













كل منظمة تعتمد على البيانات لديها حمولات تشغيلية وتحليلية. يبرز نهج الأفضل في فئة واحدة مع منصات بيانات متعددة، بما في ذلك بث البيانات، بحيرة البيانات، مخزن البيانات وحلول بحيرة المخزن، وخدمات السحابة. تشكل إطار عمل تنسيق الجداول المفتوح مثل Apache Iceberg عنصرًا أساسيًا في架构 المؤسسة لضمان إدارة البيانات ومشاركتها الموثوقة،和无缝 تطور النموذج، ومعالجة مجموعات البيانات الكبيرة بفعالية، وتخزين فعال من حيث التكلفة، و تقدم دعمًا قويًا لمعاملات ACID استعلامات السفر عبر الزمن.
يتناول هذا المقال الاتجاهات السوقية; تبني إطار عمل تنسيقات الجداول مثل Iceberg، Hudi، Paimon، Delta Lake، و XTable; وстратегية المنتج لبعض الشركات الرائدة في منصات البيانات مثل Snowflake، Databricks (Apache Spark)، Confluent (Apache Kafka/Flink)، Amazon Athena، و Google BigQuery.
ما هو تنسيق الجداول المفتوح لمنصة البيانات؟
يساعد تنسيق الجداول المفتوح في الحفاظ على سلامة البيانات، وتحسين أداء الاستعلامات، وضمان فهم واضح للبيانات المخزنة داخل المنصة.
يتضمن تنسيق الجداول المفتوح لمنصات البيانات عادةً هيكلًا محددًا جيدًا مع مكونات محددة تضمن أن البيانات منظمة، قابلة للوصول، وسهلة الاستعلام عنها. يحتوي التنسيق المعتاد للجدول على اسم الجدول، أسماء الأعمدة، أنواع البيانات، المفاتيح الأساسية والغريبة، الفهارس، والقيود.
هذا ليس مفهوماً جديداً. قاعدة بياناتك المفضلة التي تبلغ عقوداً من الزمن — مثل أوراكل، آي بي إم دي بي2 (حتى على الحاسوب الرئيسي) أو PostgreSQL — تستخدم نفس المبادئ. ومع ذلك، قد تغيرت متطلبات التحديات قليلاً للمراكز البيانية السحابية، البحيرات البيانية ومحطات البحيرات البيانية فيما يتعلق بالقابلية للتوسع، الأداء وقدرات الاستعلام.
فوائد تنسيق “جدول البحيرة البيانية” مثل Apache Iceberg
كل جزء من المنظمة يصبح مدفوعاً بالبيانات. والنتيجة هي مجموعات بيانات واسعة، ومشاركة البيانات مع منتجات البيانات عبر وحدات الأعمال، ومتطلبات جديدة لمعالجة البيانات تقريباً في الوقت الحقيقي.
يقدم Apache Iceberg العديد من الفوائد لتصميم البنية التحتية للشركة:
- ��ية واحدة: يتم تخزين البيانات مرة واحدة (قادمة من مصادر بيانات مختلفة)، مما يقلل من التكلفة والتعقيد
- التوافقية: الدخول دون جهود التكامل من أي محرك تحليلي
- كل البيانات: توحيد الأحمال العملية والتحليلية (نظام التعاملات، سجلات البيانات الكبيرة/الإنترنت الأشياء/تدفقات النقر، واجهات برمجة التطبيقات المحمولة، واجهات B2B الثالثة، إلخ)
- الاستقلالية عن المورد: العمل مع أي محرك تحليلي مفضل (بغض النظر عما إذا كان في الوقت الحقيقي، دفعي أو يعتمد على واجهة برمجة التطبيقات)
تقدم Apache Hudi و Delta Lake نفس الخصائص. ومع ذلك، يتم تشغيل Delta Lake بشكل رئيسي من قبل Databricks كveedor واحد.
تنسيق الجدول وواجهة الكتالوج
من المهم فهم أن المناقشات حول Apache Iceberg أو إطار عمل تنسيق الجداول المشابهة تشمل Concepts وأ واجهة الكتالوج! كمسخدم نهائي لتقنية التكنولوجيا، أنت بحاجة إلى كليهما!
مشروع Apache Iceberg يطبق التنسيق، ولكن يقدم فقط وصفًا (لكن ليس تنفيذًا) للكتالوج:
- يحدد تنسيق الجدول كيفية تنظيم البيانات وتخزينها وإدارتها داخل الجدول.
- تتعامل واجهة الكتالوج مع بيانات الفهارس للجداول وتقدم طبقة تحويلية للوصول إلى الجداول في بحيرة البيانات.
توثيق Apache Iceberg يexplore المفاهيم بتفاصيل أكثر، بناءً على هذا الرسم البياني:
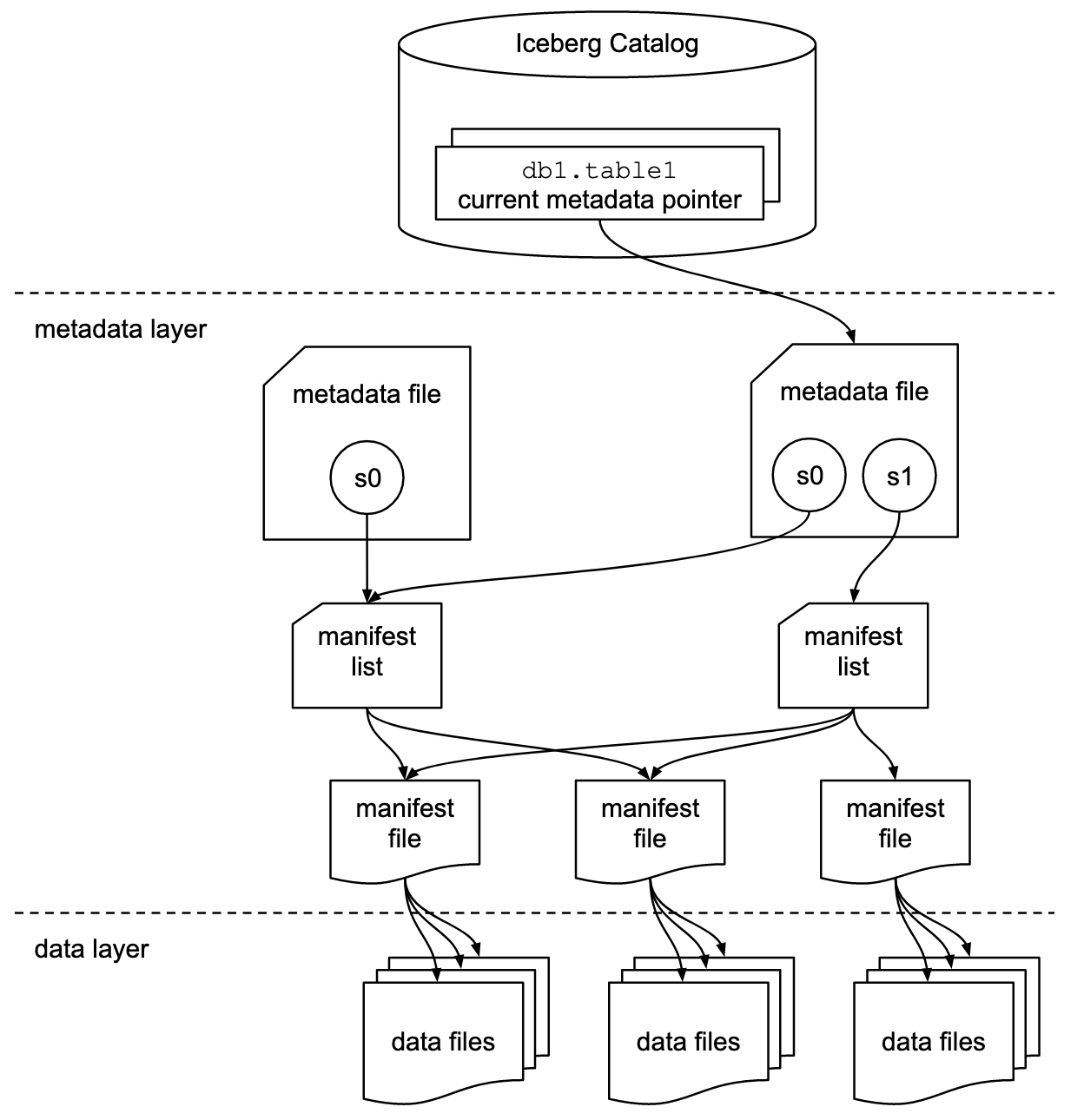
تستخدم المنظمات تنفيذيات مختلفة لواجهة كتالوج Iceberg. يدمج كل منها مع مستودعات وخدمات metadata مختلفة. التطبيقات الرئيسية تشمل:
- كتالوج Hadoop: يستخدم نظام ملفات توزيع Hadoop (HDFS) أو أنظمة ملفات أخرى متوافقة لتخزين Metadata. مناسب للبيئات التي تستخدم Hadoop بالفعل.
- كتالوج Hive: يدمج مع Apache Hive Metastore لإدارة metadata الجداول. مثالي للمستخدمين الذين يستخدمون Hive لإدارة metadata.
- كتالوج AWS Glue: يستخدم AWS Glue Data Catalog لتخزين Metadata. مصمم للمستخدمين الذين يعملون داخل بيئة AWS.
- كatalog REST: يقدم واجهة RESTful لعمليات الكatalog عبر HTTP. يتيح التكامل مع خدمات metadata مخصصة أو من الجهات الثالثة.
- كatalog Nessie: يستخدم مشروع Nessie، الذي يقدم تجربة مشابهة لـ Git لإدارة البيانات.
الزخم والاعتماد المتزايد على Apache Iceberg ي动机 العديد من بائعي منصات البيانات لتنفيذ كatalog Iceberg الخاص بهم. أنا أتحدث عن بعض الاستراتيجيات في القسم أدناه عن استراتيجيات منصات البيانات ومقدمي الخدمات السحابية، بما في ذلك Polaris الخاص بـ Snowflake، وUnity الخاص بـ Databricks، وTableflow الخاص بـ Confluent.
دعم Iceberg من الدرجة الأولى مقابل مكون اتصال Iceberg
يرجى ملاحظة أن دعم Apache Iceberg (أو Hudi/Delta Lake) يعني أكثر بكثير من مجرد توفير مكون اتصال وتكامل مع تنسيق الجداول عبر API. يختلف بائعو الخدمات السحابية من خلال ميزات متقدمة مثل\Mapping التلقائي بين تنسيقات البيانات، SLAs الحرجة، العودة إلى الوراء في الزمن، واجهات مستخدم بديهية، وما إلى ذلك.
لنأخذ مثالاً: التكامل بين Apache Kafka وIceberg. تم بالفعل تنفيذ عدة مكونات اتصال Kafka Connect. ومع ذلك، إليك الفوائد من استخدام تكامل من الدرجة الأولى مع Iceberg (مثلاً Tableflow الخاص بـ Confluent) مقارنة بمجرد استخدام مكون اتصال Kafka Connect:
- لا حاجة لتهيئة مكون الاتصال
- لا استهلاك من خلال مكون الاتصال
- صيانة مدمجة (ت compact، تنظيف القمامة، إدارة اللقطات)
- تطور النموذج التلقائي
- تنسيق خدمة الكatalog الخارجية
- عمليات أبسط (في حل Saas مدارة كاملة، هي بدون خادم دون الحاجة إلى أي تدرج أو عمليات من قبل المستخدم النهائي)
تطبق نفس الفوائد على منصات بيانات أخرى وتكامل أول درجة محتمل مقارنة بتوفير موصلات بسيطة.
تنسيق جداول مفتوح لبحيرة البيانات/منزل البيانات باستخدام Apache Iceberg، Apache Hudi، وDelta Lake
الهدف العام لإطار عمل تنسيقات الجداول مثل Apache Iceberg، Apache Hudi، وDelta Lake هو تحسين وظائف وموثوقية بحيرات البيانات من خلال معالجة التحديات الشائعة المرتبطة إدارة بيانات على نطاق واسع. هذه الإطار تساعد في:
- تحسين إدارة البيانات
- تسهيل التعامل مع استقبال البيانات، التخزين، واسترجاعها في بحيرات البيانات.
- تمكين تنظيم وتخزين بيانات فعال، داعم أداءً أفضل وقياسًا.
- ضمان توافق البيانات
- توفير آليات لتحويلات ACID، ضمان أن تبقى البيانات متوافقة وموثوقة حتى أثناء عمليات القراءة والكتابة المتزامنة.
- دعم عزلة اللقطات، السماح للمستخدمين برؤية حالة بيانات متوافقة في أي نقطة زمنية.
- يدعم تطور النموذج
- permits changes to the data schema (such as adding, renaming, or removing columns) without disrupting existing data or requiring complex migrations.
- تحسين أداء الاستعلامات
- يطبق استراتيجيات متقدمة لل索indexing و partitioning لتحسين سرعة وكفاءة استعلامات البيانات.
- يتمكّن من إدارة فعالة للمetadata لمعالجة مجموعات البيانات الكبيرة والاستعلامات المعقدة بفعالية.
- تعزيز حكم البيانات
- يوفر أدوات لتحسين تتبع وإدارة سلسلة البيانات، وإدارة الإصدارات، والمراجعة، وهي أمر حاسم ل维持 جودة البيانات والامتثال.
ب trattin هؤلاء الأهداف، إطار العمل 格式 الجداول مثل Apache Iceberg، Apache Hudi، و Delta Lake يساعد المنظمات في بناء مستودعات بيانات وأماكن مستودعات أكثر قوة، قابلة للتوسع، و يمكن الاعتماد عليها. يستفيد مهندسو البيانات، علماء البيانات، و محللو الأعمال من أدوات التحليل، الذكاء الاصطناعي/التعلم الآلي، أو الأدوات الإبلاغية/التصويرية فوق تنسيق الجدول لتحكم وإدارة كتل بيانات ضخمة.
مقارنة بين Apache Iceberg، Hudi، Paimon، و Delta Lake
لن أقوم بمقارنة إطار العمل تنسيق الجدول Apache Iceberg، Apache Hudi، Apache Paimon، و Delta Lake هنا. العديد من الخبراء كتبوا عن هذا بالفعل. يمتلك كل إطار عمل تنسيق الجدول قوة فريدة و منافع. لكن يتم إجراء التحديثات شهريًا بسبب التطور السريع و الابتكار، إضافة تحسينات و قدرات جديدة داخل هذه الأطر.
إليك ملخص مما أراه في مقالات博客 المختلفة حول الخيارات الأربع:
- Apache Iceberg: يبرع في تطور النموذج و التقسيم، إدارة فعالة للبيانات، و توافق واسع مع محركات معالجة البيانات المختلفة.
- Apache Hudi: الأنسب لاستيعاب البيانات الفعلية و تحديثاتها، بقدرات قوية في التقاط بيانات التغيير و إدارة إصدارات البيانات.
- Apache Paimon: تنسيق مستودع يتيح بناء بنية مستودع فوري باستخدام Flink و Spark لكل من العمليات الجارية و الكتلة.
- Delta Lake: يقدم معاملات ACID قوية، فرض النموذج، و ميزات السفر الزمني، مما يجعله مثاليًا ل维持 جودة و نزاهة البيانات.
نقطة اتخاذ القرار الرئيسية قد تكون أن بحيرة دلتا ليست مدفوعة بمجتمع واسع مثل Iceberg و Hudi، بل主要由 Databricks كمورد单一供应商支持.
Apache XTable كإطار عمل متوافق بين الجداول الداعم لـ Iceberg، Hudi، وبحيرة دلتا
للمستخدمين有很多选择. XTable، والذي كان يعرف سابقاً باسم OneTable، هو إطار عمل آخر للجداول تحت الترسيم في ترخيص Apache المفتوح المصدر للتفاعل بشكل سلس بين الجداول عبر Apache Hudi، وبحيرة دلتا، و Apache Iceberg.
Apache XTable:
- يقدم التوافق الرباعي بين الجداول بين تنسيقات جداول البيت湖水.
- هو ليس تنسيقًا جديدًا أو منفصلًا. يقدم Apache XTable تجريدات وأدوات لترجمة بيانات تنسيقات جداول البيت湖水.
ربما يكون Apache XTable هو الجواب لتقديم خيارات لمنصات بيانات محددة ومقدمي خدمات السحابة بينما يقدم في نفس الوقت تكاملًا و توافقًا بسيطًا.
لكن كن حذراً: Wrapper على قمة تقنيات مختلفة ليس حلاً سحرياً. رأينا هذا قبل سنوات عندما ظهر Apache Beam. Apache Beam هو نموذج مفتوح المصدر موحد و مجموعة من SDKs الخاصة بلغات معينة لتحديد تنفيذ إجراءات استقبال البيانات ومعالجتها. يدعم مجموعة متنوعة من محركات معالجة التدفقات مثل Flink، و Spark، و Samza. السبب الرئيسي وراء Apache Beam هو Google، الذي يسمح بنقل التدفقات في Google Cloud Dataflow. ومع ذلك، فإن القيود كبيرة، حيث يحتاج مثل هذا_WRAPPER ليجد الحد الأدنى المشترك من الميزات المدعومة. وغالبياً ميزة المظاهر الرئيسية هي الـ 20% التي لا تتناسب مع مثل هذا Wrapper. لذا، على سبيل المثال، Kafka Streams لا يدعم Apache Beam لأنه كان سيتطلب太多的 قيود تصميمية.
تبني السوق لFrameworks تنسيق الجداول
أولاً، ما زلنا في مراحل مبكرة. نحن ما زلنا في مستوى استدعاء الابتكار فيما يتعلق بدورة Hype Cycle لـ Gartner، قادمين إلى قمة التوقعات المzeritaة. معظم المنظمات ما زالت تقوم بتقييم ولكنها لم تتبن تنسيقات الجداول هذه في الإنتاج عبر المنظمة بعد.
العودة إلى الماضي: حرب الصناديق بين Kubernetes و Mesosphere و Cloud Foundry
يذكرني الجدل حول Apache Iceberg بحرب الصناديق قبل بضع سنوات. يشير مصطلح “حرب الصناديق” إلى المنافسة والتنافس بين تقنيات و منصات الصناديق المختلفة في مجال تطوير البرمجيات و的基础ية<Technical infrastructure.
كان هناك ثلاث تقنيات متنافسة وهي Kubernetes، و Mesosphere، و Cloud Foundry. إليك ما حدث:

Cloud Foundry و Mesosphere كانا من الأوائل، ولكن Kubernetes فاز بالمعركة. لماذا؟ لم أفهم أبداً جميع التفاصيل التقنية والفروق. في النهاية، إذا كانت الإطارتان الثلاثة متشابهة للغاية، فهي تتعلق بـ:
- تبني المجتمع
- الوقت المناسب لإطلاق الميزات
- التسويق الجيد
- الحظ
- وأحد العوامل الأخرى
لكن من الجيد أن تكون هناك إطار عمل مفتوح المصدر واحد ي dominante لإنشاء الحلول و نماذج الأعمال بدلاً من ثلاثة إطار عمل تنافسية.
الحاضر: حروب تنسيقات الجداول لـ Apache Iceberg مقابل Hudi مقابل Delta Lake
بالتأكيد، Google Trends ليس دليلاً إحصائياً أو بحثاً معقداً. لكنني استخدمته كثيراً في الماضي كأداة بديهية، بسيطة، مجانية لتحليل الاتجاهات السوقية. لذا، استخدمت هذه الأداة أيضًا لرؤية ما إذا كانت عمليات البحث على Google تتطابق مع تجربتي الشخصية في تبني السوقلـ Apache Iceberg، و Hudi و Delta Lake (Apache XTable صغير جدًا حتى الآن ليضاف):
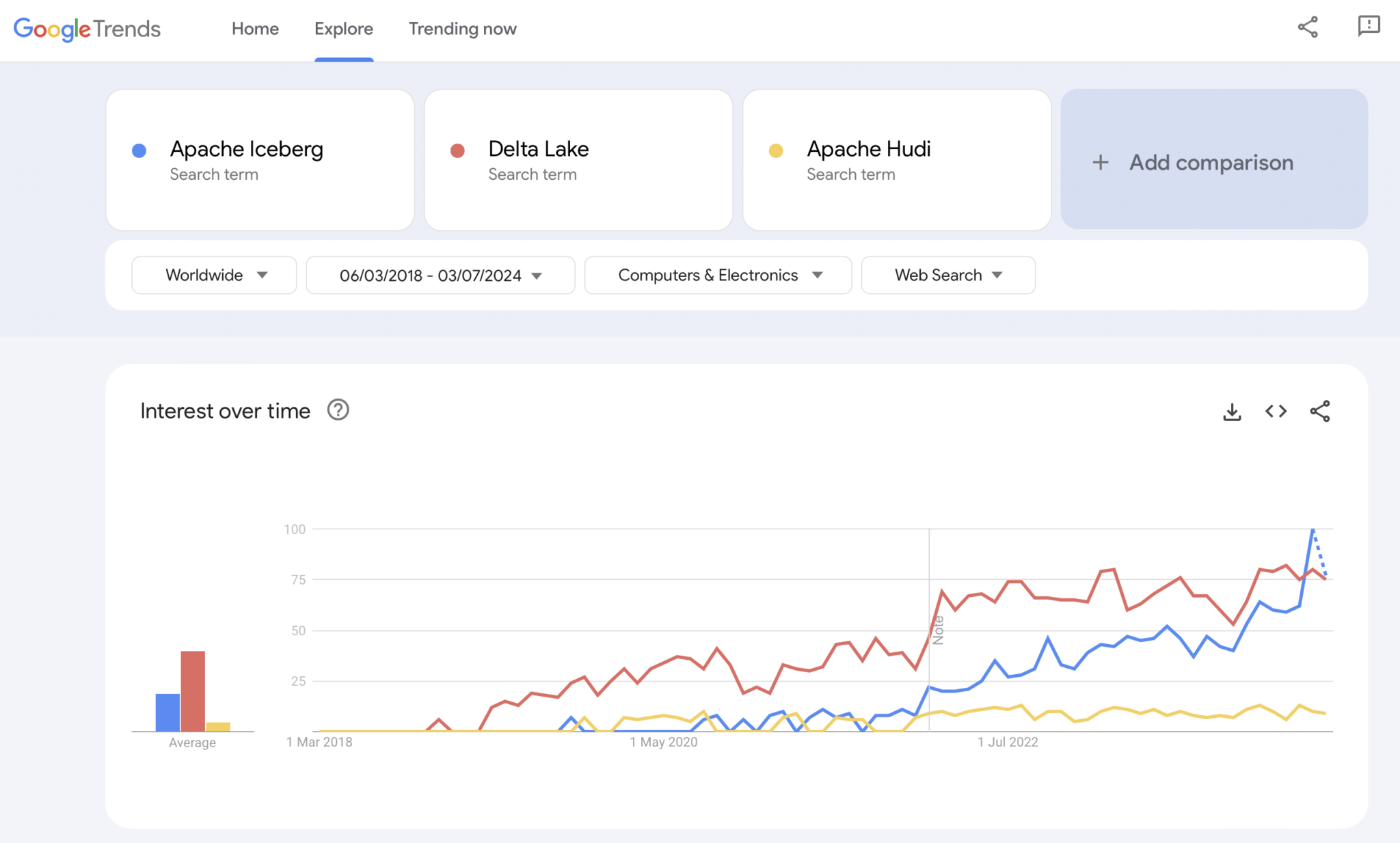
نلاحظ بالتأكيد نفس النمط الذي أظهرته حروب الحاويات قبل بضع سنوات. لا أعلم إلى أين ستذهب الأمور. وإذا فازت تكنولوجيا واحدة، أو إذا تميزت الإطار العمل بشكل كافٍ ليثبت أن لا يوجد سلاح سحري، سيظهر لنا المستقبل ذلك.
رأيي الشخصي؟ أعتقد أن Apache Iceberg سيحقق الفوز في السباق. لماذا؟ لا أستطيع الجدال بأي أسباب تقنية. أنا فقط ألاحظ أن العديد من العملاء عبر جميع الصناعات يتحدثون عنه أكثر وأكثر. و المزيد والمزيد من الموردين يبدأون بدعمه. سنرى. في الواقع، أنا لا أهتم بمن يفوز. ومع ذلك، بنفس الطريقة التي كانت في حروب الحاويات، أعتقد أنه من الجيد أن يكون هناك معيار واحد ويتميز الموردون بميزات حوله، مثلما هو الحال مع Kubernetes.
لكن بمعايرة هذا، دعونا نستعرض الاستراتيجية الحالية لمنصات البيانات ومقدمي الخدمات السحابية بشأن دعم تنسيقات الجداول في منصاتهم وخدماتهم السحابية.
استراتيجيات منصات البيانات ومقدمي الخدمات السحابية لـ Apache Iceberg
لن أقوم بأي توقع في هذا القسم. تطور إطار عمل تنسيقات الجداول يتحرك بسرعة، وتتغير استراتيجيات الموردين بسرعة. يرجى الرجوع إلى مواقع الموردين للحصول على أحدث المعلومات. لكن هنا الحالة الراهنة بشأن استراتيجيات منصات البيانات ومقدمي الخدمات السحابية المتعلقة بدعم وتكامل Apache Iceberg.
- Snoflake:
- يدعم Apache Iceberg منذ فترة طويلة بالفعل
- يقوم بإضافة تكامل أفضل وميزات جديدة بانتظام
- خيارات التخزين الداخلي والخارجي (مع تنازلات) مثل تخزين Snoflake أو Amazon S3
- أعلن عن Polaris، تنفيذ سجل مفتوح المصدر لـ Iceberg، مع التزام بدعم التكامل ثنائي الاتجاه المجتمعي، وبدون تحيز للمورد
- داتابريكس:
- يركز على تنسيق Delta Lake كتنسيق الجدول و(الآن مفتوح المصدر) Unity كدليل
- اشترت Tabular، الشركة الرائدة خلف Apache Iceberg
- استراتيجية مستقبلية غير واضحة لدعم واجهة Iceberg المفتوحة (في كلا الاتجاهين) أم فقط لتغذية البيانات إلى منصة Lakehouse الخاصة به وتقنيات مثل Delta Lake و Unity Catalog
- كونفليونت:
- يدمج Apache Iceberg كمواطن من الدرجة الأولى في منصة تدفق البيانات الخاصة به (المنتج يسمى Tableflow)
- يحوّل موضوع Kafka ووصف النموذج المرتبط به (أي عقدة البيانات) إلى جدول Iceberg
- تكامل ثنائي الاتجاه بين الأحمال التشغيلية والأحمال التحليلية
- تحليلات مع خادم Flink المدمج بدون خادم موحد API لل批次 والتدفق أو مشاركة البيانات مع محركات تحليلية ثالثة مثل Snowflake، Databricks، أو Amazon Athena
- المزيد من منصات البيانات ومحركات التحليلات المفتوحة المصدر:
- قائمة التكنولوجيا和服务 السحابية التي تدعم Iceberg تنمو كل شهر
- بعض الأمثلة: Apache Spark، Apache Flink، ClickHouse، Dremio، Starburst باستخدام Trino (سابقاً PrestoSQL)، Cloudera باستخدام Impala، Imply باستخدام Apache Druid، Fivetran
- مقدمو خدمات السحابة (AWS، Azure، Google Cloud، Alibaba):
- strategies و integrations مختلفة، ولكن جميع مقدمي الخدمات السحابية يزيدون من دعم Iceberg عبر خدماتهم هذه الأيام، على سبيل المثال:
- التخزين المادي: Amazon S3، Azure Data Lake Storage (ALDS)، Google Cloud Storage
- المجلدات: محددة للسحابة مثل AWS Glue Catalog أو حيادية المورد مثل Project Nessie أو Hive Catalog
- التحليلات: Amazon Athena، Azure Synapse Analytics، Microsoft Fabric، Google BigQuery
- strategies و integrations مختلفة، ولكن جميع مقدمي الخدمات السحابية يزيدون من دعم Iceberg عبر خدماتهم هذه الأيام، على سبيل المثال:
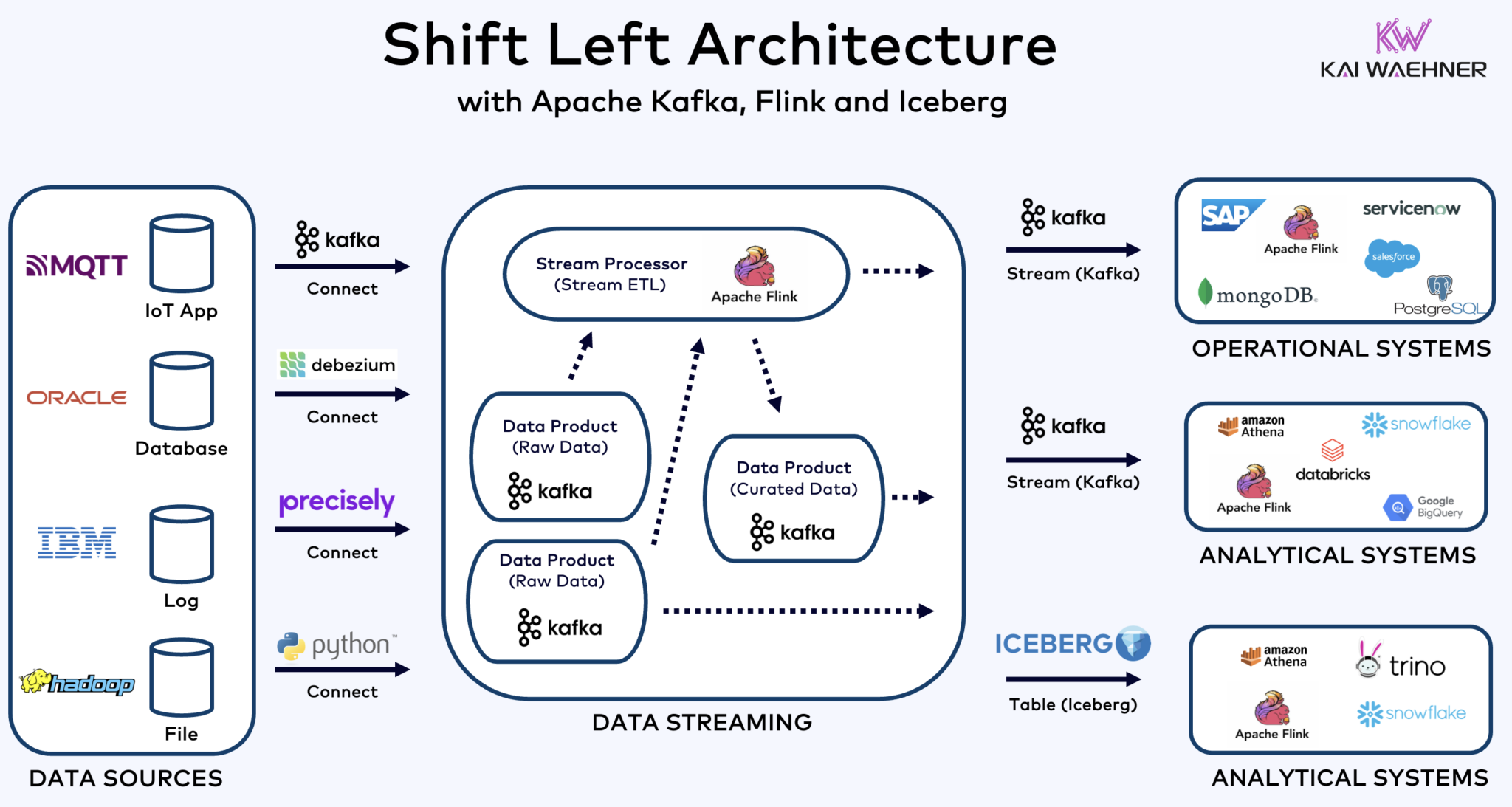
هندسة Shift Left مع Kafka، Flink، و Iceberg لتنظيم الأحمال التشغيلية والتحليلية
هندسة Shift Left تقرب معالجة البيانات من مصدر البيانات، باستخدام تكنولوجيا تدفق البيانات الفعلية مثل Apache Kafka و Flink لمعالجة البيانات أثناء حركتها مباشرة بعد استقبالها. تقلل هذه الطريقة من التأخير وتحسن توافق البيانات وجودة البيانات.
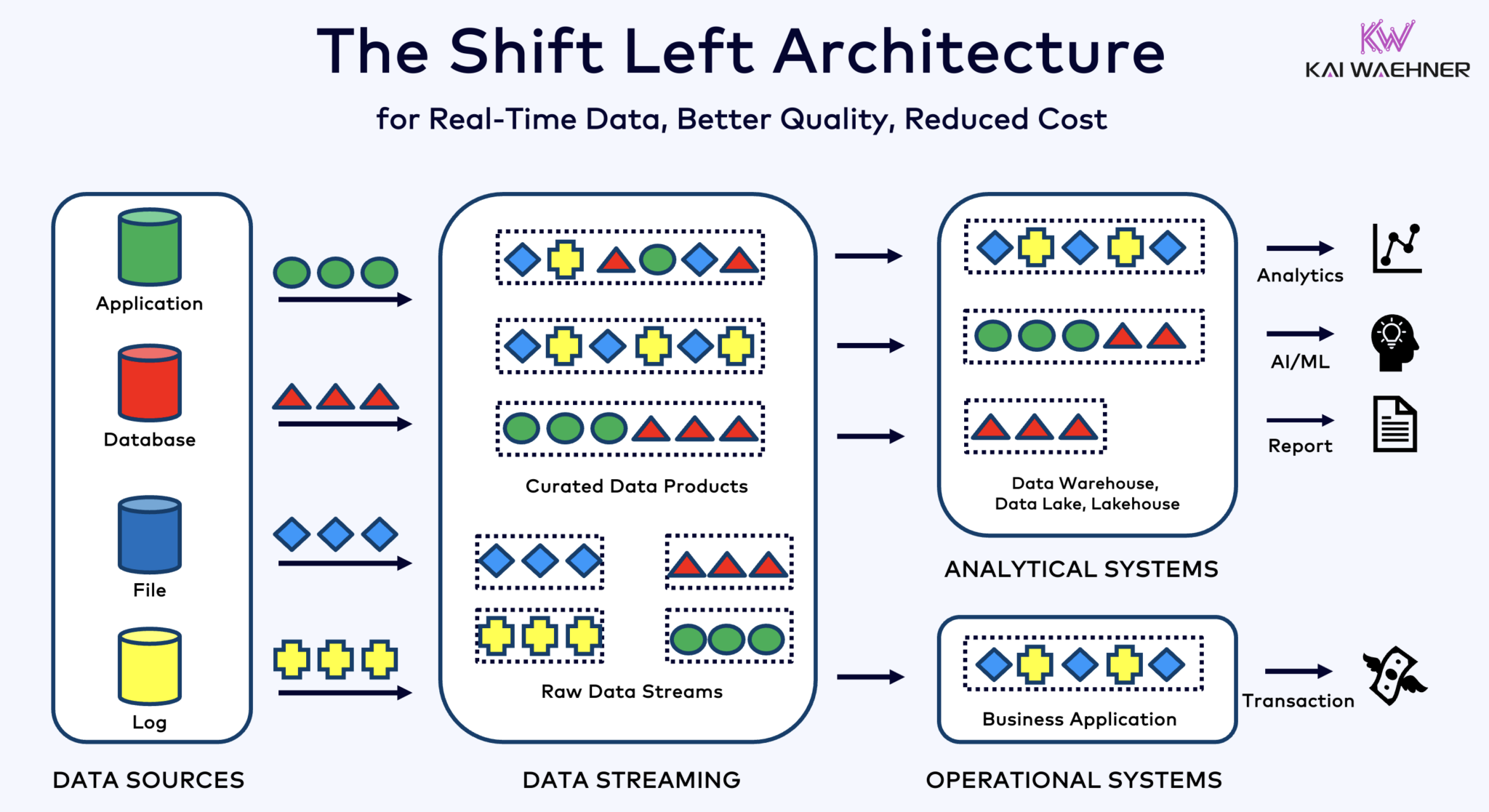
على عكس ETL و ELT، اللذين يتضمنان معالجة بال批量 مع البيانات المخزنة في راحة، تهندسة Shift Left تمكن من التقاط وتحويل البيانات الفعلية. تتوافق مع مفهوم zero-ETL بجعل البيانات قابلة للاستخدام فورًا. ولكن على عكس zero-ETL، نقل معالجة البيانات إلى الجانب الأيسر من هندسة المؤسسة ي避开了复杂且难以维护 بنية spaghettie مع العديد من الاتصالات النقطية.
الهندسة النقالة اليسرى تقلل أيضًا من الحاجة إلى التحويل العكسي ETL بضمان أن تكون البيانات قابلة للتنفيذ في الوقت الفعلي لجميع الأنظمة التشغيلية والتحليلية. بشكل عام، تعزز هذه الهندسة نقاء البيانات، وتقلل التكاليف، وتسرع وقت الوصول إلى السوق للتطبيقات المستندة إلى البيانات. اكتشف المزيد عن هذا المفهوم في منشور بلدي حول “هندسة النقالة اليسرى.”
Apache Iceberg كتنسيق جدول مفتوح وقاعدة بيانات للتبادل السلس للبيانات عبر محركات التحليل
ي引入 تنسيق الجدول المفتوح وقاعدة البيانات فوائد هائلة في هندسة المؤسسة:
- التوافق
- حرية اختيار محركات التحليل
- سرعة أكبر في الوصول إلى السوق
- تقليل التكاليف
يبدو أن Apache Iceberg يصبح المعيار الافتراضي عبر البائعين ومقدمي الخدمات السحابية. ومع ذلك، لا يزال في مراحل مبكرة وتتنافس التكنولوجيات المنافسة والمنقولة مثل Apache Hudi، Apache Paimon، Delta Lake، وApache XTable في تحقيق الزخم أيضًا.
الجبل الجليدي وغيره من صيغ الجداول المفتوحة ليست فقط فوزًا كبيرًا لتخزين 单一 and التكامل مع العديد من منصات التحليل والبيانات والأتمتة/التعلم الآلي مثل Snowflake، Databricks، Google BigQuery، et al، بل også للـ ال統籌 للأحمال التشغيلية والتحليلية باستخدام تدفق البيانات مع التكنولوجيا مثل Apache Kafka و Flink. بنية Shift left تمثل فائدة كبيرة لخفض الجهد، تحسين جودة البيانات والتناسق، وتفعيل التطبيقات والرؤى الفورية بدلاً من معالجة الدفع.
أخيرًا، إذا كنت لا تزال تتساءل عن الـ الفرق بين تدفق البيانات ومستودعات البيانات ( وكيف يكمّلون بعضهم البعض)، شاهد هذا الفيديو من عشر دقائق:
ما هي استراتيجية صيغة الجداول لديك؟ أي تكنولوجيا وخدمات السحابة التي تقوم بالربط؟ دعونا نتواصل على LinkedIn ونتحدث عن ذلك!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming