفة عادة أجزاء مختلفة من النظام: MLOps وهندسة البيانات يديرون أنابيب RAG، وعلم البيانات يختار النماذج، ومطورو التطبيقات يبنون الواجهة والجزء الخلفي. يجبر الإعداد ذو الارتباط الثابت هذه الفرق على التبعيات التي تبطئ عملية التسليم وتجعل التوسيع أمرًا صعبًا. في الواقع، يجب أن لا تحتاج طبقات التطبيق إلى فهم العمق الداخلي للذكاء الاصطناعي؛ يجب أن تستهلك النتائج عند الحاجة فقط.
وعلاوة على ذلك، لا يمكن لتطبيقات الذكاء الاصطناعي العمل بشكل معزول. بالنسبة للقيمة الحقيقية، تحتاج الرؤى الخاصة بالذكاء الاصطناعي إلى التدفق بسلاسة عبر منصات بيانات العملاء (CDPs)، وأنظمة إدارة علاقات العملاء (CRMs)، وأدوات التحليل، وغيرها. يجب أن تشكل تفاعلات العملاء حافزًا لتحديثات في الوقت الحقيقي، تغذية مباشرة إلى أدوات أخرى للعمل والتحليل. بدون نهج موحد، يصبح تكامل الرؤى عبر المنصات تركيبة صعبة الإدارة ومن المستحيل توسيعها.
يعالج الذكاء الاصطناعي القائم على تحليل البيانات الأحداث هذه التحديات من خلال إنشاء “الجهاز العصبي المركزي” للبيانات. من خلال تحليل البيانات الأحداثية، تبث التطبيقات الأحداث بدلاً من الاعتماد على الأوامر المتسلسلة. يفصل هذا الأمر العناصر المكونة، مما يسمح للبيانات بالتدفق بشكل غير متزامن حيثما يلزم، مما يتيح لكل فريق العمل بشكل مستقل. يعزز تحليل البيانات الحدثية التكامل السلس للبيانات، والنمو القابل للتوسيع، والمرونة — مما يجعله أساسًا قويًا لأنظمة الذكاء الاصطناعي الحديثة.
تصميم وكيل أبحاث مدعوم بالذكاء الاصطناعي القابل للتوسيع
على مدى السنتين الماضيتين، قدمت مئات البودكاست عبر Software Engineering Daily، Software Huddle، وPartially Redacted.
للتحضير لكل بودكاست، أقوم بإجراء عملية بحث شاملة لإعداد موجز بودكاست يحتوي على أفكاري، وخلفية عن الضيف والموضوع، وسلسلة من الأسئلة المحتملة. لبناء هذا الموجز، غالبًا ما أبحث عن الضيف والشركة التي يعملون بها، وأستمع إلى البودكاستات الأخرى التي قد يكونوا ظهروا فيها، وأقرأ مقالات البلوق التي كتبوها، وأقرأ عن الموضوع الرئيسي الذي سنناقشه.
أحاول دمج الروابط مع بودكاستات أخرى قدمتها أو خبرتي الخاصة المتعلقة بالموضوع أو مواضيع مشابهة. تستغرق هذه العملية بأكملها وقتًا وجهدًا كبيرين. تمتلك عمليات البودكاست الكبيرة باحثين ومساعدين مخصصين يقومون بهذا العمل نيابة عن المضيف. لكنني لا أدير هذا النوع من العمليات هنا. يجب أن أفعل كل هذا بنفسي.
لمعالجة هذا، أردت إنشاء وكيل يمكنه القيام بهذا العمل من أجلي. على مستوى عالٍ، سيبدو الوكيل مثل الصورة أدناه.

أقدم مواد مصدر أساسية مثل اسم الضيف، الشركة، المواضيع التي أريد التركيز عليها، بعض روابط المرجع مثل المقالات والمدونات والبودكاستات الموجودة، ثم تحدث بعض السحر باستخدام الذكاء الاصطناعي، وتكتمل أبحاثي.
قادتني هذه الفكرة البسيطة لإنشاء PodPrep AI، مساعدي البحث المدعوم بالذكاء الاصطناعي الذي يكلفني فقط رموزًا.
تناقش بقية هذه المقالة تصميم PodPrep AI، بدءًا من واجهة المستخدم.
بناء واجهة مستخدم الوكيل
صممت واجهة الوكيل كتطبيق ويب حيث يمكنني بسهولة إدخال مواد المصدر لعملية البحث. يتضمن ذلك اسم الضيف، شركته، موضوع المقابلة، أي سياق إضافي، وروابط إلى المدونات والمواقع ذات الصلة، ومقابلات البودكاست السابقة.
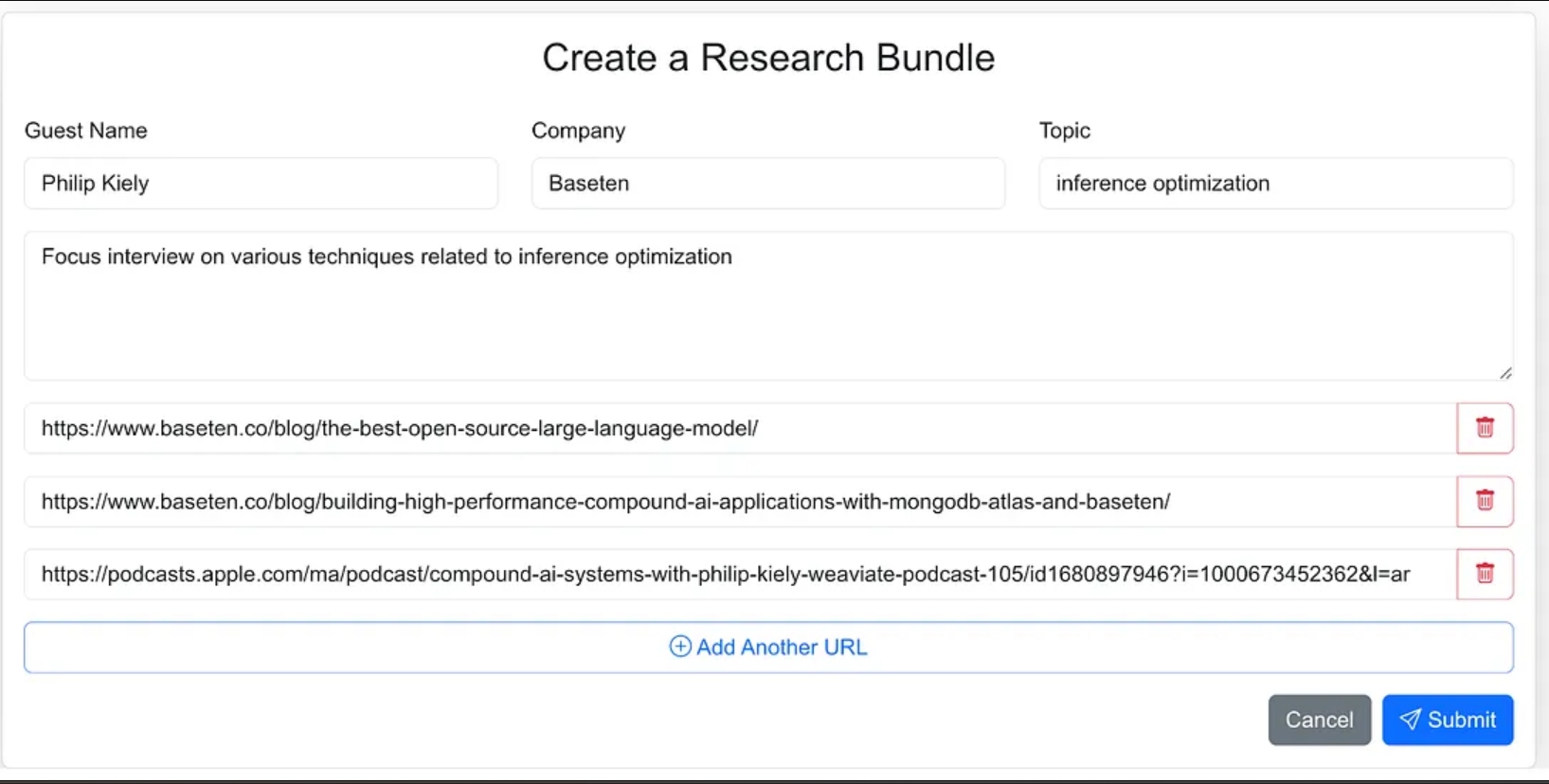
كان بإمكاني إعطاء الوكيل توجيهًا أقل وكجزء من سير العمل الخاص بالوكيل أن يذهب للعثور على مواد المصدر، لكنني قررت في النسخة 1.0 أن أقدم روابط المصدر.
تطبيق الويب هو تطبيق معياري من ثلاث طبقات تم بناؤه باستخدام نكست.جس و مونجو دي بي لقاعدة بيانات التطبيق. لا يعرف شيئًا عن الذكاء الاصطناعي. ببساطة، يسمح للمستخدم بإدخال حزم بحث جديدة وتظهر هذه في حالة معالجة حتى يكمل العملية الوكالية سير العمل ويملأ ملخص بحث في قاعدة بيانات التطبيق.
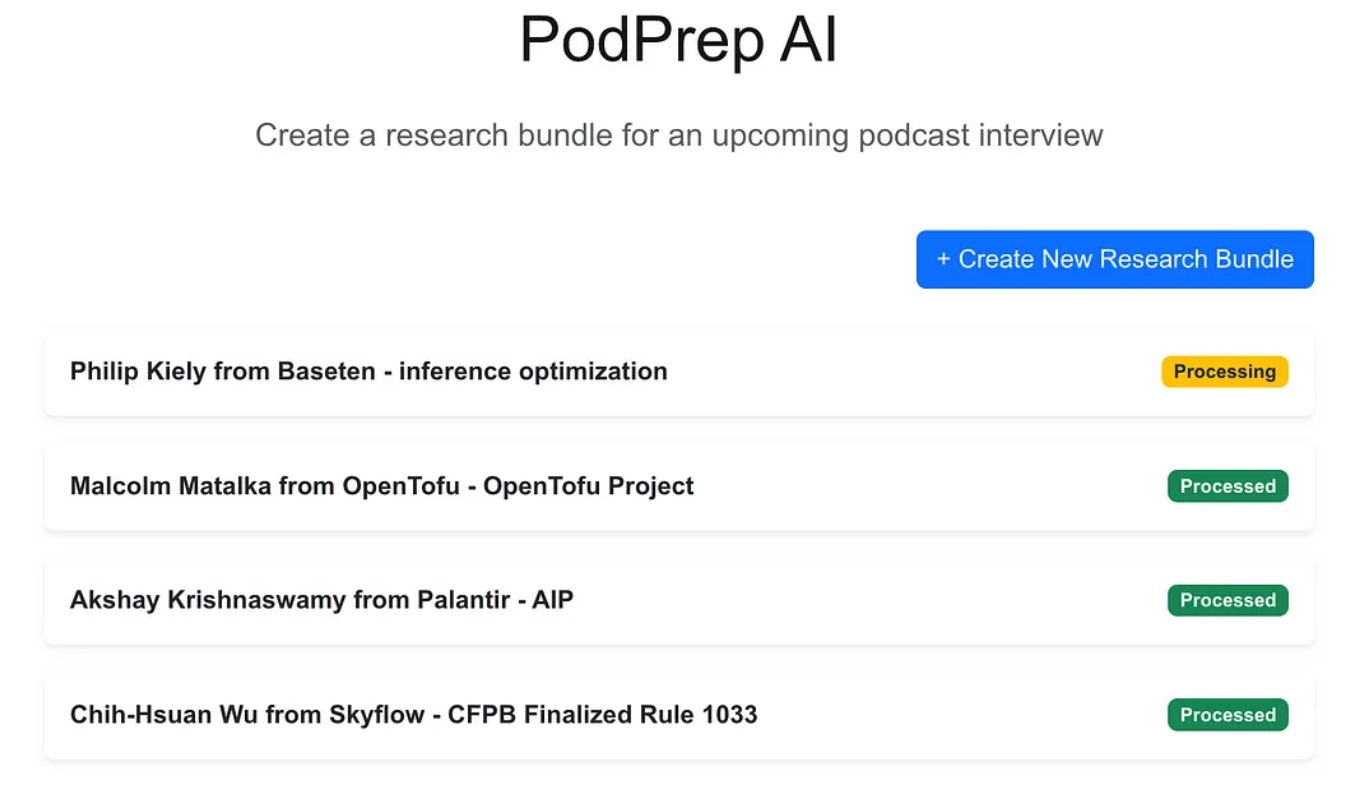
بمجرد اكتمال السحر الذكي، يمكنني الوصول إلى وثيقة تعريفية للإدخال كما هو موضح أدناه.

إنشاء سير العمل الوكالي
للإصدار 1.0، أردت أن أكون قادرًا على تنفيذ ثلاث إجراءات أساسية لبناء ملخص البحث:
- لأي عنوان موقع ويب أو مدونة أو بودكاست، احصل على النص أو الملخص، قسم النص إلى أحجام معقولة، وقم بإنشاء تضمينات، وقم بتخزين التمثيل البياني.
- لجميع النصوص المستخرجة من عناوين مصادر البحث، اسحب الأسئلة الأكثر إثارة للاهتمام، وقم بتخزينها.
- إنشاء ملخص بحث عن البودكاست يجمع بين السياق الأكثر صلة بناءً على التضمينات، أفضل الأسئلة التي تم طرحها سابقًا، وأي معلومات أخرى كانت جزءًا من إدخال الحزمة.
توضح الصورة أدناه الهندسة المعمارية من تطبيق الويب إلى سير العمل الوكالي.
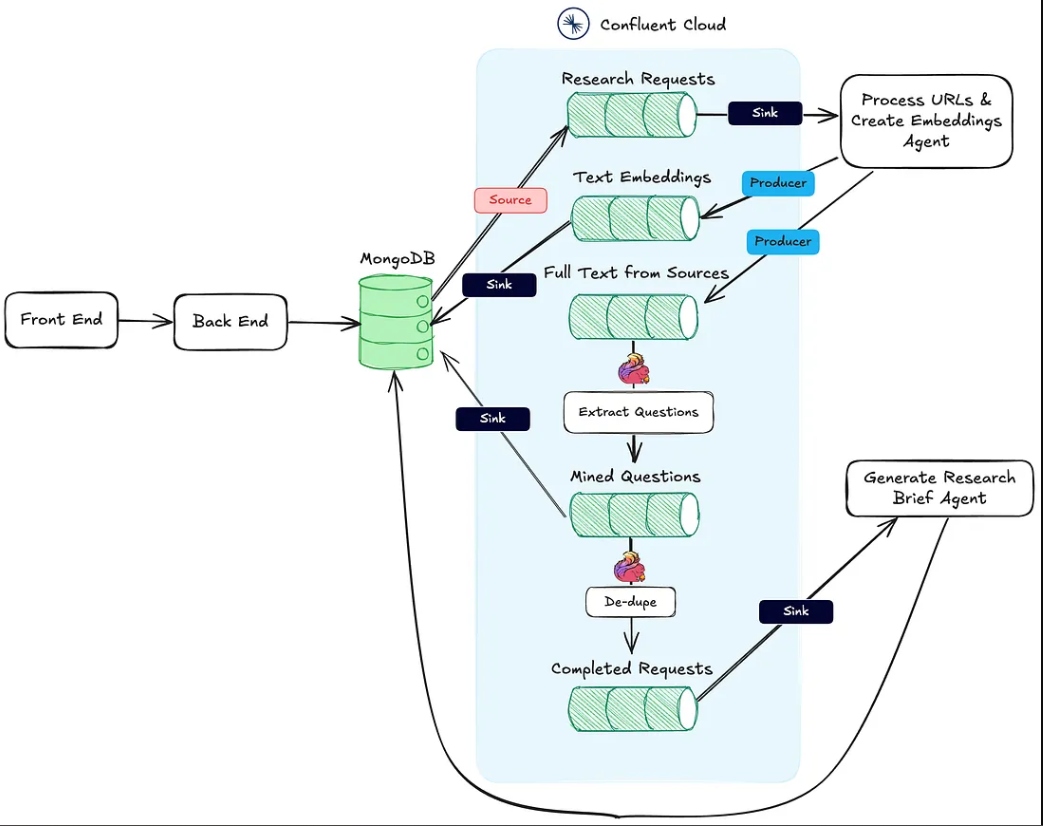
الإجراء رقم 1 أعلاه مدعوم بواسطة نقطة النهاية HTTP Process URLs & Create Embeddings Agent.
يتم تنفيذ الإجراء رقم 2 باستخدام Flink ودعم النموذج الذكي المدمج في Confluent Cloud.
أخيرًا، يتم تنفيذ الإجراء رقم ٣ بواسطة وكيل إنشاء ملخص البحث ، وهو أيضًا نقطة نهاية HTTP للاستقبال، والتي يتم استدعاؤها بمجرد اكتمال الإجراءات الأولى.
في الأقسام التالية، سأناقش كل من هذه الإجراءات بالتفصيل.
وكيل معالجة عناوين URL وإنشاء تضمينات
يتحمل هذا الوكيل مسؤولية استخراج النص من عناوين مصادر البحث وخط أنابيب تضمين الناقلات. فيما يلي سير العمل على مستوى عالٍ لما يحدث خلف الكواليس لمعالجة المواد البحثية.

بمجرد إنشاء مجموعة بحث من قبل المستخدم وحفظها في MongoDB، ينتج موصل المصدر من MongoDB رسائل إلى موضوع Kafka المسمى research-requests. هذا هو ما يبدأ سير العمل الوكالي.
كل طلب منشور إلى نقطة النهاية HTTP يحتوي على عناوين URL من طلب البحث والمفتاح الرئيسي في مجموعة حزم البحث في MongoDB.
العميل يكرر عبر كل عنوان URL وإذا لم يكن بودكاست Apple، يسترد النص الكامل للصفحة HTML. نظرًا لعدم معرفتي ببنية الصفحة، لا يمكنني الاعتماد على مكتبات تحليل HTML للعثور على النص المتعلق. بدلاً من ذلك، أرسل النص الخاص بالصفحة إلى نموذج gpt-4o-mini مع درجة حرارة صفر باستخدام الاستفزاز أدناه للحصول على ما أحتاج إليه.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
بالنسبة للبودكاست، تحتاج إلى بذل جهد إضافي.
عكس هندسة عناوين بودكاست Apple
لاستخراج البيانات من حلقات البودكاست، نحتاج أولاً إلى تحويل الصوت إلى نص باستخدام نموذج Whisper. ولكن قبل أن نتمكن من ذلك، علينا تحديد الملف MP3 الفعلي لكل حلقة من حلقات البودكاست، وتنزيله، وتقسيمه إلى قطع بحجم 25 ميغابايت أو أقل (أقصى حجم لـ Whisper).
التحدي هو أن Apple لا توفر رابط MP3 مباشرًا لحلقات بودكاستها. ومع ذلك، يتوفر ملف MP3 في تغذية RSS الأصلية للبودكاست، ويمكننا العثور على هذه التغذية برمجيًا باستخدام معرف بودكاست Apple.
على سبيل المثال، في الرابط أدناه، الجزء الرقمي بعد /id هو معرف بودكاست Apple الفريد:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
باستخدام واجهة برمجة تطبيقات Apple، يمكننا البحث عن معرف البودكاست واسترداد استجابة JSON تحتوي على رابط التغذية RSS:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
بمجرد الحصول على تغذية RSS XML، نقوم بالبحث فيها عن الحلقة المحددة. نظرًا لأن لدينا فقط رابط الحلقة من Apple (وليس العنوان الفعلي)، نستخدم عنوان الحلقة من رابط URL لتحديد موقع الحلقة داخل التغذية واسترداد رابط MP3 الخاص بها.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
الآن مع النصوص من مشاركات المدونات والمواقع وملفات MP3 المتاحة، يستخدم الوكيل مُقسِّم نصوص الأحرف العائد من LangChain لتقسيم النص إلى شظايا وتوليد التضمينات من هذه الشظايا. يتم نشر الشظايا إلى موضوع text-embeddings وإغراقها إلى MongoDB.
- ملاحظة: اخترت استخدام MongoDB كقاعدة بيانات لتطبيقي وقاعدة بيانات للفيكتور. ومع ذلك، بسبب النهج الذي اتبعته في EDA، يمكن أن تكون هذه أنظمة مستقلة بسهولة، وهو مجرد مسألة تبديل موصل الاستجابة من موضوع Text Embeddings.
بالإضافة إلى إنشاء ونشر التضمينات، يقوم الوكيل أيضًا بنشر النصوص من المصادر إلى موضوع يسمى full-text-from-sources. يبدأ نشر هذا الموضوع بتنفيذ الإجراء رقم 2.
استخراج الأسئلة باستخدام Flink و OpenAI
أباتشي فلينك هو إطار عمل مفتوح المصدر لمعالجة التدفقات الحية والمبني للتعامل مع كميات كبيرة من البيانات في الوقت الحقيقي، وهو مثالي لتطبيقات عالية الإنتاجية ومنخفضة الكمالية. من خلال ربط Flink بـ Confluent، يمكننا جلب نماذج لغة طويلة المدى مثل GPT من OpenAI مباشرةً إلى سير العمل التدفقي. يمكن لهذا التكامل تمكين سير العمل RAG في الوقت الحقيقي، مضمنًا أن عملية استخراج الأسئلة تعمل بأحدث البيانات المتاحة.
وجود النص الأصلي من المصدر في التدفق يتيح لنا أيضًا إدخال سير عمل جديدة لاحقًا تستخدم نفس البيانات، مما يعزز عملية إنشاء الملخصات البحثية أو إرسالها إلى خدمات تالية مثل مستودع بيانات. تسمح هذه الإعدادات المرنة لنا بتضمين ميزات AI وغير AI بمرور الوقت دون الحاجة إلى إعادة هيكلة الأنبوب الأساسي.
في PodPrep AI، أستخدم Flink لاستخراج الأسئلة من النصوص المستخرجة من عناوين URL المصدرية.
إعداد Flink لاستدعاء نموذج لغة طويلة المدى يتضمن تكوين اتصال من خلال واجهة سطر الأوامر الخاصة بـ Confluent. فيما يلي مثال لأمر لإعداد اتصال بـ OpenAI، ولكن هناك خيارات متعددة متوفرة.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
بمجرد تأسيس الاتصال، يمكنني إنشاء نموذج في واجهة التحكم السحابية أو سطر Flink SQL. لاستخراج الأسئلة، أعددت النموذج وفقًا لذلك.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
مع النموذج جاهزًا، أستخدم وظيفة ml_predict المدمجة في Flink لتوليد الأسئلة من المصدر، وأكتب الناتج إلى تيار يُسمى mined-questions، الذي يتزامن مع MongoDB للاستخدام لاحقًا.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
تساعد Flink أيضًا في تتبع متى تم معالجة جميع مواد البحث، مشغلة إنشاء ملخص البحث. يتم ذلك عن طريق كتابة إلى تيار completed-requests بمجرد أن تتطابق عناوين URL في mined-questions مع تلك في تيار مصادر النصوص الكاملة.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
مع كتابة الرسائل إلى completed-requests، يتم إرسال معرف فريد لحزمة البحث إلى وكيل إنشاء ملخص البحث.
وكيل إنشاء ملخص البحث
يأخذ هذا الوكيل جميع المواد البحثية الأكثر صلة المتاحة ويستخدم LLM لإنشاء ملخص بحثي. أدناه تفاصيل عملية إنشاء ملخص بحث.

مخطط تدفق لوكيل إنشاء ملخص البحث
لنقسم بعض هذه الخطوات. لبناء الدعوة لـ LLM، أجمع الأسئلة المستخرجة، والموضوع، واسم الضيف، واسم الشركة، ودليل النظام للتوجيه، والسياق المخزن في قاعدة البيانات الناقلة الذي يتماثل في المعنى إلى أكبر درجة ممكنة مع موضوع البودكاست.
بسبب أن حزمة البحث تحتوي على معلومات سياقية محدودة، فإنه من الصعب استخراج السياق الأكثر صلة مباشرة من متجر المتجهات. لمعالجة ذلك، قمت بجعل LLM يولد استعلام بحث لتحديد المحتوى الأكثر تطابقًا، كما هو موضح في عقدة “إنشاء استعلام بحث” في الرسم البياني.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
باستخدام الاستعلام الذي تم إنشاؤه بواسطة LLM، أنشأت تمثيلًا وبحثت في MongoDB من خلال فهرس المتجهات، مع تصفية بواسطة bundleId لتحديد البحث في المواد ذات الصلة بالبودكاست المحدد.
مع تحديد أفضل معلومات سياقية، قمت ببناء موجه وتوليد موجز البحث، وحفظت النتيجة في MongoDB لعرضها في تطبيق الويب.
أشياء يجب ملاحظتها حول التنفيذ
كتبت كل من تطبيق الواجهة الأمامية لـ PodPrep AI والوكلاء بلغة Javascript، ولكن في سيناريو العالم الحقيقي، من المحتمل أن يكون الوكيل بلغة مختلفة مثل بايثون. بالإضافة إلى ذلك، من أجل البساطة، فإن كل من وكيل معالجة عناوين URL وإنشاء التمثيلات و وكيل توليد موجز البحث موجودان ضمن نفس المشروع الذي يعمل على نفس خادم الويب. في نظام الإنتاج الحقيقي، يمكن أن تكون هذه وظائف خالية من الخادم، تعمل بشكل مستقل.
أفكار أخيرة
بناء تطبيق PodPrep AI يسلط الضوء على كيفية تمكين الهندسة المعمارية المدفوعة بالأحداث تطبيقات الذكاء الاصطناعي في العالم الحقيقي من التوسع والتكيف بسلاسة. باستخدام Flink و Confluent، قمت بإنشاء نظام يعالج البيانات في الوقت الحقيقي، مما يدعم سير عمل مدفوع بالذكاء الاصطناعي بدون تبعيات صارمة. يسمح هذا النهج المنفصل للمكونات بالعمل بشكل مستقل، ولكن يبقى متصلاً من خلال تيارات الأحداث – الأمر الأساسي لتطبيقات معقدة موزعة حيث تدير فرق مختلفة أجزاء مختلفة من النظام.
في بيئة الذكاء الاصطناعي الحالية، الوصول إلى البيانات الحديثة في الوقت الحقيقي عبر الأنظمة أمر أساسي. تعتبر الهندسة المعمارية المدفوعة بالأحداث “الجهاز العصبي المركزي” للبيانات، مما يتيح التكامل السلس والمرونة مع توسيع النظام.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink